深度学习小白,有任何问题请不吝赐教。
卷积神经网络(CNN)
CNN的构成
卷积层
卷积层负责提取图像中的局部特征
卷积层主要有很多个卷积核组成,这些卷积核也叫过滤器,每一个卷积核都代表一种模式或特征,卷积核是有深度的
卷积操作
一个公式
暂时不用看,一会儿回来对照一下
D o u t p u t = D i n p u t − D k e r n e l + 2 ∗ p a d d i n g s t r i d e + 1 D_{output} = \frac{D_{input}-D_{kernel}+2*padding}{stride}+1 Doutput=strideDinput−Dkernel+2∗padding+1
两个操作
局部关联、滑动窗口
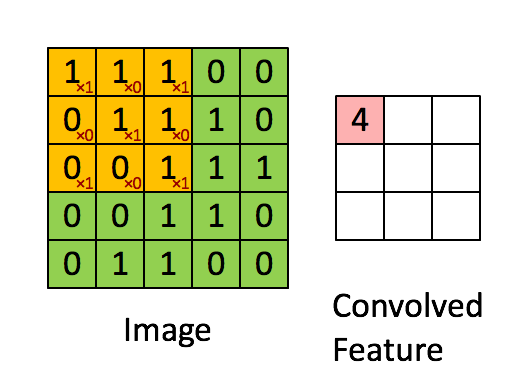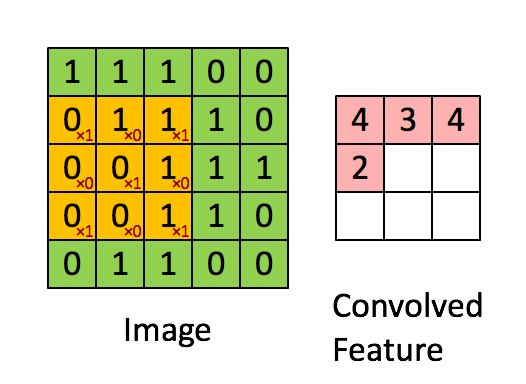