多表
一个商城项目的数据库,需要有很多张表:用户表、分类表、商品表、订单表
单表的缺点
容易产生冗余
创建两张表
-- 创建部门表
-- 一方,主表
CREATE TABLE department(
id INT PRIMARY KEY AUTO_INCREMENT,
dep_name VARCHAR(30),
dep_location VARCHAR(30) );
-- 创建员工表
-- 多方 ,从表
CREATE TABLE employee(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
age INT,
dept_id INT
);
-- 添加2个部门
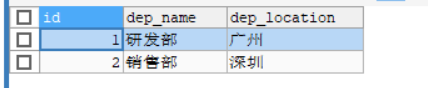
INSERT INTO department VALUES(NULL, '研发部','广州'),(NULL, '销售部', '深圳');
SELECT * FROM department;
-- 添加员工,dep_id表示员工所在的部门
INSERT INTO employee (ename, age, dept_id) VALUES ('张百万', 20, 1);
INSERT INTO employee (ename, age, dept_id) VALUES ('赵四', 21, 1);
INSERT INTO employee (ename, age, dept_id) VALUES ('广坤', 20, 1);
INSERT INTO employee (ename, age, dept_id) VALUES ('小斌', 20, 2);
INSERT INTO employee (ename, age, dept_id) VALUES ('艳秋', 22, 2);
INSERT INTO employee (ename, age, dept_id) VALUES ('大玲子', 18, 2);
SELECT * FROM employee;
则生成以下两张表
主表:
从表:
