2. Scale Imbalance
2.1. Object/box-level Scale Imbalance
Methods Based on Image Pyramids
- SNIP, CVPR 2018, [paper] An Analysis of Scale Invariance in Object Detection - SNIP
- SNIPER, NeurIPS 2018, [paper]
---------------性能最佳的三叉戟网络 trident network
SNIP (Scale Normalization for Image Pyramids)
(1)多阶段的训练:先是用负样本来训练模型,然后用正样本验证学到的模型,最后将正样本中训练错误的和负样本一起来训练模型。
(2)Scale Normalization for training : 使用rpn 。理由:缺陷里面有很多正确的纹理,这些正确的纹理将会是判别缺陷的噪音。所以使用一个合适大小的框来减少这种噪音。
(3)cascade结构
图像增强的时候,数据量增加到多少能达到一个最终的结果,这时增加图片就没有提升效果了?这要看数据集的复杂度,平常做的上下翻转,高斯模糊等等不能够做的太多,如果做的太多实际上训练样本对于最终的真实样本分布已经不一致了。复杂度小,增强小,复杂度高,增强多。这次做了一些的尝试,最后定在了4000到5000张左右。
(4)在训练中利用可形变卷积(DCN)能够学习到瑕疵更多形态。不规则卷积对应不规则形状有更好的针对性。( ps:通过对卷积核学习一个位置偏移权重,使得卷积核不再是标准的3*3卷积核,而是通过位置偏移实现出不规则形状的卷积核。)
(5)由于小瑕疵的缺陷定位不准确,导致被判为误检;不完全的ROIPooling可能会未学到瑕疵的特征。 解决方案:利用ROIAlign 使得特征与空间有着更准确的对应关系;通过线性插值获得对应位置的特征值。
由于瑕疵中有非常细长的box,所以在anchor中预设一个细长的框子,他的长宽比是5:1。
困难样本学习:(1)无困难样本增强(2)困难样本增强(3)Batch级别的困难样本增强,这个提升最强

最后的框体预测:Soft-NMS,NMS,投票平均三种方法的比较
经验:阈值的设置影响了召回率,但是在精度上面的提升非常有限。
(1)用聚类算法获取定制anchors尺寸;
(2)用RoI Align替换掉ROIPooling;
(3)用softNMS替换掉NMS
2 数据分析:数据分布不平衡,瑕疵面积占比小,瑕疵的尺度分布变化大 。工作:数据增强采用了左右翻转,随机剪裁,中心剪裁。 当分辨率降低以后,如何在数据增强中体现出应对的策略? 亮度变化,测试集中没有加入亮度差异变化,所以效果不明显,后期加入。
3 创新点
(1)kmeans聚类算法分析训练集中真实框的分布;
