目录
1. 前言
本专题我们开始学习虚拟文件系统VFS的相关内容。本专题主要参考了《存储技术原理分析》、ULA、ULK的相关内容。本文主要记录page cache写回的过程。page cache的写回主要发生在如下几个场景下:
- 定时器周期性回写
主要通过定时器周期性的触发回写线程进行回写,定时器时间到时会检查如下两种情况并执行写回:
(1) 超时回写:由于长时间没有执行回写,因担心数据丢失而发生的回写;
(2) 后台回写:检查page cache中脏页数量,如果超过阀值而发生的回写; - 进程通过write系统调用触发的回写
用户调用write()或者其他写文件接口时,在写文件的过程中,产生了脏页后会调用balance_dirty_pages调节平衡脏页的状态. 假如脏页的数量超过了阀值会强制进行脏页回写,实际仍然是触发后台回写线程进行回写; - sync系统调用
kernel版本:5.10
平台:arm64
注:
为方便阅读,正文标题采用分级结构标识,每一级用一个"-“表示,如:两级为”|- -", 三级为”|- - -“
2. 主要数据结构
-
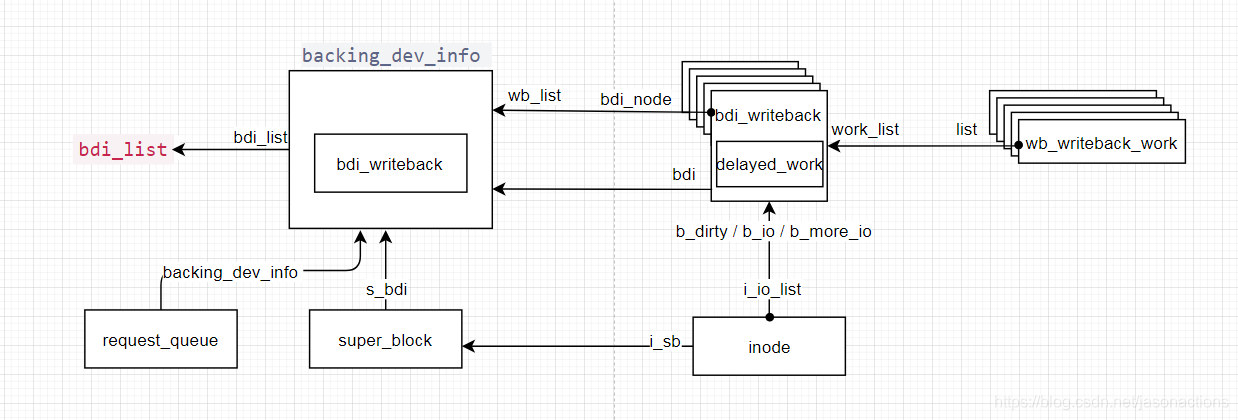
backing_dev_info
Backing Device Info,用来描述非易失存储设备的相关信息。Bdi是Writeback机制的基础,它的作用是初始化Writeback功能,每一个Bdi代表一个设备,Writeback的时候也会根据Bdi的不同,将数据写入到不同的设备当中。其在创建后会加入到全局bdi_list链表,其内嵌bdi_writeback为root bdi_writeback。每个bdi可有多个bdi_writeback,通过bdi_node链接件连入bdi的wb_list链表。 -
bdi_writeback
bdi_writeback结构用于管理一个块设备所有的writeback任务,核心成员是struct list_head work_list,它保存了将要做writeback的任务,任务对应struct wb_writeback_work结构。通过内置的delayed_work线程遍历wb.work_list所有的work,然后将其执行。bdi_writeback维护着三个链表:b_ditty链表用于存放dirty的inode;b_io存放将要处理的dirty的inode;b_more_io存放更多的dirty inode。inode的i_io_list连入如上三个链表中的一个或多个。通过writeback_inodes_wb和wb_writeback将b_dirty链表转移到b_io链表。 -
wb_writeback_work
代表一次写回任务,相当于writeback_control的子集;writeback_control是最终控制writeback操作,它的部分参数来源于wb_writeback_work
3. bdi初始化
struct request_queue *blk_mq_init_queue_data(struct blk_mq_tag_set *set,void *queuedata)
|......
|--uninit_q = blk_alloc_queue(set->numa_node);
|.......