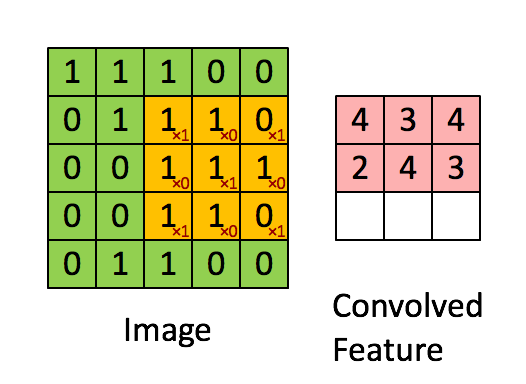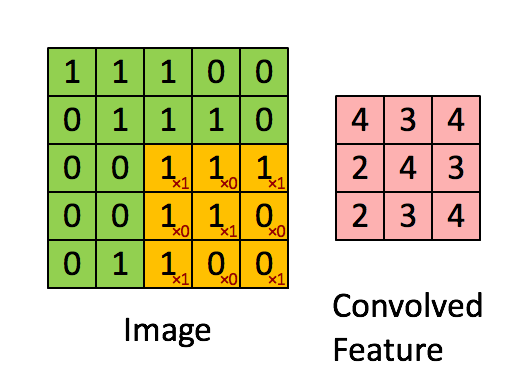
黄色区域代表滑动窗口
假如图片channel维度为3,卷积核的个数为10,那么卷积核的深度亦为3,最终输出的channel维度为卷积核的个数
图片和第一个卷积核在每一个维度都进行上述的运算,得到3个特征图,然后将3张特征图对应位置相加得到最终的特征图。
剩下的每个卷积核与图片进行这样的操作都会得到一张特征图,最终组合到一起得到3x3x10的输出
即5x5x3 卷积 10个3x3x3 = 3x3x10
三种卷积
valid卷积
valid卷积指定padding为0对原图进行下采样,经过valid卷积后图片尺寸减小
full卷积
full卷积指定padding=kernel_size-1对原图进行上采样,经过full卷积后图片尺寸增大
same卷积