(2)ROI Align 替换掉ROI Pooling,作用:消除ROIPooling过程中的量化,获取更精准的候选框的特征,从而提高检测性能。
(3)softNMS替换掉NMS,作用:针对脏点等容易大数量集中在某个区域的小瑕疵进行更好的检测。
Faster R-CNN默认的RPN_ASPECT_RATIONS为[1,0.5,2]手动改宽高比是[0.125,0.25,0.5,1,2,4,8];
2 数据处理:制作成coco格式的数据集,数据增强(水平翻转,旋转[range(0,30,360)]),多尺度训练
3 创新点
(1)模型宽高比的优化;
(2)训练的时候讲train.scales参数优化为:[500,550,600,650,700,750,800,850,900,950,1000]实现多尺度训练
(3)在预测的时候讲test.scales的参数优化为:[400,450,500,550,600,650,700,750,800,850,900,950,1000,1050,1100,1150,1200];水平翻转;NMS
2 数据增强方面只是简单的旋转吗? 只是简单的旋转,另外标注啊框也跟着旋转。
3 你说可以做迁移学习到其他任务,怎么做?提升了大概1个百分点,尺寸大小变化了,比例不变。
增加soft-nms,box voting,多尺度等。
多尺度扰动训练 在线数据增强 多尺度预测 box stacking避免漏框 box voting精修 soft nms避免误删
图片处理的部分,是两张图片做一个融合来进入模型的吗? 两张图片是两路输入,瑕疵候选框只能通过瑕疵照片,无瑕疵照片只能够生成背景类,这样能够让RPN能够更好的学习瑕疵和背景的区别。
Contextual RoI Pooling Online hard example mining ensemble模型融合 MS COCO预训练 objects365 openimage
模型变化:将maskrcnn中的Align Pooling加入到该模型中;加入空洞卷积;
双路集成的目标检测特征提取:从两路上进行特征提取。1.2fps
多层Align Pooling
数据增强:
水平或者竖直翻转;color jitter;Multi-scales Training:scaling invariance;Transfer Learning:Pretrained on Coco dataset
(1)加入stochastic weight averaging这个和SGD比较有更好的准确度和更快的收敛速度。
(2)Hierachical Feature Ensembling
(2)为什么要用Deep Learning?弱语义信息不代表没有语义信息;规则无穷尽,不能遍举
(3)最大的困难是什么?数据,数据,数据。其次困难是什么?进场困难,缺陷样本少,标记困难。
(4)为什么coco预训练模型比imagenet预训练模型好(大家基本上都是用fpn加上coco预训练模型)?
(5)FPN为什么是杀手级的结构?除了加上多尺度,其实还是增强了较底层的纹理。和深度学习中语义不断深化相比这里更像是一个浅层网络级联起来的一个网络。低层次的特征在这次更加接近输出结果。
(6)瑕疵检测需要很细化的特征。
(7)同类型的模型融合SWA;不同类模型之间的融合:DCN+G-R-CNN
2 对于划痕来说这东西很难学到的,你觉得这种东西该怎么标框呢?可以在外标一个框,然后在内用一个弱监督的方式来聚焦这些瑕疵。
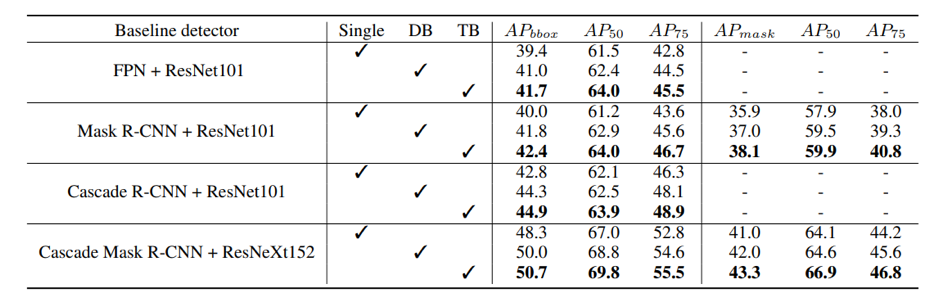
对于赛道一,类似于MS COCO数据集的评估方案,主办方采用AP、APIOU=0.50、APIOU=0.75、ARmax=10、ARmax=100、ARmax=500五个指标来评估检测算法的结果。最终的排名依据于 AP 和 ARmax=500 两项指标的调和平均数,高者为优。

根据以往积累的经验,团队首先将原图缩放到合适尺度,并使用基于Cascade RCNN的检测器直接检测行人的三个类别和车辆,将其作为Baseline: Backbone + DCN + FPN + Cascade RCNN,并在此基础上进行改进。

实验结果显示,模型存在大量的误检和漏检。这些漏检和无意义的检测结果大幅降低了模型的性能。团队将上述问题归纳为两方面的原因:
-
训练和测试时输入模型的图像尺度不合适。图像经过缩放后,目标的尺度也随之变小,导致远景中人的头部等区域被大量遗漏。
-
网络本身的分类能力较弱。行人的可见区域和全身区域十分相似,容易对分类器造成混淆,从而产生误检。
根据上述问题,团队进行了一些改进。
首先,使用滑动窗口的方式切图进行训练。滑动窗口切图是一种常用的大图像处理方式,这样可以有效的保留图像的高分辨率信息,使得网络获得的信息更加丰富。如果某个目标处于切图边界,根据其IOF大于0.5来决定是否保留。
其次,对于每个类别采用一个单独的检测器进行检测。经过实验对比,对每个类别采用单独的检测器可以有效的提高网络的效果,尤其是对于可见区域和全身区域两类。
同时向检测器添加了Global Context (GC) block来进一步提高特征提取能力。GC-Block结合了Non-local的上下文建模能力,并继承了SE-Net节省计算量的优点,可以有效的对目标的上下文进行建模。

除Cascade RCNN外,还采用了Generalize Focal Loss (GFL)检测器进行结果互补。GFL提出了一种泛化的Focal Loss损失,解决了分类得分和质量预测得分在训练和测试时的不一致问题。
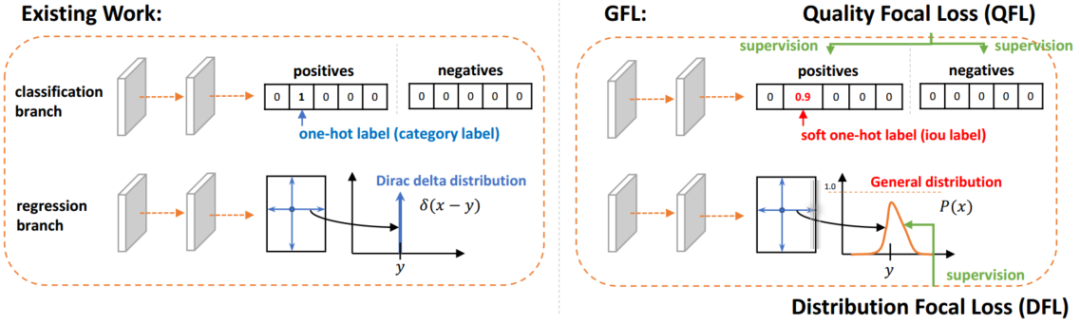
最后,将各检测器的结果使用Weighted Box Fusion (WBF)进行融合,形成了最终的解决方案。
传统的NMS和Soft-NMS方法会移除预测结果中的一部分预测框,而WBF使用全部的预测框,通过进行组合来获得更加准确的预测框,从而实现精度提升。整体pipeline如下图所示:

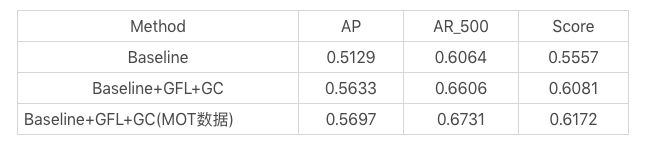
实验结果:
就检测器而言,该团队首先通过常规检测所累积的经验构造出一个 baseline:
Baseline = Backbone + DCN + FPN + Cascade + anchor ratio (2.44)
这些模块早已是各个比赛的「常客」,也被许多专业人士进行了比较透彻的分析,此处不再赘述。DeepBlueAI 团队进行了简单的实验,发现这些模块总是有用,进而将这套算法作为 baseline,加上一些行人检测的小 trick,如将 anchor ratio 改为 2.44、针对标注为 ignore 的目标在训练过程中 loss 不进行回传处理。
具体主要工作包含以下几个方面:
1. Double Heads

通过观察实验发现,baseline 将背景中的石柱、灯柱等物体检测为行人,这种情况大多和 head 效果不好有关。该团队基于此进行了实验,如 TSD [7]、CLS [8]、double head [9],并最终选择了效果好且性价比高的 double head 结构(如下图所示):
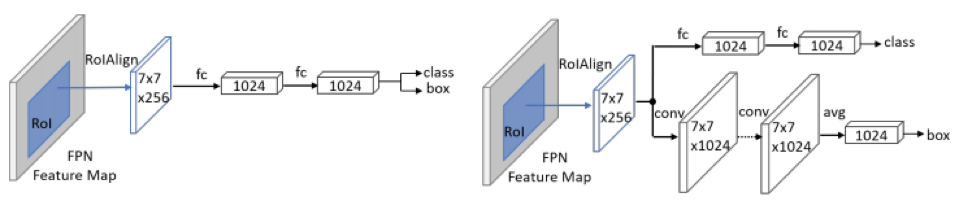
Double Heads 结构
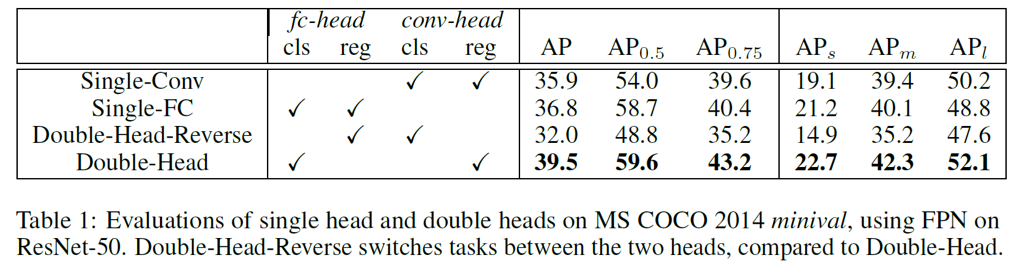
通过对比实验可以发现:使用 FC-head 做分类、Conv-head 做回归,可以得到最好的效果。
分类更多地需要语义信息,而坐标框回归则更多地需要空间信息,double head 方法采用分而治之的思想,针对不同的需求设计 head 结构,因此更加有效。当然这种方法也会导致计算量的增加。在平衡速度和准确率的情况下,该团队最终选择了 3 个残差 2 个 Non-local 共 5 个模块。
2. CBNet [10]
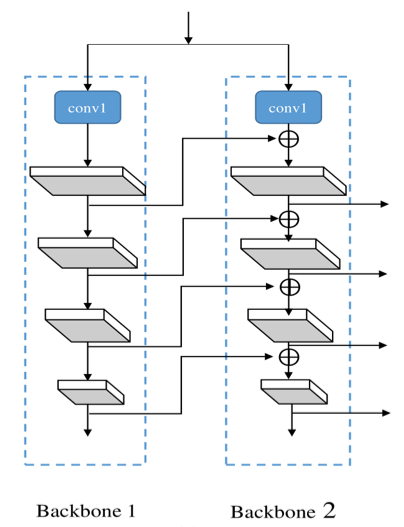
合并功能更强大的 backbone 可提高目标检测器的性能。CBNet 作者提出了一种新颖的策略,通过相邻 backbone 之间的复合连接 (Composite Connection) 来组合多个相同的 backbone。用这种方式他们构建出了一个更强大的 backbone,称为「复合骨干网络」(Composite Backbone Network)。
当然这也带来了模型参数大小和训练时间的增加,属于 speed–accuracy trade-off。该团队也尝试过其他的改进方式,但最终还是选择了实用性更强的 CBNet,该方法不用再额外担心预训练权重的问题。
该团队选择了性价比较高的双 backbone 模型结构。
3. 数据增强
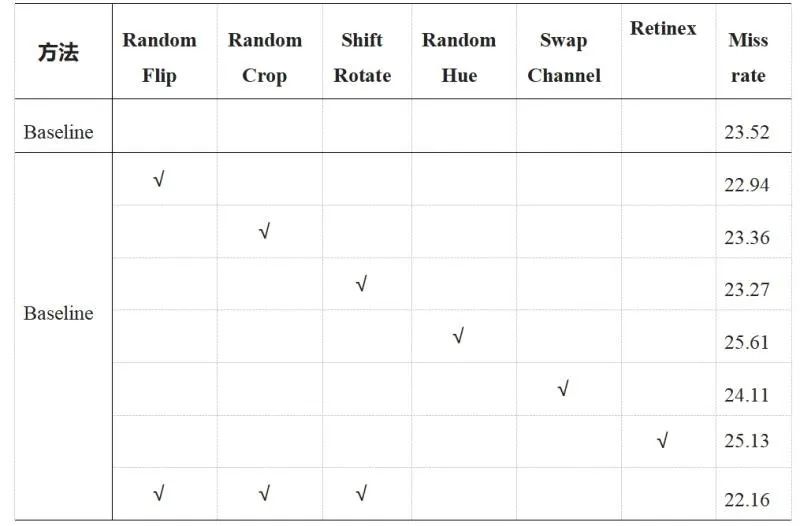