|--q->backing_dev_info = bdi_alloc(node_id);
|......
|--timer_setup(&q->backing_dev_info->laptop_mode_wb_timer,laptop_mode_timer_fn, 0);
Linux会存在多个块设备,也就是多个writeback的目的地。因此Linux会根据块设备的数目,初始化多个bdi结构体。每一个块设备进行初始化的时候,会调用blk_alloc_queue 函数分配bdi, 并进行初始化,此处主要是创建了定时器用于定时触发回写线程执行回写。
void device_add_disk(struct device *parent, struct gendisk *disk,const struct attribute_group **groups)
\--__device_add_disk(parent, disk, groups, true);
|......
\--bdi_register(bdi, "%u:%u", MAJOR(devt), MINOR(devt));
\--bdi_register_va(bdi, fmt, args);
|--struct device *dev;
| struct rb_node *parent, **p;
|--dev = device_create(bdi_class, NULL, MKDEV(0, 0), bdi, bdi->dev_name);
|--cgwb_bdi_register(bdi)
| |--list_add_tail_rcu(&bdi->wb.bdi_node, &bdi->wb_list);
|--bdi->dev = dev;
|--bdi->id = ++bdi_id_cursor;
|--p = bdi_lookup_rb_node(bdi->id, &parent);
| rb_link_node(&bdi->rb_node, parent, p);
| rb_insert_color(&bdi->rb_node, &bdi_tree);
| //添加到全局bdi_list
\--list_add_tail_rcu(&bdi->bdi_list, &bdi_list);
device_add_disk->bdi_register将blk_alloc_queue中分配的bdi加入到全局变量 bdi_list 这个列表中。
4. 标记inode为dirty的时机
void __mark_inode_dirty(struct inode *inode, int flags)
|--struct super_block *sb = inode->i_sb;
| int dirtytime;
|--dirtytime = flags & I_DIRTY_TIME;
|--if ((inode->i_state & flags) != flags)
| const int was_dirty = inode->i_state & I_DIRTY;
| inode_attach_wb(inode, NULL);
| if (flags & I_DIRTY_INODE)
| inode->i_state &= ~I_DIRTY_TIME;
| inode->i_state |= flags;
|--if (!was_dirty)
| struct bdi_writeback *wb;
| struct list_head *dirty_list;
| bool wakeup_bdi = false;
| if (inode->i_state & I_DIRTY)
| dirty_list = &wb->b_dirty;
| else
| dirty_list = &wb->b_dirty_time;
| wakeup_bdi = inode_io_list_move_locked(inode, wb,dirty_list);
| if (wakeup_bdi && (wb->bdi->capabilities & BDI_CAP_WRITEBACK))
| wb_wakeup_delayed(wb);
__mark_inode_dirty将inode标记为dirty,标记dirty的page最终会存放到wb->b_dirty链表或wb->b_dirty_time
举例如下几个函数中会调用__mark_inode_dirty:
- set_page_dirty
标记整个page为dirty - mark_buffer_dirty
标记单个buffer为dirty - generic_write_end
这种情况是最常见的,比如我们通过write系统调用写文件时,最后写入page cache后,就形成了脏页 - update_time
这种情况一般就是更新文件的各个时间,比如access time、modify time和change time,这需要更新文件的metadata
5. writeback的场景
5.1 周期性回写
在前述bdi初始化及block多队列分析 - 2. block多队列的初始化 部分我们知道:
blk_mq_init_queue_data -> blk_alloc_queue时会创建定时器,如下:
timer_setup(&q->backing_dev_info->laptop_mode_wb_timer,laptop_mode_timer_fn, 0);
此定时器就是周期性触发写回线程的,它的定时处理函数为laptop_mode_timer_fn
void laptop_mode_timer_fn(struct timer_list *t)
| //获取对应块设备request_queue的bdi
|--struct backing_dev_info *backing_dev_info = from_timer(backing_dev_info, t, laptop_mode_wb_timer);
|--wakeup_flusher_threads_bdi(backing_dev_info, WB_REASON_LAPTOP_TIMER);
|--__wakeup_flusher_threads_bdi(backing_dev_info, WB_REASON_LAPTOP_TIMER);
|--struct bdi_writeback *wb;
|--if (!bdi_has_dirty_io(bdi))
| return;
|--list_for_each_entry_rcu(wb, &bdi->wb_list, bdi_node)
wb_start_writeback(wb, reason);
|--test_and_set_bit(WB_start_all, &wb->state)
