重点:SQL语言的逻辑执行顺序和普通的编程语言不同,下面进行详细学习
1.逻辑查询处理
首先创建一张名为customers的表
CREATE TABLE `customers` (
`customer_id` varchar(10) NOT NULL,
`city` varchar(10) NOT NULL,
PRIMARY KEY (`customer_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
插入数据:
insert into customers select '163','HangZhou';
insert into customers select '9you','ShangHai';
insert into customers select 'TX','HangZhou';
insert into customers select 'baidu','HangZhou';
然后创建一个名为orders的表:
create table orders(
order_id int not null auto_increment,
custormer_id varchar(10),
primary key(order_id)
)engine=innodb;
插入数据:
insert into orders select null,'163';
insert into orders select null,'163';
insert into orders select null,'9you';
insert into orders select null,'9you';
insert into orders select null,'9you';
insert into orders select null,'TX';
insert into orders select null,null;
1.在一个完整的SQL语句:
SELECT c.customers_id,count(o.order_id) AS total_orders
FROM customers as c
LEFT JOIN orders as o
ON c.customer_id=o.customer_id
WHERE c.city='HangZhou'
GROUP BY c.customer_id
HAVING count(o.order_id)<2
ORDER BY total_orders DESC;
中,各个子句的逻辑执行顺序如下:
1)FROM:首先对FROM子句中的左表和右表执行笛卡尔积产生虚拟表VT1
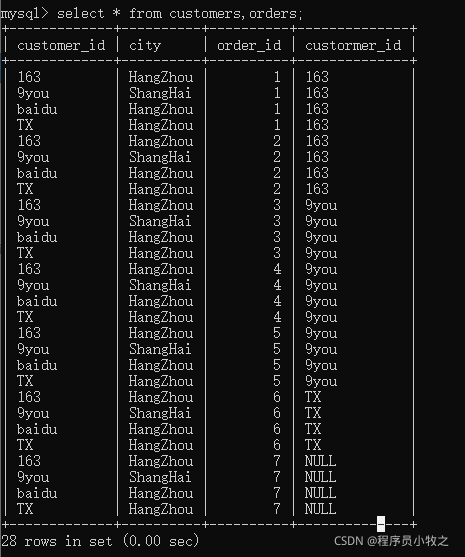
2)ON: 然后对虚拟表VT1应用ON筛选,只有符合ON条件的行才会被插入虚拟表VT2中:
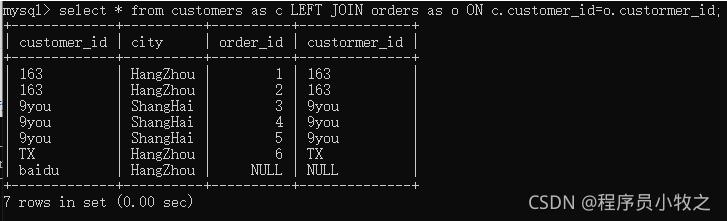
3)JOIN:如果指定了OUTER LEFT ,那么保留表中未匹配的行作为外部行添加到虚拟表VT2中,产生虚拟表VT3。
如果FROM子句包含两个以上的表,则对上一个连接生成的结果表VT3和下一个表重复执行步骤1)——步骤3),直到处理完所有的表为止。
4)WHERE: 对虚拟表VT3中应用WHERE过滤条件,只有符合条件的行才会被插入VT4中

5)GROUP BY:根据GROUP BY中子句中的列,对VT4中的记录进行分组操作,产生VT5

6)CUBE|ROLLUP:对表VT5进行CUBE或ROLLUP操作,产生VT6.
由于这一步上述例子没有所以跳过。VT6=VT5
7)HAVING:对虚拟表中VT6应用HAVING过滤器,只有符合条件的记录才被插入VT7中。

8)SELECT:第二次执行SELECT操作,选择指定的列,插入到虚拟表VT8中。

9)DISTINCT:去除重复数据,产生虚拟表VT9

10)ORDER BY :将虚拟表VT9中的记录按照指定列进行排序操作,产生虚拟表VT10

11)LIMIT:取出指定行记录,产生虚拟表VT11,返回给用户。

上述11个步骤就是一个完整的SQL中各个子句的运行步骤和最终查询结果的由来。
2.物理查询处理
第一节介绍了执行查询应该得到什么样的结果,但是数据库本身也许并不会完全按照逻辑查询的步骤进行查询。
我们知道Mysql数据结构中存在 分析器和优化器两个组件 ,分析器的工作就是分析SQL语句,而优化器的工作就是对这个SQL进行优化,
选择一条最优的途径来选取数据,但是必须保证物理查询的结果和逻辑查询的结果是一致的。
我们现在只需知道:物理查询会根据索引来进行优化,物理查询可以利用表上的索引来缩短SQL语句运行的时间,以此来提高数据库的整体性能。