线性回归实战案例一:多元素情况下广告投放效果分析步骤详解
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/121382191(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
2 线性回归
2.1 案例一:多元素情况下广告投放效果分析
数据集为广告投放营收数据。包含销售利润数据和与之相关联的投放渠道数据,比如电台投放信息,电视频道投放信息和报纸投放信息等三个因素。
2.1.1 模块加载与绘图布局样式设置
新建一个Jupyter notebook文件,命名为:线性回归分析-案例1-媒体投放.ipynb,然后在第一个cell中加载要使用到的模块和绘图相关的布局与样式,代码如下。
2.1.2 加载数据和数据筛选
数据集较为简单,只有四个字段,其中的利润字段为sale,为了更方便理解数值的大小,可以将sale中的数值扩大到15倍后形成新的字段为sale2,最后保留扩大后的字段,操作如下。

2.1.3 探索式数据分析(EDA)
数据集的内容是很丰富的,通过数据工具箱中的相关工具对数据集进行预览和汇总,尝试使用pandas在df中的几个重要工具集进行数据查看,例如info(), isnull().sum(), describe(), value_counts()等
(1)首先看一下四个字段的基础信息,包括数据量和数据类型。

(2)接着进行各字段中的缺失值查看。如果有缺失值,需要进行缺失值处理,当前数据中并无数据缺失。
(3)然后都是数值字段,可以进行绘制统计表格。统计表格中包含了各字段中的均值、标准差、最小/最大值,以及四分位数。

(4)如果是分类型字段,可以使用value_couts()进行各类别之间的频数统计,当前数据集中的四个字段均为数值型,不适合使用该方法进行频数统计。
2.1.4 探究字段之间的关联性
实际数据中往往会出现有些数据呈现关联特性,有些数据其实没有关联。下面就是要采用sns.pairplot()方法来探究字段之间的关联性。下图中,y轴是作为因变量,x就是自变量,其中有三自变量一个因变量,所以绘制的图形共3个。利润和电视投放的效果之间呈现出比较明显的线性关系,而在广播投放中效果不是太明显,也有稍微线性的关系,但是最后利润和报纸之间是完全看不出来有相关性。

散点图形分布只能看出一个模糊的大概,具体量化的关联性,可以通过关联矩阵和热力图进行展示,首先就是corr()方法输出关系矩阵。

然后可以将输出的表格进行图形可视化,较为常用的就是热力图,直接利用上面的结果进行输出。

查看关联矩阵和热力图都只需要查看主对角线(左上角到右下角对角线)的一侧即可,由于这里探究的是利润与其它三个影响因素之间的关系,因此只需要看最后一行的数据即可。数值在(0.45,1)或者(-1,-0,45)之间,都可以认为两者具有相关性。比如上面的输出结果,利润和电视投放以及广播投放都是有关联,而与新闻报纸的投放没有关联
2.1.5 模型创建与拟合
(1)导入要使用的模型。sklearn 数据模块,这个模块内置了多达20多种常见的机器学习模型,使得用户在使用模型时无需自行设计或定义模型可以做到开箱即用。

(2)创建模型lm1,此时的模式没有任何数据接入,所以没有功能,简单理解为智商为0 的小白。

(3)数据集拆分。把数据分成两个部分,第一个部分是让机器模型需要学习的数据,此处指的是特征数据(对应X),还有一部分是指的标签数据(对应Y)。
-
特征数据(Feature)就是非结果数据,在本例中,除了最后的销售额以外的字段,都是特征数据,可能不同的特质强弱关系不同,但是都是属于特征范畴。
-
标签数据(Lable)就是结果数据,在回归类模型中,就是一个数据数组,在分类模型中,就是归属于哪一类。
数据集拆分结果如下,一般对于X数据,直接采用双中括号的方式进行筛选,特别是实际数据中字段量特别多时。

分别查看对应的数据结果如下。

(4)模型拟合。已经初始化过模型,并且数据划分完毕后,就可以进行模型的拟合,即是让模型的智商从0 开始增加 。

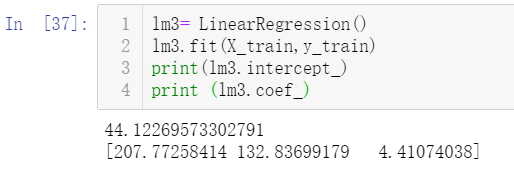
(5)输出结果。模型拟合完毕后,就可以输出最终的结果,包含了两个部分,第一部分就是截距,第二部分就是自变量前的系数。参照下面线性回归的算法模型公式,可以得到使用当前数据进行拟合后的模型结果。

