直接用requeses、selenium等库写爬虫,对于爬取量不大,速度要求不高的,完全可以满足
利用框架,可以不用关心某些功能的具体实现,只需关心逻辑就行,可以大大简化代码量,架构也清晰,效率也高
1、pyspider
国人binux编写的强大的网络爬虫框架,带有强大的WebUI、脚本编辑器、任务监控器、项目管理器以及结果处理器,同时支持多种数据库后端、多种消息队列,还支持JS渲染页面的爬取(依赖PhantomJS)
pip3 install pyspider
启动成功

2、Scrapy
十分强大的爬虫框架,依赖库比较多,至少需要Twisted14.0、lxml3.4和pyOpenSSL0.14
不同环境下依赖的库也不相同,安装前最好确保把基本的库都安装上
2.1.安装lxml
2.2.安装pyOpenSSL
官网下载wheel文件
https://pypi.python.org/pypi/pyOpenSSL#downloads

pip3 install pyOpenSSL-18.0.0-py2.py3-none-any.whl
3.3.安装Twisted
下载对应wheel文件
http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted

pip3 install Twisted-18.4.0-cp36-cp36m-win_amd64.whl
3.4.安装PyWin32
下载对应安装包
https://sourceforge.net/projects/pywin32/files/pywin32/Build%20221/

依赖库都安装完成,pip安装Scrapy
pip3 install Scrapy
3、Scrapy-Splash
Scrapy-Splash是一个Srapy中支持JS渲染的工具
Scrapy-Splash安装分为两部分:
1.Splash服务的安装,具体是通过Docker,安装后会启动一个Solash服务,可以通过它的接口来实现JS页面的加载
2.Scrapy-Splash的python库安装,安装后即可在Scrapy中使用Splash服务
3.1.安装Splash
Scrapy-Splash会使用Splash的HTTP API进行页面渲染,需要通过Splash来提供渲染服务
安装Docker
Docker下载:
https://docs.docker.com/docker-for-windows/install/#download-docker-for-windows
Windows环境下下载Docker必须满足:Docker for Windows requires 64bit Windows 10 Pro and Microsoft Hyper-V(即需要64位Windows 10 Pro(专业版和企业版都可以)和Microsoft Hyper-V),Hyper-V是微软的虚拟机,在win10上是自带的,我们只需要启动就可以了。
win10 64位系统,推荐安装最新版Docker for Windows,如果不是的话可以下载安装Docker Toolbox
https://docs.docker.com/toolbox/toolbox_install_windows/

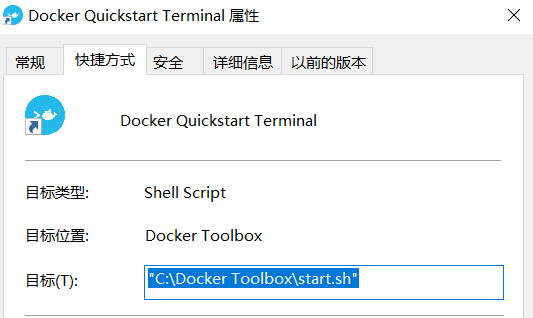
这里出现了问题,双击桌面图标,提示找不到bash.exe,但是从文件夹启动start.sh就可以,所以我擅自修改了快捷方式的目录。。

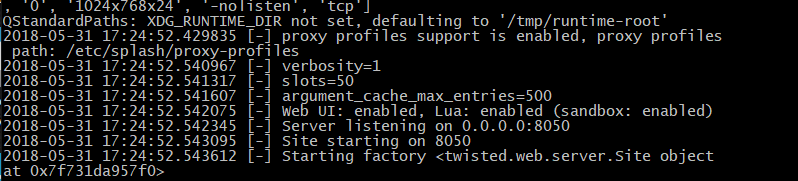
docker run -p 8050:8050 scrapinghub/splash

安装完成输出
浏览器访问:

安装Scrapy-Splash
pip3 install scrapy-splash
安装Scrapy-Redis
是Scrapy的分布式扩展模块,有了它我们就可以方便的实现Scrapy分布式爬虫的搭建
pip3 install scrapy-redis
安装Scrapyd
用于部署和运行Scrapy项目的工具(linux)
可以将写好的Scrapy项目上传到云主机,通过API来控制它
安装完毕需要新建配置文件/etc/scrapyd/scrapyd.conf
配置内容参考官方文档:https://scrapyd.readthedocs.io/en/stable/config.html$example
pip3 install scrapyd
安装Scrapyd-Client
Scrapy部署到远程Scrapyd,首先要将代码打包为EGG文件,然后要将EGG文件上传到主机,就用到了它
pipe install scrapyd-client
安装Scrapyd API
安装好Scrapyd后,可以直接通过API来获取主机的Scrapy任务状况
运行命令获取当前主机所有的Scrapy项目:
curl http://主机IP和端口/listprojects.json
返回JSON字符串
pip3 install python-scrapyd-api
安装Scrapyrt
为Scrapy提供了一个调度的HTTP接口
pip3 install scrapyrt
安装Gerapy
一个Scrapy分布式管理模块
pip3 install gerapy