same卷积保持特征图尺寸不变。padding,stride需要满足这个公式
n = n − D k e r n e l + 2 ∗ p a d d i n g s t r i d e + 1 n = \frac{n-D_{kernel}+2*padding}{stride}+1 n=striden−Dkernel+2∗padding+1
池化层
池化层用来大幅降低参数量级(降维)
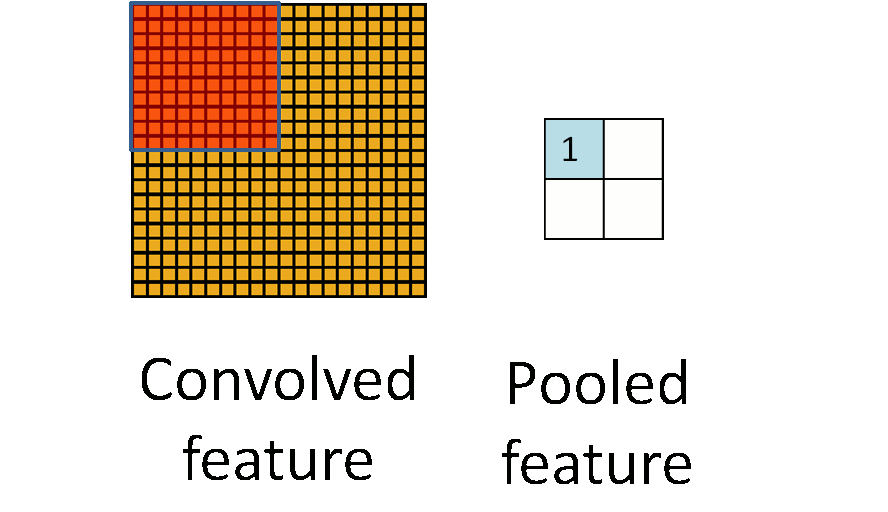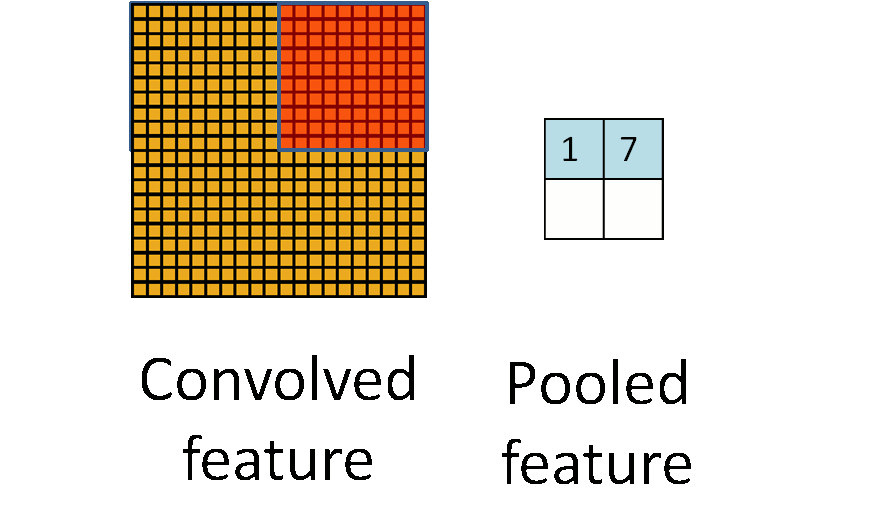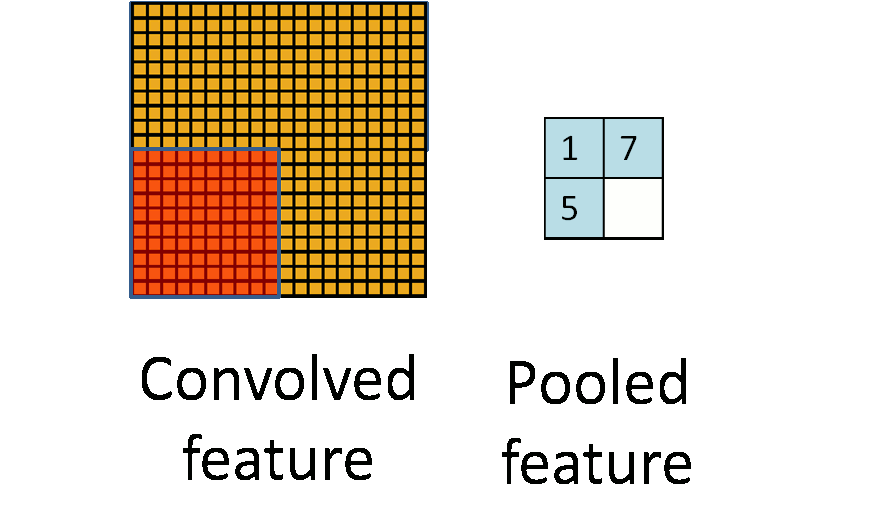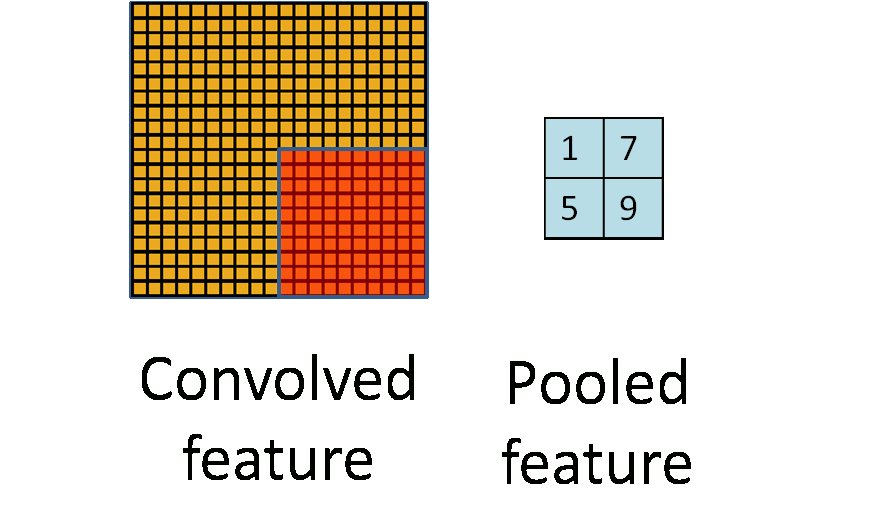
池化操作
池化操作指定一个大小的区域,区域中的所有像素值加起来取平均或者直接返回最大的值