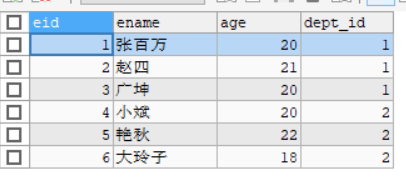
则我们称dept_id是外键字段,外键所在的表叫做从表
多表设计上存在的缺陷
插入一条不存在的部门id ,数据依然可以添加
INSERT INTO employee (ename,age,dept_id) VALUES('无名',35,3);
所以我们应设计合理的外键约束
外键约束
相关概念
- 外键约束可以让两张表之间产生一个对应关系,从而保证主从表的引用的完整性
- 外键指的是在从表中与主表的主键对应的字段
- 主表与从表:主表指主键id所在的表;从表就是外键所在的表,可有多个从表
添加外键约束
添加外键约束的语法格式
1. 创建表的时候添加外键
create table 表名(
字段...
[constraint][外键约束名] foreign key(外键字段名) references 主表(主键字段)
);
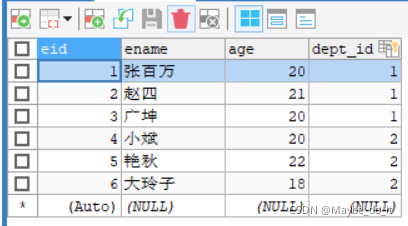
- 创建员工表, 添加外键
CREATE TABLE employee(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
age INT,
dept_id INT, -- 外键字段 指向了主表的主键
-- 添加外键约束
CONSTRAINT emp_dept_fk FOREIGN KEY(dept_id) REFERENCES department(id)
);
创建员工表成功并插入数据
当插入一条错误数据的时候
-- 插入一条有问题的数据 (部门id不存在)
-- Cannot add or update a child row: a foreign key constraint fails
INSERT INTO employee (ename, age, dept_id) VALUES ('错误', 18, 3);
就会报错
原因是添加外键约束之后 就会产生一个强制的外键约束检查 这里就是查询部门id是否存在 保证数据的完整性和一致性