|--wb->start_all_reason = reason;
|--wb_wakeup(wb);
laptop_mode_timer_fn->wakeup_flusher_threads_bdi将会唤醒回写线程进行脏页回写,它会遍历全局bdi_list每个bdi,此处每个bdi对应一个块设备,最终会通过wb_wakeup唤醒回写进程
static void wb_wakeup(struct bdi_writeback *wb)
{
spin_lock_bh(&wb->work_lock);
if (test_bit(WB_registered, &wb->state))
mod_delayed_work(bdi_wq, &wb->dwork, 0);
spin_unlock_bh(&wb->work_lock);
}
最终会调度到dwork线程,根据前述每个bdi_writeback 下都有一个dwork线程,它是在
blk_mq_init_queue_data -> blk_alloc_queue->bdi_alloc->bdi_init->cgwb_bdi_init->wb_init中初始化:
INIT_DELAYED_WORK(&wb->dwork, wb_workfn);
此处可见针对每一个磁盘都会创建一个dwork线程,线程处理函数为wb_workfn
/*
* Handle writeback of dirty data for the device backed by this bdi. Also
* reschedules periodically and does kupdated style flushing.
*/
void wb_workfn(struct work_struct *work)
{
struct bdi_writeback *wb = container_of(to_delayed_work(work),
struct bdi_writeback, dwork);
long pages_written;
set_worker_desc("flush-%s", bdi_dev_name(wb->bdi));
current->flags |= PF_SWAPWRITE;
//>>>>>> 有足够的worker处理
if (likely(!current_is_workqueue_rescuer() ||
!test_bit(WB_registered, &wb->state))) {
/*
* The normal path. Keep writing back @wb until its
* work_list is empty. Note that this path is also taken
* if @wb is shutting down even when we're running off the
* rescuer as work_list needs to be drained.
*/
do {
pages_written = wb_do_writeback(wb);
trace_writeback_pages_written(pages_written);
} while (!list_empty(&wb->work_list));
//>>>>>> 如果没有足够的worker去处理writeback,那么就同步处理
} else {
/*
* bdi_wq can't get enough workers and we're running off
* the emergency worker. Don't hog it. Hopefully, 1024 is
* enough for efficient IO.
*/
pages_written = writeback_inodes_wb(wb, 1024,
WB_REASON_FORKER_THREAD);
trace_writeback_pages_written(pages_written);
}
if (!list_empty(&wb->work_list))
wb_wakeup(wb);
else if (wb_has_dirty_io(wb) && dirty_writeback_interval)
wb_wakeup_delayed(wb);
current->flags &= ~PF_SWAPWRITE;
}
dwork线程的处理函数为wb_workfn,wb_workfn首先判断当前workqueue能否获得足够的worker进行处理,如果能则将bdi->wb上所有work全部提交,它会处理每个挂靠在wb->work_list链表上的wb_writeback_work;否则只提交一个work并限制写入1024个pages。正常情况下通过调用wb_do_writeback函数处理回写。
注:什么时候会向wb->work_list链表上挂靠wb_writeback_work呢?主要通过wb_queue_work进行挂靠,而wb_queue_work分别在writeback_inodes_sb和sync_inodes_sb中会调用。
/*
* Retrieve work items and do the writeback they describe
*/
static long wb_do_writeback(struct bdi_writeback *wb)
{
struct wb_writeback_work *work;
long wrote = 0;
//设置状态为正在运行
set_bit(WB_writeback_running, &wb->state);
while ((work = get_next_work_item(wb)) != NULL) {
trace_writeback_exec(wb, work);
wrote += wb_writeback(wb, work);
finish_writeback_work(wb, work);
}
/*
* Check for a flush-everything request
*/
//检查是否全部的dirty的数据已经写入,wb_do_writeback->wb_check_start_all 清除WB_start_all 标志
wrote += wb_check_start_all(wb);
/*
* Check for periodic writeback, kupdated() style
*/
//固定间隔,定期进行writeback
wrote += wb_check_old_data_flush(wb);
//脏页达到一定比例, 后台writeback