该团队发现 Pixel-level 的增强方式导致了性能结果大幅下降,因此没有在这个方向继续尝试。
而图像增强方式 Retinex,从视觉上看带来了图像增强,但是该方法可能破坏了原有图片的结构信息,导致最终结果没有提升。
于是,该团队最终选择了 Spatial-level 的增强方式,使得结果有一定的提升。
实验细节
1. 将 Cascade rcnn + DCN + FPN 作为 baseline;
2. 将原有 head 改为 Double head;
3. 将 CBNet 作为 backbone;
4. 使用 cascade rcnn COCO-Pretrained weight;
5. 数据增强;
6. 多尺度训练 + Testing tricks。
实验结果
下图展示了该团队使用的方法在本地验证集上的结果:

该团队将今年的成绩与去年 ICCV 2019 同赛道冠军算法进行对比,发现在不使用额外数据集的情况下,去年单模型在 9 个尺度的融合下达到 11.06,而该团队的算法在只用 2 个尺度的情况下就可以达到 10.49。
未来工作
该团队虽然获得了不错的成绩,但也基于已有的经验提出了一些未来工作方向:
1. 由于数据的特殊性,该团队尝试使用一些增强方式来提高图片质量、亮度等属性,使图片中的行人更易于检测。但结果证明这些增强方式可能破坏原有图片结构,效果反而降低。该团队相信会有更好的夜间图像处理办法,只是还需要更多研究和探索。
2. 在允许使用之前帧信息的赛道二中,该团队仅使用了一些简单的 IoU 信息。由于收集这个数据集的摄像头一直在移动,该团队之前在类似的数据集上使用过一些 SOTA 的方法,却没有取得好的效果。他们认为之后可以在如何利用时序帧信息方面进行深入的探索。
3. 该领域存在大量白天行人检测的数据集,因此该团队认为之后可以尝试 Domain Adaption 方向的方法,以充分利用行人数据集。
当时实验的模块有:SE、CBAM等,由于当时Baseline有点高,效果并不十分理想。(注意力模块插进来不可能按照预期一下就提高多少百分点,需要多调参才有可能超过原来的百分点)根据群友反馈,SE直接插入成功率比较高。笔者在一个目标检测比赛中见到有一个大佬是在YOLOv3的FPN的三个分支上各加了一个CBAM,最终超过Cascade R-CNN等模型夺得冠军。
大家都知道通过改cfg的方式改网络结构是一件很痛苦的事情,推荐一个可视化工具:
https://lutzroeder.github.io/netron/Anchor对模型影响比较大,Anchor先验不合理会导致更多的失配,从而降低Recall。
当时跟群友讨论的时候就提到一个想法,对于小目标来说,浅层的信息更加有用,那么进行FPN的时候,不应该单纯将两者进行Add或者Concate,而是应该以一定的比例完成,比如对于小目标来说,引入更多的浅层信息,让浅层网络权重增大;大目标则相反。后边通过阅读发现,这个想法被ASFF实现了,而且想法比较完善。