手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/121157833(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
1 背景
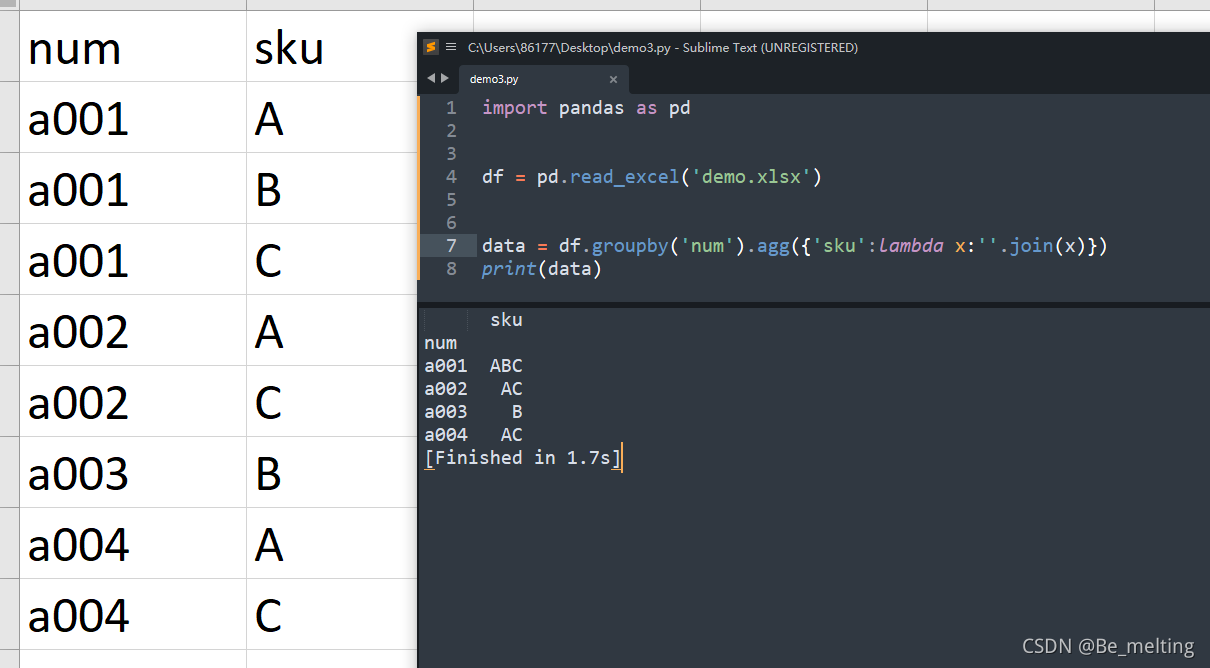
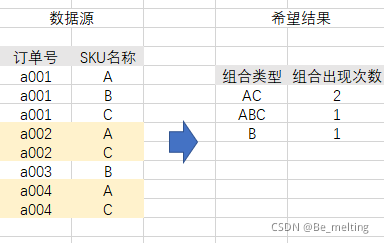
在进行数据分析过程中,有人会有如下的需求,就是统计相同编号下的sku情况,具体需求如下
给出的具体示意流程如下
仔细观察一下,其实就是pandas中explode操作方法的逆应用,explode就是将一行单元格中的数据拆解成为多行数据,而这里的需求就是将多行数据合并成为一个单元格数据,刚好是相反的操作
2 问题解决
代码很简单,就是一行处理的过程即可
import pandas as pd
df = pd.read_excel('demo.xlsx')
data = df.groupby('num').agg({
'sku':lambda x:''.join(x)})
print(data)
输出结果如下: