在整理一下整理,后续上传
4.1. Hive sql 执行的顺序与mysql 对比: 24
4.8. Hadoop SecondaryNameNode异常排查 39
- 关系型数据库
- 非关系型数据库
- 数据仓库

Hive 是一个类SQL 能够操作hdfs 数据的数据仓库基础架构
Hive 是一个SQL 的解析引擎,能够将HSQL翻译MR在hadoop 中执行。
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
总结:
Hive 是一个类SQL 能够操作hdfs 数据的数据仓库基础架构
Hive 是一个SQL 的解析引擎,能够将HSQL翻译MR在hadoop 中执行。
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制,简而言之,数据仓库是用来做查询分析的数据库,基本不用来做插入,修改,删除
| 对变项 |
Hive |
数据库软件 |
| 查询语言 |
HQL |
SQL |
| 数据存储 |
HDFS |
Raw Devce or Loal FS |
| 执行器 |
MapReduce |
Executor |
| 数据插入 |
支持批量导入/单条插入 |
支持单条或者批量导入 |
| 数据操作 |
覆盖追加(0.14版本支持行级更新) |
行级更新删除 |
| 处理数据规模 |
大 |
小 |
| 执行延迟 |
高 |
低 |
| 分区 |
支持 |
支持 |
| 索引 |
0.8版本之后加入了索引 |
支持复杂的索引 |
| 扩展性 |
高 |
有限 |
| 数据加载模式 |
读时模式(快) |
写时模式(慢) |
| 应用场景 |
海量数据查询 |
实时查询 |
注意hive读时模式:Hive在加载数据到表中的时候不会校验.
(备注 读模式
数据被加载到数据库的时候,不对其合法性进行校验,只在查询等操作的时候进行校验,特点:加载速度快,适合大数据的加载
写模式
数据被加载到数据库的时候,需对其合法性进行校验,数据库中的数据都是合法的数据,特点:加载速度慢,但是查询速度快。)
写时模式:Mysql数据库插入数据到表的时候会进行校验.
总结:Hive只适合用来做海量离线的数据统计分析,也就是数据仓库。
优点:操作接口采用了类SQL语法,提供快速开发的能力,避免了去写MapReduce;Hive还支持用户自定义函数,用户可以根据自己的需求实现自己的函数。
缺点:Hive查询延迟很严重。
- 数据的离线处理;比如:日志分析,海量结构化数据离线分析…
- Hive的执行延迟比较高,因此hive常用于数据分析的,对实时性要求不高的场合;
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
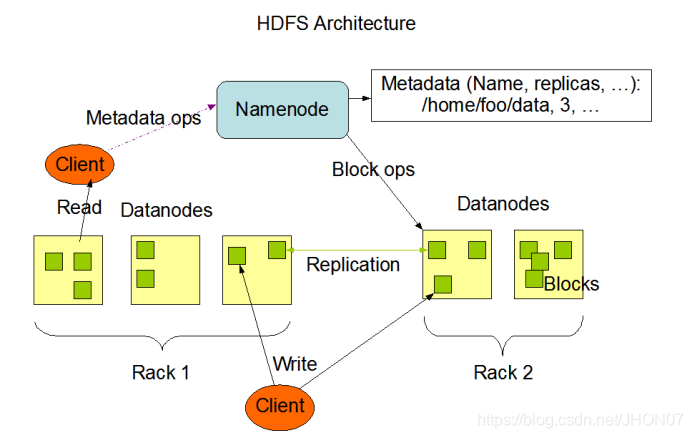
https://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html

参考:http://blog.itpub.net/31537832/viewspace-2155638/
https://blog.csdn.net/oTengYue/article/details/91129850
- Hive是如何将SQL转化为MapReduce任务的,整个编译过程分为六个阶段:
- 1-Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree;
- 2-遍历AST Tree,抽象出查询的基本组成单元QueryBlock;
- 3-遍历QueryBlock,翻译为执行操作树OperatorTree;
- 4-逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量;
- 5-遍历OperatorTree,翻译为MapReduce任务;
- 6-物理层优化器进行MapReduce任务的变换,生成最终的执行计划。



(1)用户接口:CLI(hive shell);JDBC(java访问Hive);WEBUI(浏览器访问Hive)
(2)元数据:MetaStore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段,标的类型(表是否为外部表)、表的数据所在目录。这是数据默认存储在Hive自带的derby数据库中,推荐使用MySQL数据库存储MetaStore。
(3)Hive使用HDFS存储数据(.Hadoop集群):
使用HDFS进行存储数据,使用MapReduce进行计算。
(4)Driver:驱动器
解析器(SQL Parser):将SQL字符串换成抽象语法树AST,对AST进行语法分析,像是表是否存在、字段是否存在、SQL语义是否有误。
编译器(Physical Plan):将AST编译成逻辑执行计划。
优化器(Query Optimizer):将逻辑计划进行优化。
执行器(Execution):把执行计划转换成可以运行的物理计划。对于Hive来说默认就是Mapreduce任务。