卷积神经网络中降维一般使用maxpooling,后面会讲为什么可以降维,以及为什么使用maxpooling降维
全连接层
全连接层类似传统神经网络的部分,用来输出想要的结果。
结构图
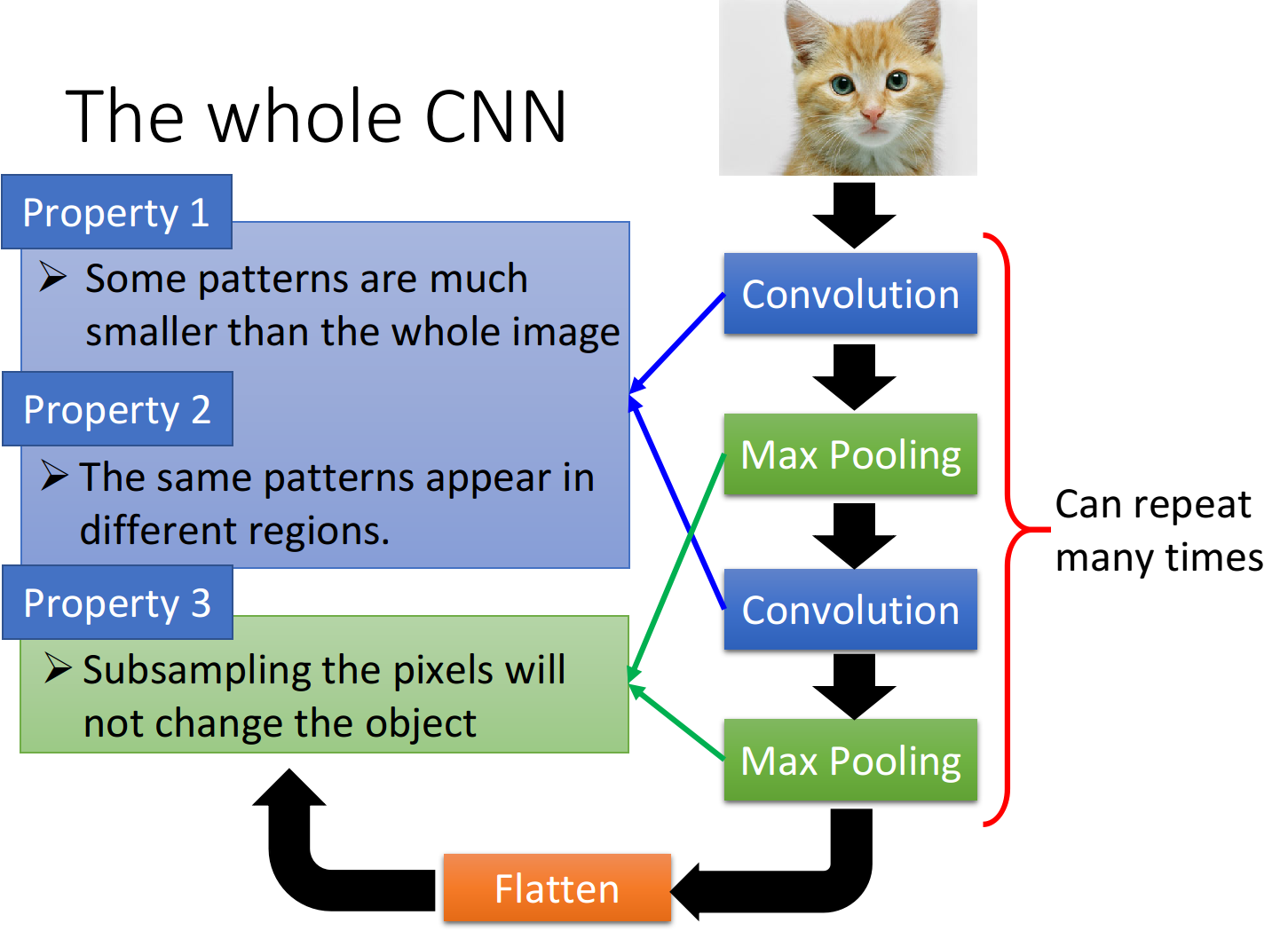
李宏毅深度学习教程课件
CNN和DNN的区别
卷积神经网络和全连接网络的本质区别就是下面两个特性
- 局部感知
- 权值共享
这两个特点是由于输入的特性决定的,但同时这两个特点极大降低了整个网络的参数量
对于一张图片而言,我们常常不需要看整张图片来判断图片上有什么物体,我们只需要一块小的可以代表这个物体的特征区域即可,这是卷积神经网络适用的前提。
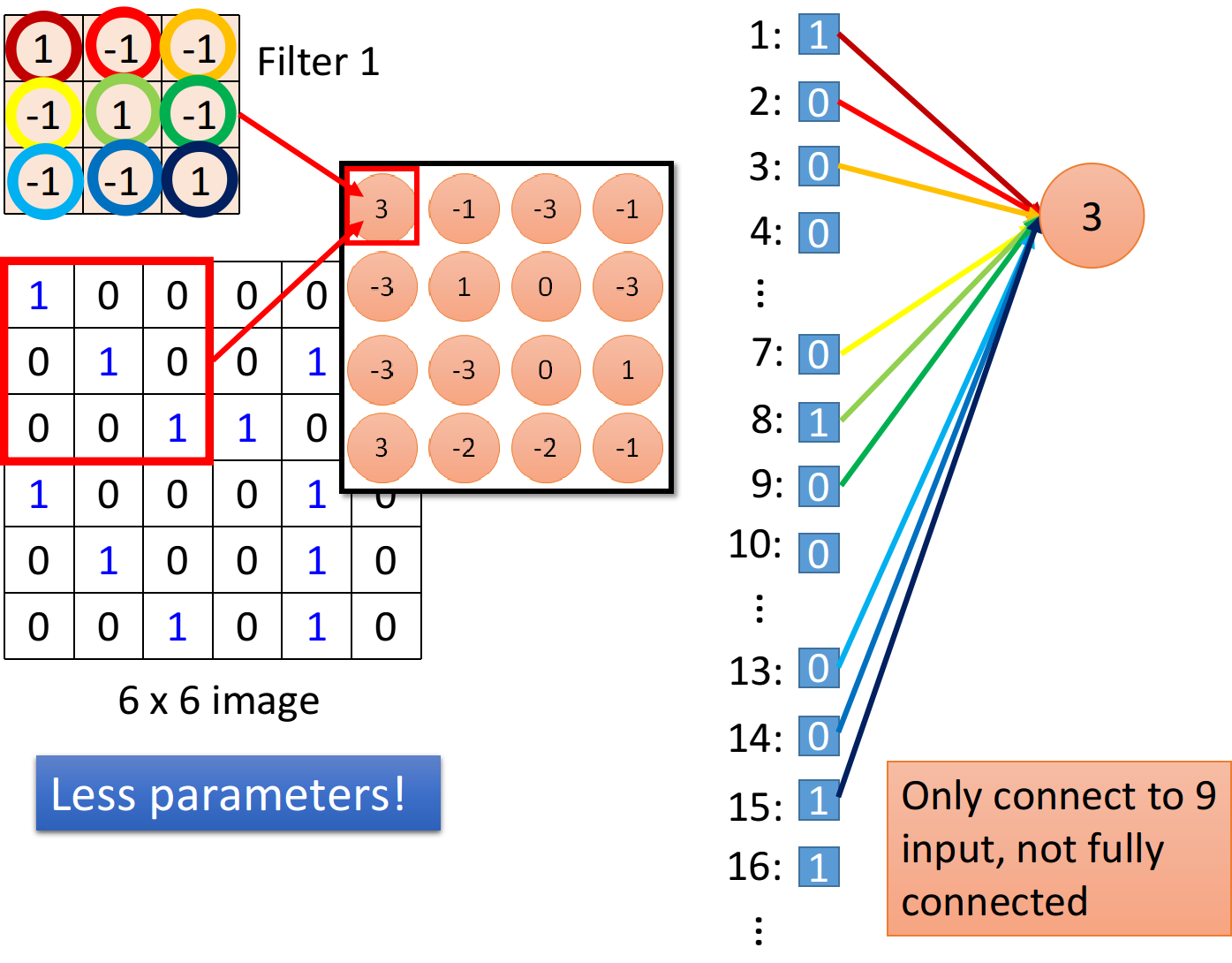
我们另外引入一个概念,叫做感受野
对于DNN来说没有感受野的概念,或者说对于DNN的每个神经元,它的感受野都是全图
