深度学习是机器学习的一部分,机器学习又是人工智能的一部分。人工智能是让机器能够模仿人类行为的技术。
- 人工智能的实现方法有很多,专家系统,数学建模,等一系列能够解决问题的都叫做人工智能AI。
- 机器学习是一种通过数据训练实现AI的技术。机器学习与深度学习的主要区别在于特征的选取,机器学习的特征是已知的,经过算法处理,从中得到特征之间的规律就是机器学习的主要内容。
- 深度学习是一种受人脑结构启发(人工神经网络)的机器学习。医学研究发现人脑认识事物是将看到的事物经过多层的抽象得到结果的,因此深度学习也通过多层“神经元”的抽象得到最终结果。深度学习的特征是由自身学习而来的,而非机器学习那样直接给出的。
深度学习的发展历程:
- 浅层模型如Boosting(提升方法)、Logistic回归、SVM等基于统计学习理论的方法,是具有一层隐层节点或不含隐层节点的学习模型,被称为浅层模型。
- 1986年Rumelhart等人提出了人工神经网络的反向传播算法,掀起了神经网络在机器学习中的热潮。由于神经网络中存在大量的参数,存在容易发生过拟合、训练时间长的缺点。但对于传统方法仍具有较大优越性。
- 2006年,Hinton提出了深度学习,两个主要的观点是:
- 多隐层的人工神经网络具有优异的特征学习能力,学习到的特征更能刻画数据的本质有利于可视化或分类。
- 深度神经网络在训练上的难度,可以通过逐层无监督训练有效克服。
深度学习取得成功的原因:
- 大规模数据(例如ImageNet):为深度学习提供了好的训练资源
- 计算机硬件的飞速发展:特别是GPU的出现,使得训练大规模上网络成为可能
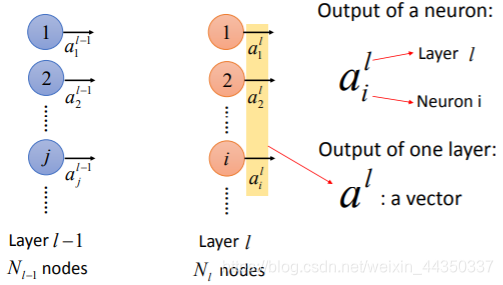
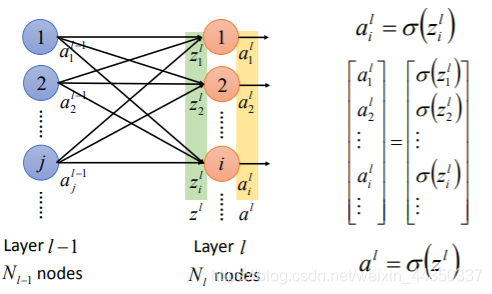
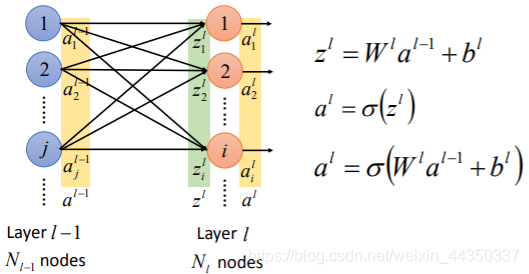
人工神经网络的组成:
- 首先原始数据通过输入层进入人工神经网络。(例如一张784像素的图片就可以通过输入层的784个x进入到人工神经网络中)
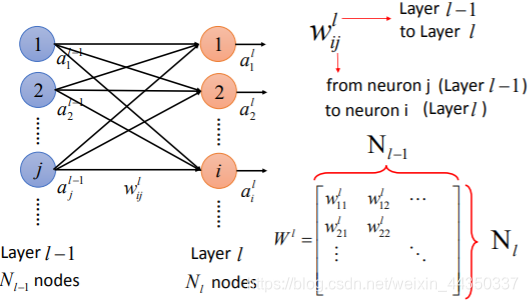
- 输入层与隐藏层的第一层全连接,每个连接成为一个通道,每个通道又有一个权重,因此称为加权通道。
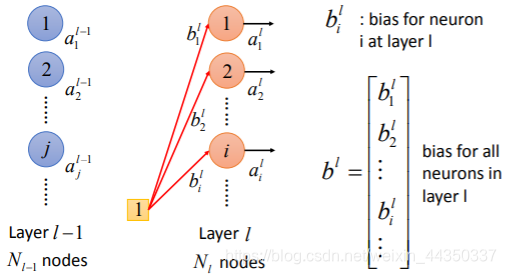
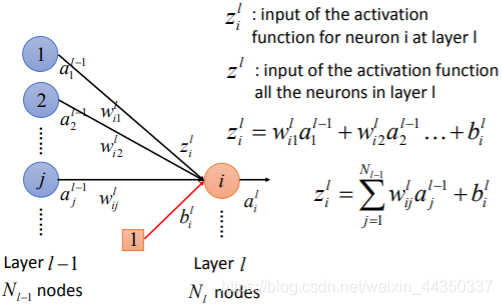
- 输入层的x乘以权重加上偏差bias,然后使用非线性变化的激活函数确定神经元是否被激活。 激活的神经元继续将信息传递给后续层。
- 直到倒数第二层,倒数第二层的输出会激活一个神经元,而这个神经元对应的结果就是分类结果。
- 利用反向传播(Back Propagation)调整权重与偏差,使Loss最低,产生合理的神经网络。
监督学习和无监督学习:
- 监督学习(supervised learning)的训练集要求包括输入输出,也可以说是特征和目标。训练集中的目标是由人标注的。监督学习就是最常见的分类问题。监督学习得到的函数可以在新的输入到来时,得到拟合的标注结果的输出。
- 无监督学习(unsupervised learning)输入数据没有被标记,也没有确定的结果。样本数据类别未知,需要根据样本间的相似性对样本集进行聚类试图使类内差距最小化,类间差距最大化。
神经网络的特点:
- 监督类算法
- 层层连接过滤信息,模型内部可用参数多,模型性能出色
