问题
【问题一】 如何使用union_categoricals方法?它的作用是什么?
使用union_categoricals需要保证两个categories必须是相同的dtype。作用是把两个union_categoricals连接在一起
【问题二】 利用concat方法将两个序列纵向拼接,它的结果一定是分类变量吗?什么情况下不是?
不一定
s = pd.Series(["a", "d", "c", "a"]).astype('category')
s1 = pd.Series(['1', '2'], dtype='category')
pd.concat([s, s1])
0 a
1 d
2 c
3 a
0 1
1 2
dtype: object
【问题三】 当使用groupby方法或者value_counts方法时,分类变量的统计结果和普通变量有什么区别?
分类变量会转成对应的普通变量
【问题四】 下面的代码说明了Series创建分类变量的什么“缺陷”?如何避免?(提示:使用Series中的copy参数)
cat = pd.Categorical([1, 2, 3, 10], categories=[1, 2, 3, 4, 10])
s = pd.Series(cat, name="cat")
cat
[1, 2, 3, 10]
Categories (5, int64): [1, 2, 3, 4, 10]
s.iloc[0:2] = 10
cat
[10, 10, 3, 10]
Categories (5, int64): [1, 2, 3, 4, 10]
使用cat = pd.Categorical进行Series创建分类变量,“缺陷”是如果对Series进行操作的话,就改变到cat的值,避免这种情况需要用到Series的copy参数
练习
【练习一】 现继续使用第四章中的地震数据集,请解决以下问题:
(a)现在将深度分为七个等级:[0,5,10,15,20,30,50,np.inf],请以深度等级Ⅰ,Ⅱ,Ⅲ,Ⅳ,Ⅴ,Ⅵ,Ⅶ为索引并按照由浅到深的顺序进行排序。
df = pd.read_csv('../data/Earthquake.csv')
df.head()

df['深度'] = pd.cut(df['深度'], bins=[0,5,10,15,20,30,50,np.inf], right=False, labels=['I', 'II', 'III', 'Ⅳ', 'Ⅴ', 'Ⅵ', 'Ⅶ'])
df = df.set_index('深度').sort_index()
df

(b)在(a)的基础上,将烈度分为4个等级:[0,3,4,5,np.inf],依次对南部地区的深度和烈度等级建立多级索引排序。
df['烈度'] = pd.cut(df['烈度'], bins=[0,3,4,5,np.inf], right=False)
df = df.reset_index().set_index(['深度', '烈度']).sort_index()
df_south = df.loc[df['方向']=='south']
df_south

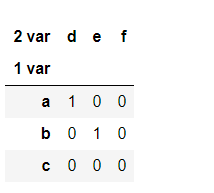
【练习二】 对于分类变量而言,调用第4章中的变形函数会出现一个BUG(目前的版本下还未修复):例如对于crosstab函数,按照官方文档的说法,即使没有出现的变量也会在变形后的汇总结果中出现,但事实上并不是这样,比如下面的例子就缺少了原本应该出现的行’c’和列’f’。基于这一问题,请尝试设计my_crosstab函数,在功能上能够返回正确的结果。¶
# 交叉表是一种特殊的透视表,典型的用途如分组统计
foo = pd.Categorical(['a', 'b'], categories=['a', 'b', 'c'])
bar = pd.Categorical(['d', 'e'], categories=['d', 'e', 'f'])
pd.crosstab(index=foo, columns=bar)
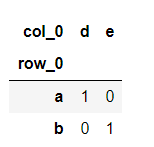
def my_crosstab(foo, bar):
num = len(foo)
s1 = list(foo.categories.union(set(foo)))
s2 = list(bar.categories.union(set(bar)))
# 初始化一个全0的df
df = pd.DataFrame({
i:[0]*len(s1) for i in s2}, index=s1).rename_axis('1 var', axis=0)
for i in range(num):
df.loc[foo[i],bar[i]] += 1
return df.rename_axis('2 var', axis=1)
my_crosstab(foo, bar)