最近对这个项目进行了优化完善,记录了本次优化的过程
详情页景点文字显示
用{ { mus.music_name }}代替了字符串
新建site页做改动
author存储Tzxkd位置副标题
address存储简介
Modern Chinese city known for its skyscrapers, the Bund promenade, art deco buildings & shopping.
China's capital & home to major sites such as the Forbidden City palace complex & Tiananmen Square.
景点推荐动态
推荐根据序号order
新建top_places表
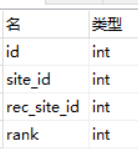
建立新model
| class TopPlaces( db.Model): """评论点赞""" __tablename__ = "top_places" id = db.Column("id", db.Integer, primary_key=True) # 评论编号 site_id = db.Column("site_id", db.Integer, nullable=False) # 用户编号 rec_site_id = db.Column("rec_site_id", db.Integer, nullable=False) # 用户编号 rank = db.Column("rank", db.Integer) |
写view,运行,报错:
| sqlalchemy.exc.ArgumentError: Object <app.models.TopPlaces object at 0x000001C791FBF188> is not legal as a SQL literal value |
| File "D:\anacondaProject\music-website-flask\app\home\views.py", line 443, in play top_place = Music.query.filter(Music.music_id == place_id) |
获取的方式不对,通过主键的值查询时直接使用:
| cls.query.get(值) User.query.get(10) |
第一次查出的是对象,要遍历从对象中取值
| top_places = [] # 根据user.id,查出用户点赞过的TopPlaces对象 top_places_list = TopPlaces.query.filter(TopPlaces.site_id == musicid).order_by(TopPlaces.rank.asc()).all() # 遍历TopPlaces所有对象,查出点赞评论的id top_place_ids = [top_place.rec_site_id for top_place in top_places_list] for place_id in top_place_ids: print("place_id:%d",place_id) top_place = Music.query.get(place_id) top_places.append(top_place) |
推荐部分使用模型结果
| @home.route('/map', methods=['POST']) def userinput(): app = current_app._get_current_object() # data = request.data data = str(request.data, encoding='utf-8') # print(data)接收的center place ms = app.where2go.most_similar(data) top_places_json = app.where2go.get_top_places_json(ms) app.result['top_places'] = top_places_json return json.dumps(app.result) |
| model_output = JSON.parse(data) var center_location = model_output['center_location']; var geojson = model_output['top_places']; |
传回一个dict
最好的方法是直接调用model中的函数,因为进入页面从后台查数据,不需要前台ajax
Ms:
| def most_similar(self, input, topn=40): ''' use the trained word2vec model to give most similar recommendations to the input
input = search string in the format of place/char + place/char -... output = top recommendations in json format ''' |
使用ms结果:
| for n, entry in enumerate(ms): place, sim = entry # Check if the recommendation is a geo location. if place in self.geotag_imglink_wikiurl: |
遍历根据place查询景点,判空
if not comment_like:
模型推荐view:
| top_places = [] num_show = 0 max_markers = 1 app = current_app._get_current_object() ms = app.where2go.most_similar(music.music_name) for n, entry in enumerate(ms): place_name, sim = entry # Check if the recommendation is a geo location. place = Music.query.filter( Music.music_name.ilike('%' + place_name + '%') ).first() if place: # if place in self.geotag_imglink_wikiurl: top_places.append(place) num_show += 1 if num_show == max_markers: break |
好像成功了,因为数据库中添加的详细介绍信息较少,第一个能查询到的还是和原来一样
这个做的时候可害怕了,纠结了好久,结果一运行一个bug也没报,太顺利了。(二营长,你他娘的意大利炮呢)
图片link索引重新生成
图片地址存储在:
geotag_imglink_wikiurl[place]['img_path']
'data/pickles/geo_imglink_wikiurl.pkl'
查找模型运行日志得(还好记了,不然脑壳都忘光):
scrap_wikivoyage_banners.py全部运行完在D:\anacondaProject\where2go\data生成了一个geotag_imglink_wikibanner.pkl
重新生成模型过程中需要重点代码:
| place = place.replace('/', '_') # REPLACE '/' with '_' BECAUSE IT CREATES A DIRECTORY |
重写图片文件名索引:
| def make_local_img_url(self, place): ''' input = place output = return the default values for img_path and wiki_url ''' wiki_url = 'https://en.wikivoyage.org/wiki/%s' % place if os.path.exists('../../webapp/static/banners/%s.png' % place): img_path = 'static/banners/'+place+'.png' print 'place %s,' % place else: place = place.replace('/', '_') # REPLACE '/' with '_' BECAUSE IT CREATES A DIRECTORY if os.path.exists('../../webapp/static/banners/%s.png' % place): img_path = 'static/banners/'+place+'.png' print 'place %s,' % place else: return self.make_default_img_url(place) return img_path, wiki_url |
页面显示没有改变,查看pikle的包含地名:确定已经包含了
geotag_imglink_wikiurl[place]['img_path']读取的也依然是default
可以看到pickle文件中也是正常的:
| (S'-58.56670000' tRp112087 ssS'guangzhou' p112088 (dp112089 g4 S'static/banners/guangzhou.png' p112090 sg6 S'https://en.wikivoyage.org/wiki/guangzhou' |
看到源码中model保存了自己:
| with open('../../data/pickles/where2go_model.pkl', 'wb') as f: cPickle.dump(where2go, f) |
在app.py中也有:
| return pkl.load(open('../data/pickles/where2go_model.pkl', 'rb')) |
有可能保存了之后就没有再进行读取
所以重新运行了一遍where2go_model.py
更新成功
推荐处图片位置删除or加上改好的索引
原先生成时使用的js:
| var portfolio_html = '<div class="portfolio-item"><img src='+image+' class="img-responsive" alt=""><div class="portfolio-caption"><a target="_blank" class="popup" href="' + wiki_url + '"><h4>'+rank+'. '+title+'</h4></div></div>'; |
| var marker = e.layer, feature = marker.feature; //路径 <link rel="shortcut icon" href="{ { url_for('static',filename='base/images/logo.png') }}"> // Create custom popup content var popupContent = '<a target="_blank" class="popup" href="' + feature.properties.url + '">' + '<div class=crop><img src="http://q7ourhxfp.bkt.clouddn.com' + feature.properties.image + '" height/></div><div class=text-center style="padding:15px 0 0 0"><font size="5">' + feature.properties.title + '</font></div></a>'; |
这里设计到之前一直解决不了的url_for('static'动态生成的html字符串的src中的问题
参考:http://codingdict.com/questions/6062
| 原意(但写法错): <img src=" { { url_for('static', filename='uploads/users/{ { song['artistName'] }}/{ { song['pathToCover'] }}') }}"> |
| 建议: <img src="{ { url_for('static', filename='uploads/users/') }} { { song['artistName'] }}/{ { song['pathToCover'] }}"> |
考虑参考评论把动态生成的改成静态包含的,通过是否查询变量控制css和py是否显示
View
考虑主页与详情页的不同,这里不是进页面就显示,而是查询后显示,可参考评论中的新增
新增评论评论view-news_comment:
也没有重新渲染页面,但使用jsonify传递参数
| return jsonify(errno="0", errmsg="评论成功", data=comment.to_dict()) |
Jsonify与Python 自带的 json 模块相类似,暂时不多做关注
html
列表放置位置为:
| <div class="container" id ="portfolio"> </div> |
原先在html中对data参数的使用:完全作为ajax的返回值:
| 'success': function (data) { model_output = JSON.parse(data) |
显示新增评论的操作也是在js中进行的:
| if (comment.user.avatar_url) { comment_html += '<img src="' + comment.user.avatar_url + '" alt="用户图标">' } else { comment_html += '<img src="../../static/news/images/person01.png" alt="用户图标">' } |
这里使用了静态相对地址
首页json:
| var portfolio_html = '<div class="portfolio-item"><img src="../../'+image +'" class="img-responsive" alt=""><div class="portfolio-caption"><a target="_blank" class="popup" href="' + wiki_url + '"><h4>'+rank+'. '+title+'</h4></div></div>'; |
也使用相对地址然后成功了,之前直接static或urlfor的方法都不好用
去除图片拉伸
标签上的图片显示得有点扭曲,显示方式改成:剪裁适应
参考:https://segmentfault.com/q/1010000018971940
object-fit似乎是被人忽视的一个CSS3属性。因为存在兼容性,所以没有background-size好用,但是由于某种情况,你不得不用img标签来引入图片,这时候用object-fit是很好的选择。
我们给上图所有img都统一加上object-fit:cover;