- 激活函数非线性变化,理论上可以拟合任意分布
- 参数多意味着训练慢,训练难(overfit,underfit)
- 网络模型对超参数敏感
卷积神经网络(重复,倍率,叠加):
- 为解决全连接神经网络训练慢,训练难的问题,将全连接改为卷积,采用局部连接的方式,对特定输入进行传播(权力划分,规则共享),尽可能减少模型参数。
- 卷积神经网络通过将图片经过卷积层,池化层,卷积层,池化层,不断抽象进行特征提取,用于目标分类,目标识别,图片分割,关键点检测等。
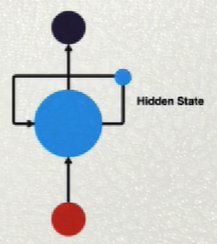
循环神经网络:
- 为了输入层能够更好的了解数据,输入层经过相互的交流,在将得出的结果反馈给下一层。
批量归一化(Batch Normalization):
- 为了下一层更好的处理所接收到的数据,我们通过归一化处理Normalization将feature map进行归一化,加速网络的收敛。
dropout层:
- 在输出层的上一层,用于随机失活神经元减少训练参数,减少训练时间,降低overfit的可能。事实上,dropout层将随机失活提取的图片特征,也就是说我们要求模型能够对最重要的特征给予更大的权重。对于人脸识别来说,人脸的特征是最重要的,而所穿衣服头发可以通过dropout降低其权重,不能是换了一个衣服就认不出来人了,增加鲁棒性。
BP算法:
- 用于人工神经网络的反向传播算法也叫Back Propagation算法
- 利用BP算法可以让一个人工神经网络模型从大量训练样本中学习统计规律,从而对未知事件做预测。
多层感知机(Multi-layer Perceptron):
- 在深度学习早期,浅层机器学习模型的的一种,只包含曾隐层节点的人工神经网络就被成为多层感知机。
ImageNet:
- ImageNet是一个项目工程,而非神经网络。ImageNet项目是一个用于视觉对象识别软件研究的大型可视化数据库。超过1400万的图像URL被ImageNet手动注释,以指示图片中的对象。在至少一百万个图像中,还提供了边界框。ImageNet包含2万多个类别。ImageNet项目每年会举办一次ImageNet大规模视觉识别挑战赛(ILSVRC)用以正确分类检测事物和场景。2018年器,ImageNet建立使用自然语言对3D对象进行分类的数据用于机器人导航到增强现实的应用。
深度学习的特点:
- 深度学习是处理非结构化数据的最有效方式;
- 神经网络需要大量的数据来训练;
- 训练神经网络需要图形处理单元(GPU)与CPU相比,它们有数千个核心(course);
- 深度神经网络一般需要数小时甚至数月才能训练完成,训练时间随着网络中的数据量和层数而增加;
深度学习可通过学习一种深层非线性网络结构,实现复杂函数逼近,表征输入数据分布式表示,并展现了强大的从少数样本集中学习数据集本质特征的能力。(多层的好处是可以用较少的参数表示复杂的函数)
VGG
- VGG(visual geometry group,超分辨率测试序列)
- 是一个深度的卷级神经网络,具备CNN的所有功能,常用来提取特征图像
深度学习的三步骤:
- Neural Network 神经网络,一个神经网络的功能实现是由多个简单的功能组成,也就是多个神经元。
- Cost Function 损失函数,用于判别参数的好坏。
- Optimization 最优化,寻找最优的参数。
全连接层:
- Neuron神经元;Vector矢量;bias偏置;activation function激活函数;