public class ChineseTest {
public static void main(String[] args) {
String string="aa嘻嘻嘻@,#¥%FFF12345";
System.out.println(string.replaceAll("[^\\u4e00-\\u9fa5]", ""));//将非中文替换成空
}
}
输出结果为:
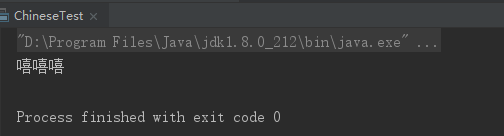
“\u4e00”和“\u9fa5”是unicode编码,并且正好是中文编码的开始和结束的两个值,所以这个正则表达式可以用来判断字符串中是否包含中文。