对于CNN来说,每个神经元由哪块原图中的区域决定,这块区域就是它的感受野
如下图,对于第一个神经元3来说,image左上角的3x3区域就是它的感受野
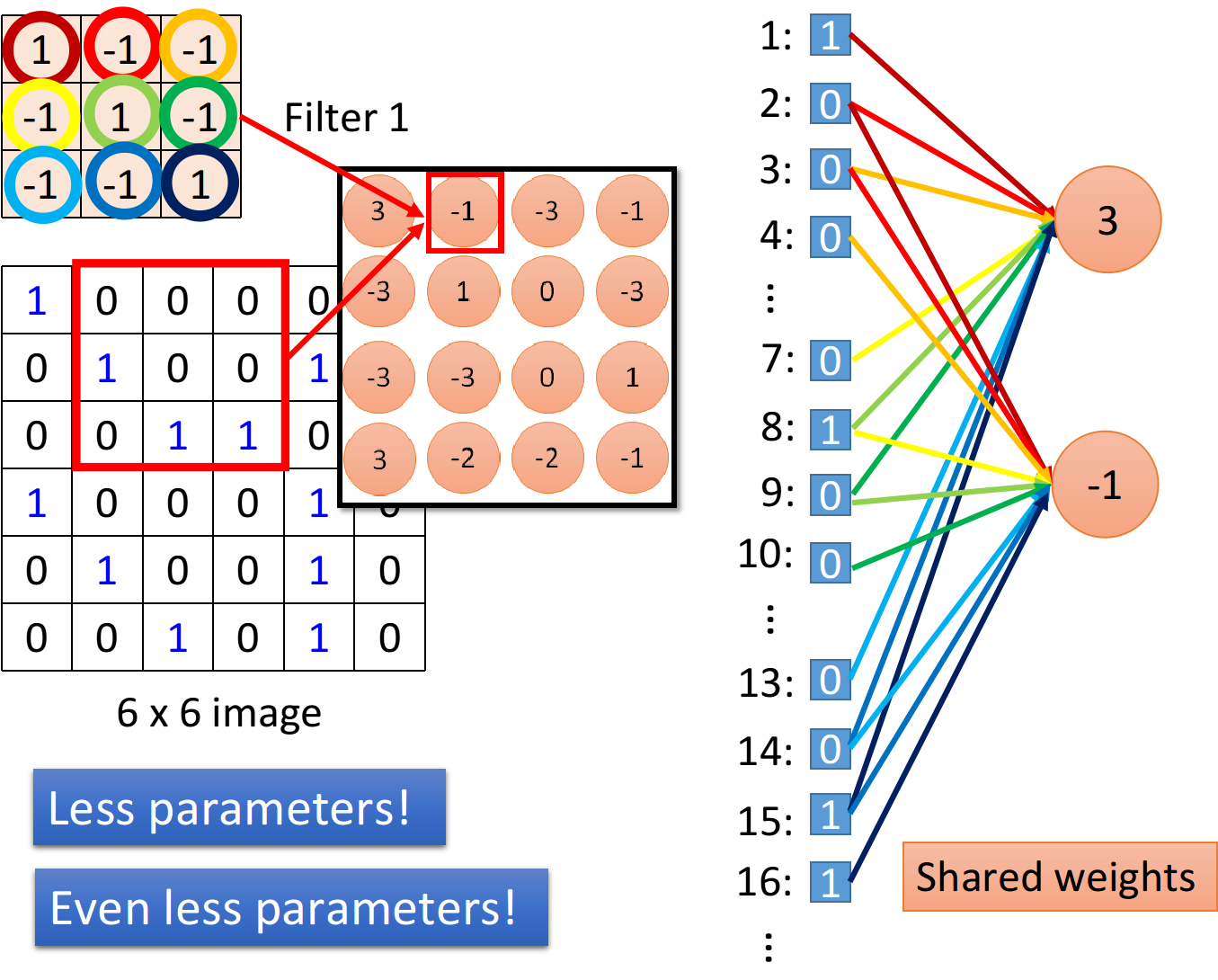
另外,一张图片上不同位置的相同特征,对于这张图片传递的信息来说,大多跟位置无关。我们当然希望使用同一组权重可以提取不同位置的相同特征。这就是权值共享。
总的来说,全连接网络前向传播的过程中永远考虑到整张图片的信息,而卷积神经网络每次采样都只考虑局部特征。理论上说,全连接网络保留了所有信息,但是层中每一个神经元都要考虑全部的信息,导致不堪重负,训练不起来。
而卷积神经网络主动对信息进行了区域划分,每一个神经元只负责一个小区域的信息,逐步抽象,直到最后才把高度精炼的信息整合起来。
几个问题
- 全连接网络丢失了空间信息吗
- 为什么卷积可以提取特征
- 为什么池化层使用maxpooling而不是average-pooling
第一个问题。我以为是没有丢失的,只是难以训练罢了
第二个问题。我在深度学习与目标检测这本书中看到有这么一段话
“在深度神经网络的具体应用中,往往有多个卷积核,我们可以认为,每一个卷积核代表了一种图像模式,如果某个图像块与此卷积核进行卷积后输出的值很大,则认为此图像块十分接近此卷积核”
关于为什么现在还不太明白,我姑且认为这是对的,并以此做一些推断。即当图片经过一个卷积层之后,较大的值就认为是特征区域抽象出来的特征值。
第三个问题。在第二个问题的假设下,我们得知很有价值的特征点的值都比周围区域的值大,那么我们通过一个maxpooling层后不会影响到这个大的点,只会丢弃一些没有那么重要的值,从而起到降维的目的而保留特征。但是如果使用average-pooling将我们认为重要的特征值跟旁边不重要的特征值做了平均,显然是降低了特征值对输出的影响。
至于average-pooling的用途,以后再来补充