2.1.6 数据标准化/缩放化
在得到模型算法公式的结果后,可能会有一个小问题,就是电视投放的影响因素与利润之间是有很强的关系(相关系数达到了0.78),但是这里的系数值才为0.69,反而电台投放的影响因素对应的系数高达了2.83。最后的一个因素报纸投放影响因素系数接近为0,说明该因素基本上不影响最后的利润。
解决上面问题就是进行数据标准化(统一缩放化),消除各字段之间数据取值范围的影响。接下来就是创建经过标准化的数据模型,对比前面没有进行处理的模型。

经过处理后,看一下advert2中后三个字段的统计分布表,核实数值是否都转化到了0-1范围区间。

数据转化完成后,划分数据集,重新定义X数据,Y数据保持不变,如下。

重新创建一个线性回归模型lm2,然后进行拟合数据,输出结果如下。此时各个影响因素前的系数就比较贴合根据线性相关性判断得到的结果。

2.1.7 模型验收
以上对于同一批数据创建了两个模型,一个是不进行数据处理,一个是对数据进行标准化(统一缩放化),但是都有一个共同点,就是把数据全部都拿来用作模型学习了,没有测试的数据,这种情况下就没有办法判断模型的好坏,也就说不上哪一个模型拟合的效果好了。
为了避免“记答案”的现象,即所有数据输入后,模型会都记住里面的内容,再拿其中的数据再测试,都是学习过的内容,会影响模型的稳定性,无法适应新数据的加入,故需要将数据进行测试集和训练集的划分。此部分为固定的操作,当指定好特征数据X和标签数据Y后(可以选择未处理的数据,也可以选择标准化后的数据,这里选择后者进行模型lm3的创建),直接加载train_test_split模块,然后指定一个切割的比例大小和随机状态,系统就会把数据分割完毕。

再次进行模型的创建和拟合,结果如下。需要特别注意,此处添加到fit里面的数据为训练数据集中的X和Y,需要和后面预测中传入的数据以及模型评估中的数据进行区分开。
模型预测。由于存在测试集,就可以那已经训练好的模型lm3进行预测测试集中数据对应的结果,输出如下。

预测结果的好坏需要有一个衡量的标准,因此引用评估模型的判定方法,均方差和R方,其中均方差代表着预测数据和实际数据间的平均差额,而R方代表着模型的拟合能力。

模型的R方快接近了0.9,说明模型对于数据拟合的很好。但是对于误差的评估,并不能单独看一个模型的结果,需要多个模型的结果进行比对,差值越小说明模型越好。此外关于误差一般有三个方式进行衡量(比对时候选择一种即可),具体公式和含义解释如下。
- Mean Absolute Error (MAE) 是预测数据和实际数据间的平均差额(绝对值):
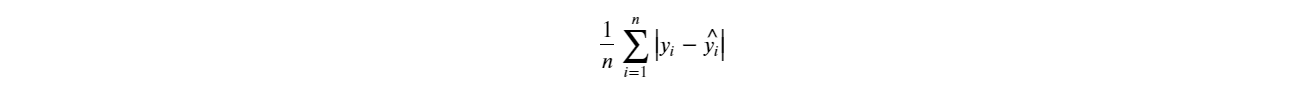
- Mean Squared Error (MSE) 是预测数据和实际数据间的平均差额(平方值):
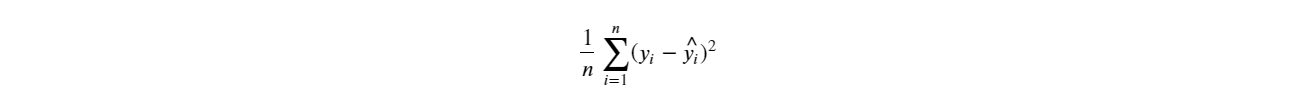
- Root Mean Squared Error (RMSE) 是预测数据和实际数据间的平均差额(平方值的开根号版本):
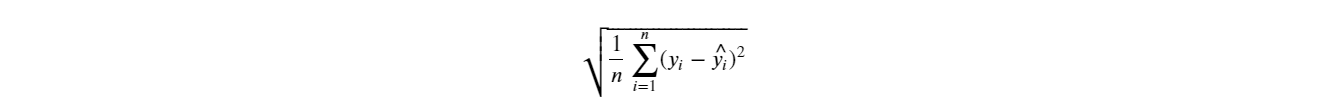
2.1.8 模型对比
接下来就是再创建一个模型进行误差值和R方的比对,顺便可以看一下数据不处理和经过标准化(统一缩放化)后模型之间的差别。
重新指定X数据,Y不需要改变,然后在进行分割数据时候要注意分割的比例和随机状态不能发生变化。

接着就是进行数据预测和模型误差求解与模型拟合能力的判断,输出结果如下。

对比两个模型最后的得分,可以说对于当前数据集,不管是不是进行标准化(统一缩放化)处理,最后几乎都不会影响模型的误差和模型的拟合程度。
