一、问题分析:
1、mysql导入hive 数值类型变成null的问题
mysql中没有boolean类型,boolean在MySQL里的类型为tinyint(1),
例:
create table xs
(
id int primary key,
bl boolean
)这样是可以创建成功,但查看一下建表后的语句,就会发现,mysql把它替换成tinyint(1)。
也就是说mysql把boolean=tinyInt了。
MYSQL保存boolean值时用1代表TRUE, 0代表FALSE,boolean在MySQL里的类型为tinyint(1)

问题描述:
mysql通过sqoop导入到hive表中,发现有个别数据类型为int或tinyint的列导入后数据为null。设置各种行分隔符,列分隔符都没有效果。
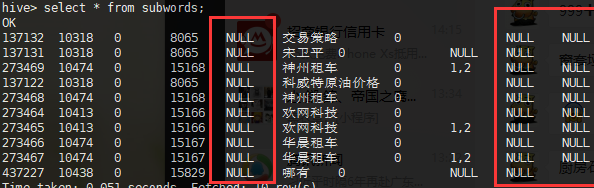
问题分析:
hive中单独将有问题的那几列的数据类型设置为string类型,重新导入后发现,里面的值变成true或者false。
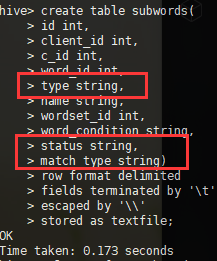
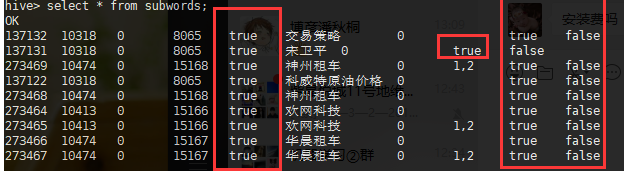
由此猜想,sqoop在导入的时候,将那几列的数据转换成了bool类型,问题产生的原因和hive建表语句无关,只能发生在sqoop端或者mysql端。
经过查看,发现mysql中有问题的那几列数据类型都是tinyint(1),这说明什么,说明那几列的数值长度为1。猜想sqoop将数值长度为1的数据类型,认为是bool类型,导入的时候会自动转换成bool类型。
验证:在sqoop的导入sql语句中,单独对那几个问题列进行数据类型转换(CONVERT(match_type,SIGNED)),然后再导入hive,发现数据可以正常显示,一点问题也没有
convert 函数 用来转换数据类型
例子:SELECT CONVERT (VARCHAR(5),12345)
返回:字符串 '12345'
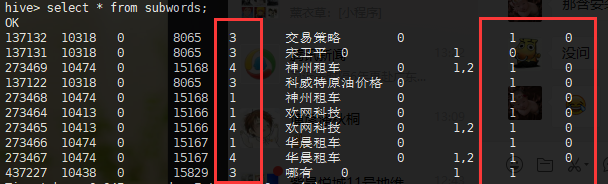
解决方法:
sqoop导入的时候,将数据类型为1个字符长度的数值类型的列,进行格式转换(CONVERT(match_type,SIGNED))
2、sqoop 处理换行符 \n 和\r 等特殊符号处理
公司大数据平台ETL操作中,在使用sqoop将mysql中的数据抽取到hive中时,由于mysql库中默写字段中会有换行符,导致数据存入hive后,条数增多(每个换行符会多出带有null值得一条数据),导致统计数据不准确。因为sqoop 导出文件不能是ORC这种列式存储,所以只能替换。导出后对替换的字符在进行替换,将数据表存储 orc
一、sqoop的sql中对含有特殊字符的字段进行replace操作 ,将特殊字符转换为空格。
从mysql导入时--query用replace
replace(replace(replace(description,'\r',' '),'\n',' '),'\t',' ')
二、利用一下两个参数可以实现对换行等特殊字符的替换或者删除
--hive-delims-replacement--hive-drop-import-delims
使用方法,
1、在原有sqoop语句中添加 --hive-delims-replacement " " 可以将如mysql中取到的\n, \r, and \01等特殊字符替换为自定义的字符,此处用了空格
2、在原有sqoop语句中添加 --hive-drop-import-delims 可以将如mysql中取到的\n, \r, and \01等特殊字符丢弃
/usr/local/sqoop/bin/sqoop-import --connect jdbc:mysql://ip:port/xxx --username xxxx --password xxxx --table data_clt_app_info_1210 --target-dir /tmp/tmp_data_clt_app_info_text_1210_bak --fields-terminated-by '||' -m 1 --split-by stat_date --delete-target-dir --hive-delims-replacement 'aaaaaaaa'
大功告成
把特殊换行换成 aaaaaaaa
create table tmp.change_orc stored as orc as
select stat_date,app_id,queue,start_time,finish_time,regexp_replace(job_name,'aaaaaaaa',' \n ') as job_name
from tmp.tmp_data_clt_app_info_text_1210_bak 3、$CONDITIONS关键字的作用
我们在执行log中发现被替换成了1=0
sqoop import
--connect jdbc:mysql://server74:3306/Server74
--username root
--password 123456
--target-dir /sqoopout2
--m 1
--delete-target-dir
--query 'select id,name,deg from emp where id>1202 and $CONDITIONS' [root@server72 sqoop]# sqoop import --connect jdbc:mysql://server74:3306/Server74 --username root --password 123456 --target-dir /sqoopout2
--m 1 --delete-target-dir --query 'select id,name,deg from emp where id>1202 and $CONDITIONS'
Warning: /usr/local/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/local/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
17/11/10 13:42:14 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
17/11/10 13:42:14 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
17/11/10 13:42:16 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
17/11/10 13:42:16 INFO tool.CodeGenTool: Beginning code generation
17/11/10 13:42:18 INFO manager.SqlManager: Executing SQL statement: select id,name,deg from emp where id>1202 and (1 = 0)
17/11/10 13:42:18 INFO manager.SqlManager: Executing SQL statement: select id,name,deg from emp where id>1202 and (1 = 0)
17/11/10 13:42:18 INFO manager.SqlManager: Executing SQL statement: select id,name,deg from emp where id>1202 and (1 = 0)
17/11/10 13:42:18 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop
Note: /tmp/sqoop-root/compile/ac7745794cf5f0bf5859e7e8369a8c5f/QueryResult.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
17/11/10 13:42:31 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/ac7745794cf5f0bf5859e7e8369a8c5f/QueryResult.jar
17/11/10 13:42:33 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/11/10 13:42:41 INFO tool.ImportTool: Destination directory /sqoopout2 deleted.
17/11/10 13:42:41 INFO mapreduce.ImportJobBase: Beginning query import.
17/11/10 13:42:41 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
17/11/10 13:42:41 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
17/11/10 13:42:43 INFO client.RMProxy: Connecting to ResourceManager at server71/192.168.32.71:8032
17/11/10 13:42:58 INFO db.DBInputFormat: Using read commited transaction isolation
17/11/10 13:42:58 INFO mapreduce.JobSubmitter: number of splits:1
17/11/10 13:43:00 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1510279795921_0011
17/11/10 13:43:03 INFO impl.YarnClientImpl: Submitted application application_1510279795921_0011
17/11/10 13:43:04 INFO mapreduce.Job: The url to track the job: http://server71:8088/proxy/application_1510279795921_0011/
17/11/10 13:43:04 INFO mapreduce.Job: Running job: job_1510279795921_0011
17/11/10 13:44:01 INFO mapreduce.Job: Job job_1510279795921_0011 running in uber mode : false
17/11/10 13:44:01 INFO mapreduce.Job: map 0% reduce 0%
17/11/10 13:44:58 INFO mapreduce.Job: map 100% reduce 0%
17/11/10 13:45:00 INFO mapreduce.Job: Job job_1510279795921_0011 completed successfully
17/11/10 13:45:01 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=124473
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=61
HDFS: Number of read operations=4
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=45099
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=45099
Total vcore-milliseconds taken by all map tasks=45099
Total megabyte-milliseconds taken by all map tasks=46181376
Map-Reduce Framework
Map input records=3
Map output records=3
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=370
CPU time spent (ms)=6380
Physical memory (bytes) snapshot=106733568
Virtual memory (bytes) snapshot=842854400
Total committed heap usage (bytes)=16982016
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=61
17/11/10 13:45:01 INFO mapreduce.ImportJobBase: Transferred 61 bytes in 139.3429 seconds (0.4378 bytes/sec)
17/11/10 13:45:01 INFO mapreduce.ImportJobBase: Retrieved 3 records.