wrote += wb_check_background_flush(wb);
clear_bit(WB_writeback_running, &wb->state);
return wrote;
}
wb_do_writeback为写回的正常路径
-
wb_writeback:它会处理每个挂靠在wb->work_list链表上的wb_writeback_work,执行回写
-
wb_check_start_all:检查是否全部的dirty的数据已经写入,如果没有它会清除WB_start_all 标志
-
wb_check_background_flush:脏页达到一定比例, 后台writeback
wb_writeback
static long wb_writeback(struct bdi_writeback *wb,struct wb_writeback_work *work)
|--struct blk_plug plug;
|--blk_start_plug(&plug);
|--for (;;)
| if (list_empty(&wb->b_io))
| // 将需要被wb清理的inode都移动到wb->b_io中,设置一个wb是dirty,
| // 然后根据wb->tot_bandwidth增加wb->bdi->tot_bandwidth
| queue_io(wb, work, dirtied_before);
| //如果含有superblock,那就执行这个,大部分执行这个
| if (work->sb)
| progress = writeback_sb_inodes(work->sb, wb, work);
| else
| progress = __writeback_inodes_wb(wb, work);
| // 更新处理的带宽,更新dirty io数目等
| wb_update_bandwidth(wb, wb_start);
| if (list_empty(&wb->b_more_io))
| break;
| inode = wb_inode(wb->b_more_io.prev);
| inode_sleep_on_writeback(inode);
|--blk_finish_plug(&plug);
|--return nr_pages - work->nr_pages; // 表示写了多少个页
wb_check_start_all
static long wb_check_start_all(struct bdi_writeback *wb)
|--if (!test_bit(WB_start_all, &wb->state))
| return 0;
|--nr_pages = get_nr_dirty_pages();
| //还有dirty的数据没有写入
|--if (nr_pages)
struct wb_writeback_work work = ...
nr_pages = wb_writeback(wb, &work);
wb_check_start_all:检查是否全部的dirty的数据已经写入,如果没有它会清除WB_start_all 标志,最终也是调用wb_writeback写入
wb_check_old_data_flush
static long wb_check_old_data_flush(struct bdi_writeback *wb)
{
unsigned long expired;
long nr_pages;
/*
* When set to zero, disable periodic writeback
*/
if (!dirty_writeback_interval)
return 0;
expired = wb->last_old_flush +
msecs_to_jiffies(dirty_writeback_interval * 10);
/*没有达到设定的dirty_writeback_interval间隔时间,直接退出*/
if (time_before(jiffies, expired))
return 0;
wb->last_old_flush = jiffies;
nr_pages = get_nr_dirty_pages();
if (nr_pages) {
struct wb_writeback_work work = {
.nr_pages = nr_pages,
.sync_mode = WB_SYNC_NONE,
.for_kupdate = 1,
.range_cyclic = 1,
.reason = WB_REASON_PERIODIC,
};
//执行写入
return wb_writeback(wb, &work);
}
return 0;
}
wb_check_old_data_flush用于检测dirty page是否长时间没有写回,如果超过了dirty_writeback_interval 的间隔时间则执行写回操作。最终也是调用wb_writeback写入
wb_check_background_flush
static long wb_check_background_flush(struct bdi_writeback *wb)
{
if (wb_over_bg_thresh(wb)) {
struct wb_writeback_work work = {
.nr_pages = LONG_MAX,
.sync_mode = WB_SYNC_NONE,
.for_background = 1,
.range_cyclic = 1,
.reason = WB_REASON_BACKGROUND,
};
return wb_writeback(wb, &work);
}
return 0;
}
wb_check_background_flush:脏页达到一定比例, 后台writeback,最终也是调用wb_writeback写入
5.2 write系统调用触发的回写
用户调用write()或者其他写文件接口时,在写文件的过程中,产生了脏页后会调用balance_dirty_pages调节平衡脏页的状态. 假如脏页的数量超过了阀值会强制进行脏页回写,实际仍然是触发后台回写线程进行回写;
TODO
5.3 sync系统调用触发的回写
由sync系统调用引发的回写
TODO
参考文档
- http://www.ilinuxkernel.com/files/Linux.Kernel.Delay.Write.pdf
- VFS源码分析-Page Cache Writeback脏页回写机制
- vm内核参数之内存脏页dirty_writeback_centisecs和dirty_expire_centisecs
- io性能调优之page cache