1 算子简介
算子是一个函数空间到函数空间上的[映射]O:X→X。广义上的算子可以推广到任何空间,如[内积空间]等。
RDD上的方法称为算子
在 RDD 上支持 2 种操作:
-
transformation转换
从一个已知的 RDD 中创建出来一个新的 RDD 例如: map就是一个transformation.
-
*action *行动
在数据集上计算结束之后, 给驱动程序返回一个值. 例如: reduce就是一个action.
在 Spark 中几乎所有的transformation操作都是懒执行的(lazy), 也就是说transformation操作并不会立即计算他们的结果, 而是记住了这个操作.
只有当通过一个action来获取结果返回给驱动程序的时候这些转换操作才开始计算.这种设计可以使 Spark 运行起来更加的高效.默认情况下, 你每次在一个 RDD 上运行一个action的时候, 前面的每个transformed RDD 都会被重新计算.
但是我们可以通过persist (or cache)方法来持久化一个 RDD 在内存中, 也可以持久化到磁盘上, 来加快访问速度. 后面有专门的章节学习这种持久化技术.根据 RDD 中数据类型的不同,
整体分为 2 种 RDD:
-
Value类型
-
Key-Value类型(其实就是存一个二维的元组)
1.1 map算子
以分区为单位 ,内部处理每个元素
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (_, _, iter) => iter.map(cleanF))
}def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSc
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5), 2)
val f = (e: Int) => {
e * 2
}
//处理rdd负责的每个元素 返回一个新的RDD
rdd.map(f) //传入一个函数
rdd.map((e: Int) => {e * 2})
rdd.map(e => e * 2)
//调用map算子 返回一个新的RDD
val rdd2: RDD[Int] = rdd.map(_ * 2)
rdd2.collect().foreach(println)
sc.stop()
}演示处理并行处理和数据处理细节
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSc
//设置数据只有一个分区 , 处理的所有的数据在同一个分区中
// 如果是多个分区 ,资源充足的情况下分区额数据就是处理数据的并行度
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5), 1)
//我们这里多次处理 , 同一个分区中的数据是顺序执行的
val rdd2 = rdd.map(
e=>{
println("处理元素----1:"+e)
e
}
).map(
e =>{
println("处理元素----2:"+e)
e
}
)
/*
处理元素----1:1
处理元素----2:1
处理元素----1:2
处理元素----2:2
处理元素----1:3
处理元素----2:3
处理元素----1:4
处理元素----2:4
处理元素----1:5
处理元素----2:5
*/
// 触发转换算子执行
rdd2.collect()
sc.stop()
}案例需求 : 获取mysql中的数据
<!--添加MYSQL的驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
</dependency>package com._51doit.spark.day02.trans
import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet}
import com._51doit.spark.util.SparkUtils
import com.mysql.jdbc.Driver
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
/**
* Author: Hang.Z
* Date: 21/06/02
* Description:
* 1 注册驱动
* 2 获取连接
* 3 获取执行sql的statement对象
* 4 编写SQL 执行
* 5 返回结果
* 6 释放资源
*/
object _03Map {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getSparkContext()
val rdd1: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2)
// 注册驱动
classOf[Driver]
// 根据RDD处理的数据 1 2 3 4 熊mysql中获取用户名
/**
* 每个元素在每个分区中都会执行一遍 获取连接 获取 ps 执行sql 释放资源
* 效率低
* 增加mysql的请求压力
* 出现并发
*/
val rdd2 = rdd1.map(uid=>{
// 获取连接
val conn: Connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/doit20" , "root","root")
// 获取执行SQL的对象
val ps: PreparedStatement = conn.prepareStatement("select * from tb_user where uid = ?")
// 预编译sql
ps.setInt(1,uid)
// 执行SQL查询
val set: ResultSet = ps.executeQuery()
var name:String = ""
// 如果有数据
if(set.next()){
// 获取数据
val username: String = set.getString("username")
name = username
}
set.close()
ps.close()
conn.close()
name
})
rdd2.foreach(println)
sc.stop()
}
}
1.2 mapPartition
将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤数据。
val sc: SparkContext = SparkUtil.getSparkContext()
//创建RDD
val rdd: RDD[Int] = sc.parallelize(1 to 10, 3)
// 传递的是一个迭代器 , 三个分区只执行三次 效率优于map
val res: RDD[Int] = rdd.mapPartitions(iters=>{
for(e <- iters) yield e*10
})
val arr: Array[Int] = res.collect()
arr.foreach(println)
sc.stop()map():每次处理一条数据。 e
mapPartitions():每次处理一个分区的数据 iters
,这个分区的数据处理完后,原 RDD 中该分区的数据才能释放,可能导致 OOM。 Map算子是分区内一个数据一个数据的执行,类似于串行操作。而mapPartitions.算子是以分区为单位进行批处理操作。 功能的角度 Map算子主要目的将数据源中的数据进行转换和改变。但是不会减少或增多数据。MapPartitions算子需要传递一个迭代器,返回一个迭代器,没有要求的元素的个数保持不变,所以可以增加或减少数据
Map算子因为类似于串行操作,所以性能比较低,而是mapPartitions算子类似于批处理,所以性能较高。但是mapPartitions算子会长时间占用内存,那么这样会导致内存可能不够用,出现内存溢出的错误。所以在内存有限的情况下,不推荐使用。使用map操作。
mapPartitions():每次处理一个分区的数据如果每条数据需要去请求外部的资源 , 可以使用此函数减少外部资源的加载次数
开发指导:当内存空间较大的时候建议使用mapPartitions(),以提高处理效率。
获取每个分区的最大值/或者是最小值
val rdd2: RDD[Int] = rdd.mapPartitions(iters => {
println("hello.....")