输出结果查看,发现1202以上的数据被正常抽出
[root@server72 sqoop]# hdfs dfs -cat /sqoopout2/part-m-00000
17/11/10 13:48:48 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
1203,khalil,php dev
1204,prasanth,php dev
1205,kranthi,admin通过以上过程,我们得知一点:$CONTITONS是linux系统的变量,在执行过程中被赋值为(1=0),虽然实际执行的这个sql很奇怪。
正式开始研究CONTITONS到底是什么,所以我们先查看官方文档。
If you want to import the results of a query in parallel, then each map task will need to execute a copy of the query, with results partitioned by bounding conditions inferred by Sqoop. Your query must include the token
$CONDITIONSwhich each Sqoop process will replace with a unique condition expression. You must also select a splitting column with--split-by.如果你想通过并行的方式导入结果,每个map task需要执行sql查询语句的副本,结果会根据sqoop推测的边界条件分区。query必须包含
$CONDITIONS。这样每个scoop程序都会被替换为一个独立的条件。同时你必须指定--split-by.分区For example:
$ sqoop import \ --query 'SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS' \ --split-by a.id \ --target-dir /user/foo/joinresults
直接理解可能有点困难,我先修改一些条件,大家观察joblog的区别。
sqoop import
--connect jdbc:mysql://server74:3306/Server74
--username root
--password 123456
--target-dir /sqoopout2
--delete-target-dir
--query 'select id,name,deg from emp where id>1202 and $CONDITIONS'
--split-by id
--m 2 我按照要求添加了--split-by id 分区,并设置map task数量为2
[root@server72 sqoop]# sqoop import --connect jdbc:mysql://server74:3306/Server74 --username root
--password 123456 --target-dir /sqoopout2 --m 2 --delete-target-dir --query 'select id,name,deg from emp where id>1202 and $CONDITIONS' --split-by id
Warning: /usr/local/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/local/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
17/11/10 13:50:26 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
17/11/10 13:50:26 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
17/11/10 13:50:28 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
17/11/10 13:50:28 INFO tool.CodeGenTool: Beginning code generation
17/11/10 13:50:30 INFO manager.SqlManager: Executing SQL statement: select id,name,deg from emp where id>1202 and (1 = 0)
17/11/10 13:50:31 INFO manager.SqlManager: Executing SQL statement: select id,name,deg from emp where id>1202 and (1 = 0)
17/11/10 13:50:31 INFO manager.SqlManager: Executing SQL statement: select id,name,deg from emp where id>1202 and (1 = 0)
17/11/10 13:50:31 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop
Note: /tmp/sqoop-root/compile/1024341fa58082466565e5bd648cb10e/QueryResult.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
17/11/10 13:50:43 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/1024341fa58082466565e5bd648cb10e/QueryResult.jar
17/11/10 13:50:46 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/11/10 13:50:55 INFO tool.ImportTool: Destination directory /sqoopout2 deleted.
17/11/10 13:50:55 INFO mapreduce.ImportJobBase: Beginning query import.
17/11/10 13:50:55 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
17/11/10 13:50:55 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
17/11/10 13:50:56 INFO client.RMProxy: Connecting to ResourceManager at server71/192.168.32.71:8032
17/11/10 13:51:12 INFO db.DBInputFormat: Using read commited transaction isolation
17/11/10 13:51:12 INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN(id), MAX(id) FROM (select id,name,deg from emp where id>1202 and (1 = 1) ) AS t1
17/11/10 13:51:12 INFO mapreduce.JobSubmitter: number of splits:3
17/11/10 13:51:14 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1510279795921_0012
17/11/10 13:51:18 INFO impl.YarnClientImpl: Submitted application application_1510279795921_0012
17/11/10 13:51:19 INFO mapreduce.Job: The url to track the job: http://server71:8088/proxy/application_1510279795921_0012/
17/11/10 13:51:19 INFO mapreduce.Job: Running job: job_1510279795921_0012
17/11/10 13:52:19 INFO mapreduce.Job: Job job_1510279795921_0012 running in uber mode : false
17/11/10 13:52:19 INFO mapreduce.Job: map 0% reduce 0%
17/11/10 13:53:23 INFO mapreduce.Job: map 33% reduce 0%
17/11/10 13:54:19 INFO mapreduce.Job: map 67% reduce 0%
17/11/10 13:54:20 INFO mapreduce.Job: map 100% reduce 0%
17/11/10 13:54:24 INFO mapreduce.Job: Job job_1510279795921_0012 completed successfully
17/11/10 13:54:25 INFO mapreduce.Job: Counters: 31
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=374526
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=301
HDFS: Number of bytes written=61
HDFS: Number of read operations=12
HDFS: Number of large read operations=0
HDFS: Number of write operations=6
Job Counters
Killed map tasks=2
Launched map tasks=5
Other local map tasks=5
Total time spent by all maps in occupied slots (ms)=349539
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=349539
Total vcore-milliseconds taken by all map tasks=349539
Total megabyte-milliseconds taken by all map tasks=357927936
Map-Reduce Framework
Map input records=3
Map output records=3
Input split bytes=301
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=3013
CPU time spent (ms)=21550
Physical memory (bytes) snapshot=321351680
Virtual memory (bytes) snapshot=2528706560
Total committed heap usage (bytes)=52994048
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=61