数据的持久性在大多数软件应用程序中起着至关重要的作用。本文介绍了三种用 Python 实现的数据库——pickleDB、TinyDB 和 ZODB。让我们探索它们的独特特征和用例场景。
对大量数据库的支持是使 Python 成为软件开发人员最喜欢的语言的众多特性之一。除了支持MySQL、Oracle、PostgreSQL、Informix 等通用数据库系统外,它还支持许多其他特定系统。例如,它支持嵌入式数据库,如 SQLite 和 ThinkSQL。并且支持Neo4J等图形数据库。
本文探讨了三个 Python 数据库——pickleDB、TinyDB 和 ZODB。这三个是在 Python 中实现的,用于特定目的。
泡菜数据库
pickleDB 是一个简单而轻量级的数据存储。它将数据存储为键值存储。它基于名为 SimpleJSON 的 Python 模块,它允许开发人员以简单快捷的方式处理 JSON(JavaScript Object Notation)。SimpleJSON 是一个没有依赖的纯 Python 实现;它用作 Python 2.5+ 版本的编码器和解码器。
由 Harrison Erd 开发,pickleDB 可用于 BSD 三条款许可证。可以使用以下命令毫不费力地安装它:
$ pip install pickledb
|
pickleDB 这个名字的灵感来自于一个名为 pickle 的 Python 模块,pickleDB 之前使用过这个模块。尽管pickleDB 的后续版本开始使用SimpleJSON 模块,但仍保留了pickle 名称。
以下代码段说明了使用 pickleDB 的基础知识。
>>> import pickledb
>>> db = pickledb.load('example.db', False)
>>> db.set('key', 'value')
True
>>> db.get('key')
'value'
>>> db.dump()
True
|
下面解释了pickleDB的一些常用命令。
- LOAD 路径转储:这用于从文件加载数据库。
- SET 键值:这是带有字符串的键的值。
- GET key:用于获取key的值。
- GETALL:用于获取数据库中的所有键。
- REM 键:删除键。
- DUMP:将内存中的数据库保存到load命令指定的文件中。
除了上面提到的命令之外,还有各种其他命令。
pickleDB 可用于那些适合键值存储类型格式的场景。
图 1:Python 数据库
小数据库
顾名思义,TinyDB 是一个紧凑、轻量级的数据库,并且是面向文档的。它是 100% 用 Python 编写的,没有外部依赖。正如官方文档所说,TinyDB 是一个为你的幸福而优化的数据库。
最适合 TinyDB 的应用程序是小型应用程序,传统的基于 SQL-DB 服务器的方法将使其过载。TinyDB 的主要功能如下:
- 顾名思义,TinyDB 非常小。完整的源代码只有1200行。
- TinyDB 基于面向文档的存储。MongoDB 等流行工具采用了这种类型的存储。
- TinyDB 的 API 非常简单和干净。首先,TinyDB 的设计考虑到了易用性。
- TinyDB 的另一个令人喜欢的特性是非依赖性。此外,TinyDB 支持所有最新版本的 Python。它适用于 Python 2.6、2.7、3.3 – 3.5。
- 可扩展性是 TinyDB 的另一个主要特性。在中间件的帮助下,可以扩展 TinyDB 行为以满足特定需求。
尽管 TinyDB 具有多种优势,但它并不是解决问题的一刀切。它有一些限制,如下所列:
- TinyDB 不适合那些以高速数据检索为关键的场景。
- 如果您需要从多个进程或线程访问数据库,那么 TinyDB 将不是最佳选择。同样,基于 HTTP 服务器的访问是另一种不适合的场景。
了解了 TinyDB 的优缺点后,让我们来看看如何使用它。与许多其他软件包的情况一样,可以使用以下命令简单地安装 TinyDB:
$ pip install tinydb
|
以下代码片段探讨了如何在 TinyDB 中创建和存储值:
from tinydb import TinyDB, Query
db = TinyDB('db.json')
db.insert({
'type': 'OSFY', 'count': 700})
db.insert({
'type': 'EFY', 'count': 800})
|
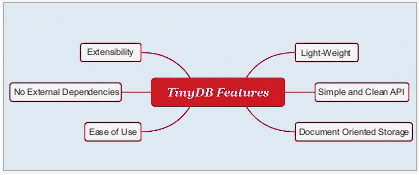
图 2:微型数据库功能
成功执行上述代码段后,您可以检索如下所示的值。
要列出所有值,请给出以下命令:
db.all()
[{
'count': 700, 'type': 'OSFY'}, {
'count': 800, 'type': 'EFY'}]
|
要搜索和列出值,请键入:
Magazine = Query()
db.search(Magazine.type == 'OSFY')
[{
'count': 700, 'type': 'OSFY'}]
db.search(Magazine.count > 750)
[{
'count': 800, 'type': 'EFY'}]
|
要更新值,请使用以下命令:
db.update({
'count': 1000}, Magazine.type == 'OSFY')
db.all()
[{
'count': 1000, 'type': 'OSFY'}, {
'count': 800, 'type': 'EFY'}]
|
要删除值,请键入:
db.remove(Magazine.count < 900)
db.all()
[{
'count': 800, 'type': 'EFY'}]
|
要删除所有值,请给出以下命令:
db.purge()
db.all()
[]
|
TinyDB 使开发人员能够以两种不同的方式处理数据,如下所列:
- JSON
- 在记忆中
默认值为 JSON,如果要将其更改为内存中,则需要明确指定。
from tinydb.storages import MemoryStorage
db = TinyDB(storage=MemoryStorage)
|
数据库
ZODB 是 Python 的本机对象数据库。其主要特点是:
- 代码与数据库的无缝集成。
- 与数据库相关的操作不需要单独的语言。
- 不需要数据库映射器。
ZODB 更适合以下场景:
- 当开发人员想要更多地关注应用程序而不是构建大量数据库代码时。
- 当应用程序有很多复杂的关系和数据结构时。
- 当数据读操作比写操作大时。
同时,ZODB不适合应用需要大量数据写入操作的场景。
要安装 ZODB,请使用以下命令:
$ pip install ZODB
|
与数据库建立连接的简单代码片段如下所示:
import ZODB, ZODB.FileStorage
storage = ZODB.FileStorage.FileStorage('mydata.fs')
db = ZODB.DB(storage)
connection = db.open()
root = connection.root
|
ZODB 允许开发人员使用多种存储选项,如下所列:
- 内存数据库
- 本地文件
- 远程服务器上的数据库
- 高级选项,例如压缩和加密存储
对象的成员可以使用 ZODB 函数直接存储。ZODB 也支持事务。
本文试图深入了解 Python 数据库的世界。除了本文介绍的三个数据库之外,还有很多其他的数据库,例如buzhug和CodernityDB。最重要的是,所有这些数据库工具在您使用它们时都提供了 Pythonic 氛围。