说出来不怕丢人,我一直都不理解。
可能是一直都没静下心来研究,所以一直都是糊里糊涂的。
这都到ADSO了,我也还是没完全理解。
所谓欲速则不达。反正快也快不了,不妨慢慢来看吧。
DSO里都有啥

DSO它是作为一个表来看的,首先来理解下两个单词:fields是字段,figure是数值。
我把它里面的所有字段分为,关键代码字段,数据字段,关键值字段。(就我自己这样分的,实际上现在的分法直接是key和数据字段,把关键值也包在数据字段里。)
在数据字段之外,还有些不想加到数据字段的转换里面,但是又想要以后在报表中用到某些字段来过滤报表,那就添加导航属性吧。在特性的属性转换里面给值。
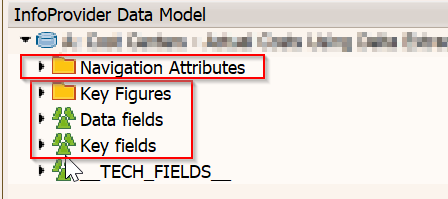
(是的,导航属性本身还可以拥有导航属性,因为导航属性也是一个特性,只是添加为另一个特性的属性。它本身也可以有属性的。但这里我们不支持去添加导航属性的导航属性的。)
好,接上面,也就是说,我DSO里有一个成本中心的数据字段,转换连接的是数据源的成本中心字段。
现在我觉得这个DSO的数据不够充分,我还想要公司代码。但是我DSO的数据源没有公司代码。
好在成本中心主数据有,成本中心作为一个拥有主数据的特性,它有公司代码的属性。现在我把它的公司代码作为它的导航属性。这样就等于说,我虽然DSO里没有直接给你拉数据,但是我的数据字段里的成本中心有你这个公司代码属性。我也可以用这个公司代码的。最重要的是,我可以用这个公司代码来导航,来过滤或者下钻。这才是导航属性的作用。因为,其实只要我DSO里的数据有属性,我都可以展示它的属性,只不过导航属性是可以用来过滤下钻的。
知道了这些数据,那接下来。还要知道,关键代码字段是唯一性的,也就是这个DSO的表中,所有关键代码字段的组合值,那必须是唯一的。这就导致了,除了关键代码之外的数据字段,是会被覆盖的。
也就是假设这个DSO的关键代码是班级和学号,数据字段是姓名,值字段是分数。
那么只要班级和学号相同,后一条的姓名不同的记录会覆盖掉前一条的姓名。
至于关键值,可以是覆盖,可以是累加,也可以是不进行更改。
现实的例子是,由于ERP系统中有些订单的运达方,交货日期,状态这些非数值会经常变化,所以除了订单号等等代码之外,需要对数据字段进行覆盖。
DSO有哪几类
这里有点错综复杂了,标准的是我们最经常用到的。
现在的Model啥的是这样的:
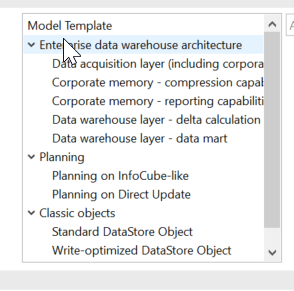
也就是你可以直接选满足你的模型,它会自动给你选择合适的DSO类型。

从左边的建模属性,就能看到,换汤不换药。搞这么多类型,看的我头都晕了。
那我们还是来看看。
左边:
activate data: 根据更新逻辑,把入栈表内容更新到激活表(标准DSO需要)
write change log:增量更新需要的,数据保存在这里
keep inbound data, extract from inbound table: 保存new表,从这个new表抽数据,但是它在激活数据下,,,我不知道啥意思,也没选过。
unique data records: 这个是唯一数据记录,意思是你的信息源只提供唯一记录,这样设置提高性能了。就是说如果我DSO已经有了你这个记录,我绝不会再加载第二次了。否则会出现错误。
**snapshot support:**支持快照。。。允许对全量更新的源的增量抽取。。。我不知道啥意思。。
特殊类型:
direct update: 没有new表了,直接通过API更新.我见过的更新方式就是直接建一个转换和DTP从文本文档更新,就不用激活。或者就是建一个报表,从报表里写值到DSO里。。
all characteristics are key, reporting on union of inbound and active table.:这个就是和infocube一个意思了。所有特性都是主键,只有你有附加的增量,才加载你。
planning mode: 跟直接更新经常一起选,不懂。
inventory:支持存货,不懂。。
标准
不按照右边的模型选,那我直接勾,也行。
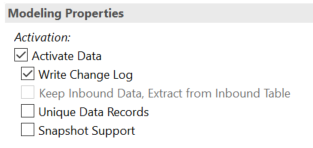
咱都知道,标准DSO会有三张表:active table/change log table/new table.
增量呢,就是通过更改日志来实现的。因为你日志里,会有个字段叫:RECORDMODE记录模式

这个字段在每个请求的每个包的每条数据记录下都有,一般有更改都会成对出现。。。有前像后像
N的是新的。不成对。。。
如果有空的是后像,那会对应一个X前像,也就是说这条记录有更改。
然后就靠这个来做后续增量更新。
咋做呢,数据先到new table中的,激活后做的更改到change log表里。激活的数据到active表里。如果是关键值覆盖,那就会在激活的时候,在active表把旧数据删除只保留新数据,在changelog表会有一个对冲,只保留最新的数据。对冲的那条应该是X前像,然后新的那条是空的后像。

验证如下:
new table加了第二条。未激活时是一条。

active table里还没激活这条值是45的。

change log也还是这样的:

我先来激活一下:
new table激活后就空了。
看active table:
之前那条23的值被清空了。新的是 空的 recordmode,是后像。所以在change log里面会有对冲的一条-23的前像。
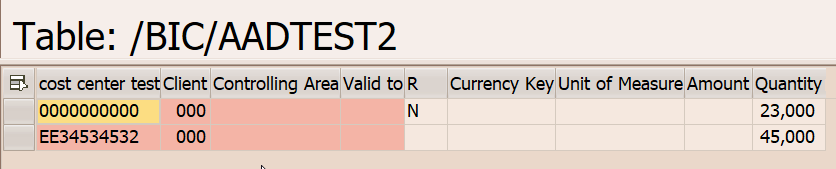
我们去change log去看:
是有一个X的前像和N的对冲掉了,最后一条空是后像。

技术上可以将0RECORDMODE改成D来删除数据。
这里提一嘴infocube和DSO的区别,Info Cube它是个多维星型模型。也就是说它是表示成多个表的。不是像DSO的一张明细的包含各个维度的表。
info vube包含的表是多个维度表(16)和数据表。维度表的代码组合构成数据表的代码。而且info cube是没有累加的,只能覆盖。特性相同的情况下,关键值只更新到现有数据。所以一般我们不在info cube上处理啥,一般都是汇总级的在这里。不过现在不用鸟。。。
简而言之,DSO负责合并或者协调数据。
同时,在DSO里面还有个分区和索引功能。
按不同的字段分区,或者给经常访问的一些字段集合创建索引。
还有一点就是在激活时生成SID标记,这样在DSO上创建报表的查看速度会更快。不过好像一般不在这个DSO上建报表。因为这样的话,你加载数据到DSO会也更新这个SID,就会耗时很长了。
写优化
不知道。
直接更新

只有active表,下次详细写。