List(iters.max).toIterator
})写入数据库的正确姿势
/**
* 以分区为单位处理数据 (iters迭代器)
* 是有返回值
*/
rdd1.mapPartitions(iter=>{
// 本地集合的map
iter.map(_*10)
})
/**
* 以分区为单位处理数据 (iters迭代器)
* 但是没有返回值
* 一般用于数据的输出
* 将数据输出到mysql
*/
rdd1.foreachPartition(iter=>{
val ints: Iterator[Int] = iter.map(_ * 10)
//输出数据
})
---将数据输出到MYSQL 中
rdd4.foreachPartition(iters=>{
// 获取连接
classOf[Driver]
val conn: Connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/doit20", "root", "root")
val ps: PreparedStatement = conn.prepareStatement("insert into tb_user values(?,?,?,?)")
for (user <- iters) yield {
var b = false
// 预编译
try {
ps.setString(1, user.id)
ps.setString(2, user.name)
ps.setInt(3,user.age)
ps.setString(4, user.gender)
// 执行插入
b = ps.execute()
} catch {
case e:Exception => b = true
}
}
})
1.3 mapPartitionsWithIndex
与mapPartitions类似,但需要提供一个表示分区索引值的整型值作为参数,因此function必须是(int, Iterator<T>)=>Iterator<U>类型的。
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSparkContext()
val rdd: RDD[Int] = sc.parallelize(1 to 10, 3)
// (p,iters) 参数一 分区号 参数二分区中的数据
val res = rdd.mapPartitionsWithIndex((p, iters) => {
for (elem <- iters) yield (p, elem * 10)
})
res.collect().foreach(println)
sc.stop()
}1.4 flatMap
map是对RDD中元素逐一进行函数操作映射为另外一个RDD,而flatMap操作是将函数应用于RDD之中的每一个元素,将返回的迭代器的所有内容构成新的RDD。
flatMap与map区别在于map为“映射”,而flatMap“先映射,后扁平化”,map对每一次(func)都产生一个元素,返回一个对象,而flatMap多一步就是将所有对象合并为一个对象。
作用: 类似于map,但是每一个输入元素可以被映射为 0 或多个输出元素(所以func应该返回一个序列,而不是单一元素 T => TraversableOnce[U])
private def testFlatMap = {
val sc: SparkContext = SparkUtil.getSparkContext()
val rdd: RDD[String] = sc.textFile("d://word.txt")
// 将每行数据切割后返回一个个数组 并没有将数据扁平化
// rdd.map(e=>e.split("\\s+")).collect().foreach(println)
// 将数据扁平化成一个个单词
rdd.flatMap(e => e.split("\\s+")).collect().foreach(println)
sc.stop()
}1.5 glom
将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSc
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
//将每个分区的数据收集到一个数组集合中 , 多个分区就会有多个数组集合
val rdd2: RDD[Array[Int]] = rdd.glom()
// 打印数据
rdd2.collect().map(arr=>arr.toList).foreach(println)
// 求每个分区的最大值的和
println(rdd2.map(_.max).collect().toList.sum)
sc.stop()
}1.6 filter
将数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃。当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出现数据倾斜。
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSparkContext()
val rdd: RDD[Int] = sc.parallelize(1 to 10, 3)
val rdd2: RDD[Int] = rdd.filter(e=>e>2 && e%2==0)
rdd2.collect().foreach(println) // 4 6 8 10
sc.stop()
}1.7 groupBy
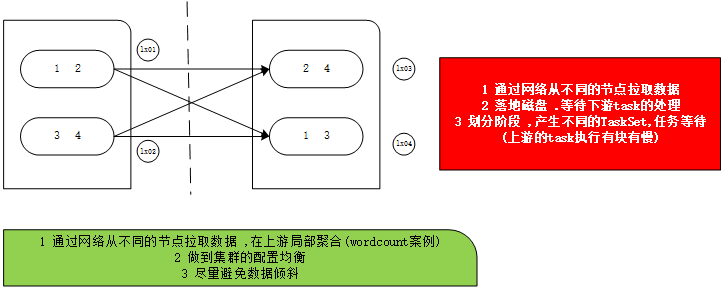
将数据根据指定的规则进行分组,分区默认不变,但是数据会被打乱重新组合,我们将这样的操作称之为shuffle。极限情况下,数据可能被分在同一个分区中
一个组的数据在一个分区中,但是并不是说一个分区中只有一个组
func返回值作为 key, 对应的值放入一个迭代器中. 返回的 RDD: RDD[(K, Iterable[T])
每组内元素的顺序不能保证, 并且甚至每次调用得到的顺序也有可能不同.
