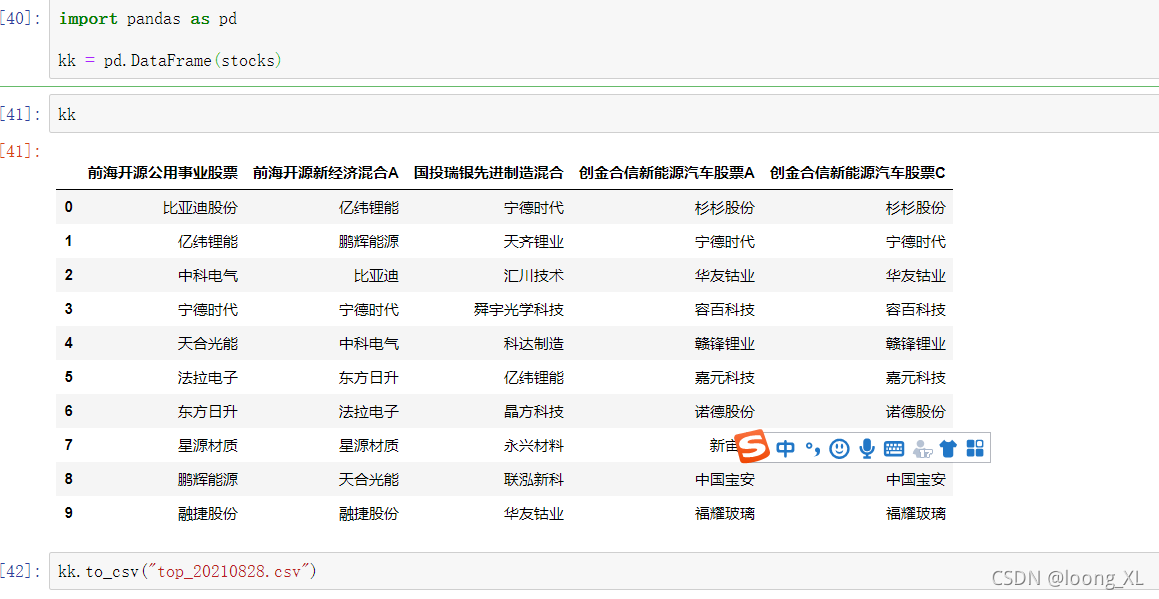
http://fund.eastmoney.com/data/fundranking.html
获取每日基金收益排行top基金
**url3中sc=3yzf 表示近几月收益排序,6yzf表示近6月;sd=2020-08-28&ed=2021-08-28表示日期
import requests
import re
headers={
"Referer": "http://fund.eastmoney.com/data/fundranking.html",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
url3 = "http://fund.eastmoney.com/data/rankhandler.aspx?op=ph&dt=kf&ft=all&rs=&gs=0&sc=3yzf&st=desc&sd=2020-08-28&ed=2021-08-28"
all1 = requests.get(url3,headers=headers).text
all2 = eval(re.findall('datas:(.*?),allRecords',all1)[0])
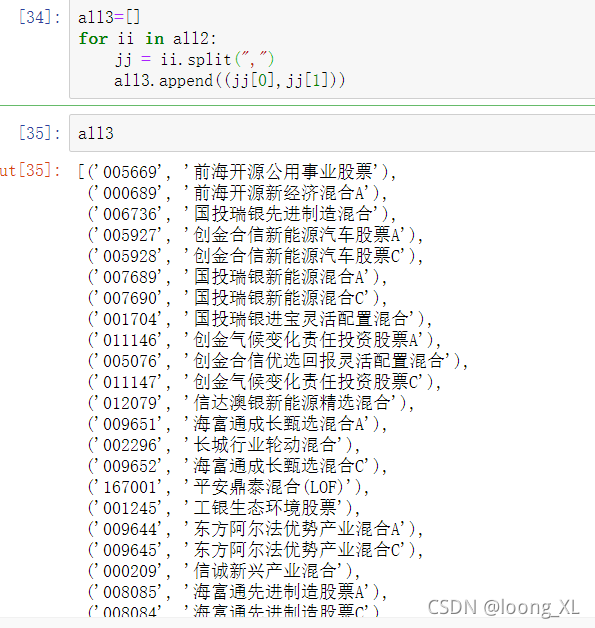
all3=[]
for ii in all2:
jj = ii.split(",")
all3.append((jj[0],jj[1]))
并获取其持仓情况
import requests
import re
from lxml import etree
import csv
def get_stock_lists(id):
try:
url2 = f"https://fundf10.eastmoney.com/FundArchivesDatas.aspx?type=jjcc&code={id}&topline=10"
tables2 = requests.get(url2)
str1 = tables2.text
str2 = re.findall('content:"(.*?)",',str1)[0]
# print(str2)
html1 = etree.HTML(str2)
print(html1.xpath("//label/a/text()")[0],html1.xpath("//tr/td[3]//text()")[:10])
return html1.xpath("//label/a/text()")[0],html1.xpath("//tr/td[3]//text()")[:10]
except Exception as e:
print(e)
return 0,0
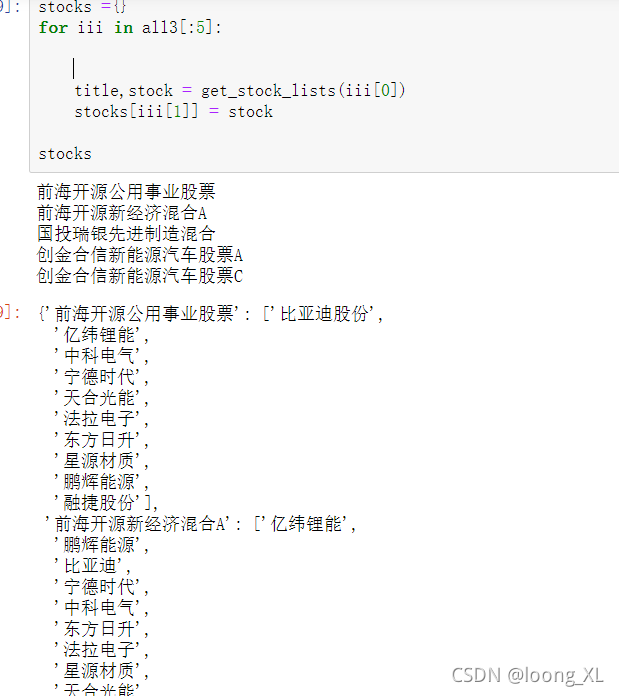
stocks ={}
for iii in all3[:30]:
print(iii[1])
title,stock = get_stock_lists(iii[0])
stocks[str(iii[0])+" "+iii[1]] = stock
stocks
统计持股股票排行
stockss ={}
for i,j in stocks.items():
# print(j)
try:
for jj in j:
if jj not in stockss:
stockss[jj]=1
else:
stockss[jj]+=1
except:
pass
d_order=sorted(stockss.items(),key=lambda x:x[1],reverse=True) # 按字典集合中,每一个元组的第二个元素排列。
# x相当于字典集合中遍历出来的一个元组。
print(d_order)

保存为csv
import pandas as pd
kk = pd.DataFrame(stocks)
kk.to_csv("top_20210828.csv")