[K,V]的RDD之间的操作 ,可以根据K或者V进行分组
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSparkContext()
val arr1 = Array(("a", 11), ("a", 11), ("c", 22), ("d", 33))
val rdd1: RDD[(String, Int)] = sc.parallelize(arr1)
val rdd11: RDD[(String, Iterable[(String, Int)])] = rdd1.groupBy(_._1)
// val rdd22: RDD[(Int, Iterable[(String, Int)])] = rdd1.groupBy(_._2)
rdd11.map(e => {
val k: String = e._1
val arr: Iterable[Int] = for (x <- e._2) yield x._2
(k, arr)
}).collect().foreach(println)
sc.stop()
}
[V]类型的RDD只能根据某种条件表达式来分组 两组(一组满足条件, 一组不满足条件)
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSparkContext()
val arr1 = Array(1,2,3,4,5,5,5)
val rdd: RDD[Int] = sc.parallelize(arr1)
// 条件表达式分两组
val res1: RDD[(Boolean, Iterable[Int])] = rdd.groupBy(_>2)
val res3: RDD[(Boolean, Iterable[Int])] = rdd.groupBy(_%2==0)
sc.stop()
}课堂代码
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getSparkContext()
val rdd1: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
val rdd2: RDD[(Int, Iterable[Int])] = rdd1.groupBy(_ % 2)
// 1 分区个数没有变化
println(rdd2.partitions.size)
/**
* (1,CompactBuffer(1, 3))_ 0
* (0,CompactBuffer(2, 4))_ 1
*/
val rdd3: RDD[List[Int]] = rdd2.map(_._2.toList)
// 查看每个分区中的数据
val rdd4: RDD[(Int, List[Int])] = rdd3.mapPartitionsWithIndex((p, ls) => {
for (elem <- ls) yield {
(p, elem)
}
})
rdd4.foreach(println)
sc.stop()
案例 统计每个年龄阶段的平均薪资
数据
数据:
1,zss,23,10000
2,lss,24,30000
3,wbb,34,10000
4,DL,39,8000
5,XG,35,8000
代码
/**
* Author: Hang.Z
* Date: 21/06/05
* Description:
* 加载数据
* 统计每个年龄阶段的平均薪资
*/
object _01Demo {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getSparkContext()
// 读取数据
val rdd1: RDD[String] = sc.textFile("data/user/")
// 处理每行
val rdd2: RDD[(String, String, Int, Int)] = rdd1.map(line => {
val arr: Array[String] = line.split(",")
// 将每行的用户信息分租在元组中
(arr(0), arr(1), arr(2).toInt, arr(3).toInt)
})
// 添加 年龄阶段 信息
val rdd3: RDD[(String, String, Int, Int, String)] = rdd2.map(tp=>{
// 获取年龄
val age: Int = tp._3
// 根据判断添加阶段信息
if(age>=20 && age<30){
(tp._1,tp._2,tp._3,tp._4,"20~30")
}else if (age>=30 && age<40){
(tp._1,tp._2,tp._3,tp._4,"30~40")
}else{
(tp._1,tp._2,tp._3,tp._4,"other")
}
})
// 分租
val groupedRDD : RDD[(String, Iterable[(String, String, Int, Int, String)])] = rdd3.groupBy(_._5)
// 计算
val res: RDD[(String, Double)] = groupedRDD.map(tp=>{
// 年龄阶段
val stage: String = tp._1
// 总工资
var totalSal:Double = 0
// 计数
var cnt = 0
// 尽量不要本地集合操作
//tp._2.toList.size
for (elem <- tp._2) {
totalSal+= elem._4
cnt+=1
}
// 求平均工资
val avg = totalSal/cnt
(stage , avg)
})
// 检查结果
res.foreach(println)
sc.stop()
}
}