2. 创建表之后添加外键
语法格式:
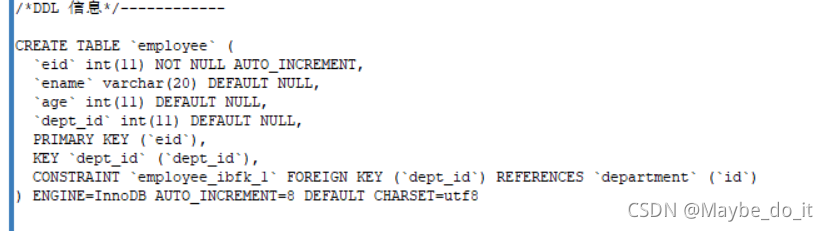
alter table 从表 add constraint emp_dept_fk foreign key(dept_id) references department(id)
-- 不写外键约束名
ALTER TABLE employee ADD CONSTRAINT FOREIGN KEY(dept_id) REFERENCES department(id);
不写外键约束名,会自动生成外键约束 employee_ibfk_1
删除外键约束
语法格式
alter table 从表 drop foreign key 外键约束名称
注意是删除外键约束名称,不是外键字段的名称
-- 删除 employee表中 外键
ALTER TABLE employee DROP FOREIGN KEY emp_dept_fk;
外键约束的注意事项
- 从表的外键类型必须与主表的主键类型一致
- 添加数据时,应该先添加主表的数据
- 删除数据时,先删除从表中数据
级联删除
指的是在删除主表数据的同时,可以删除与之相关的从表中数据
级联删除on delete cascade
具体做法是在创建表的时候添加级联删除
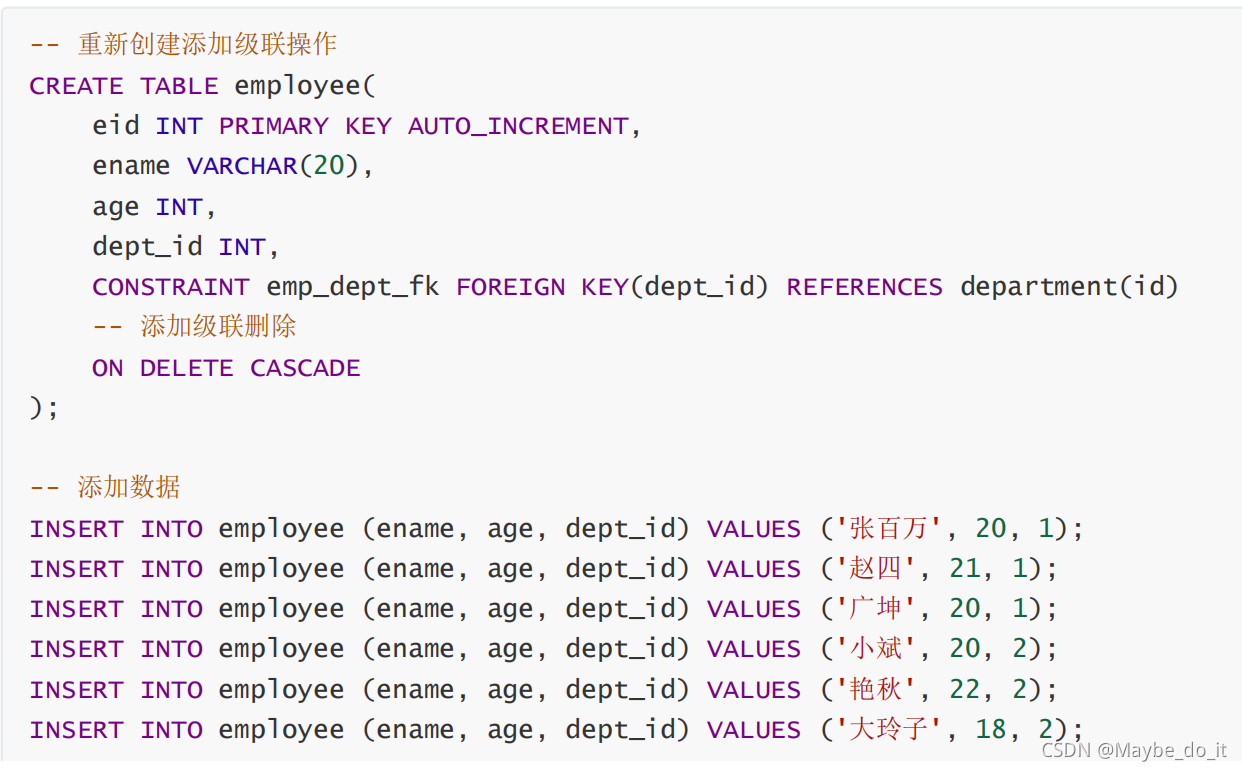
多表关系
表与表之间的三种关系
-
一对多(1:n):班级和学生,部门和员工
建表原则:在多的一方建立外键 指向一的一方的主键
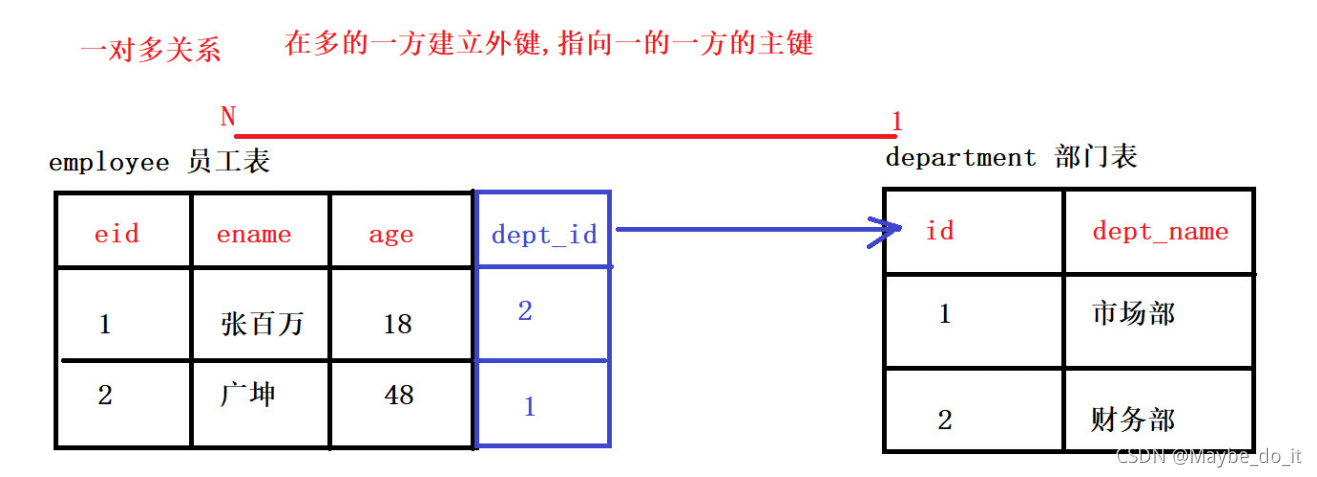
-
多对多(n:n):学生与课程,演员和角色
建表原则:需要创建第三张表,中间表中至少两个字段,这两个字段分别作为外键指向各自一方的主键。
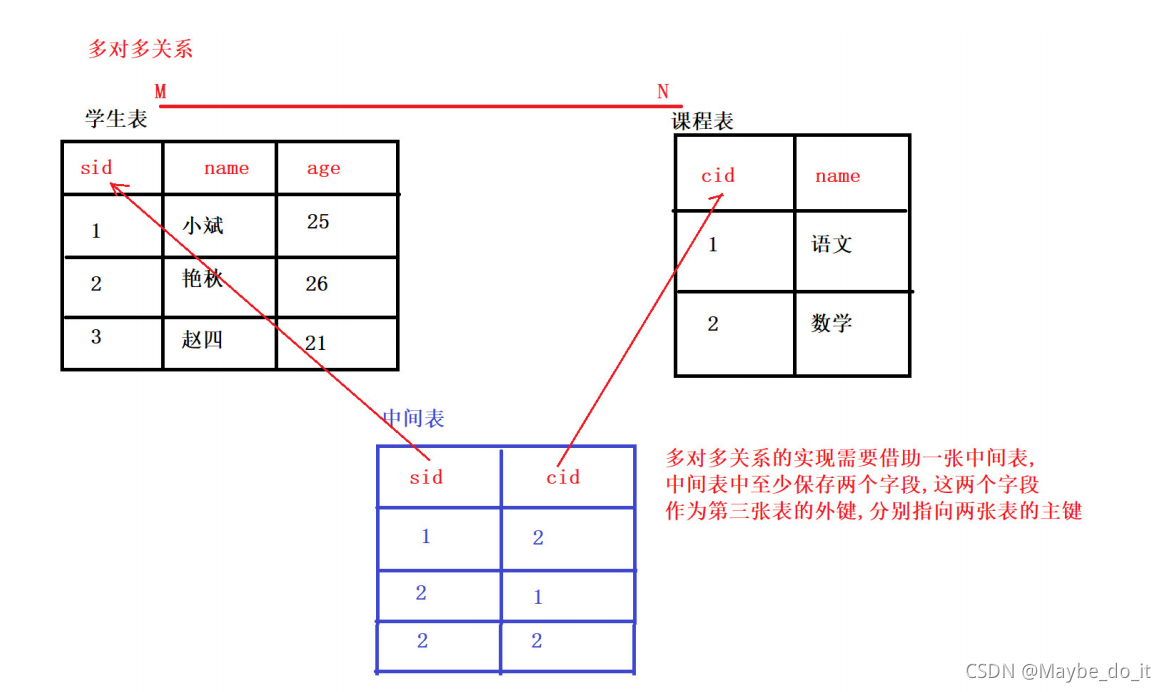
-
一对一关系(不常见,仅了解):身份证和人
外键唯一 主表的主键和从表的外键(唯一),形成主外键关系,外键唯一 UNIQUE
设计省市表(1对多)
一个省包含多个市
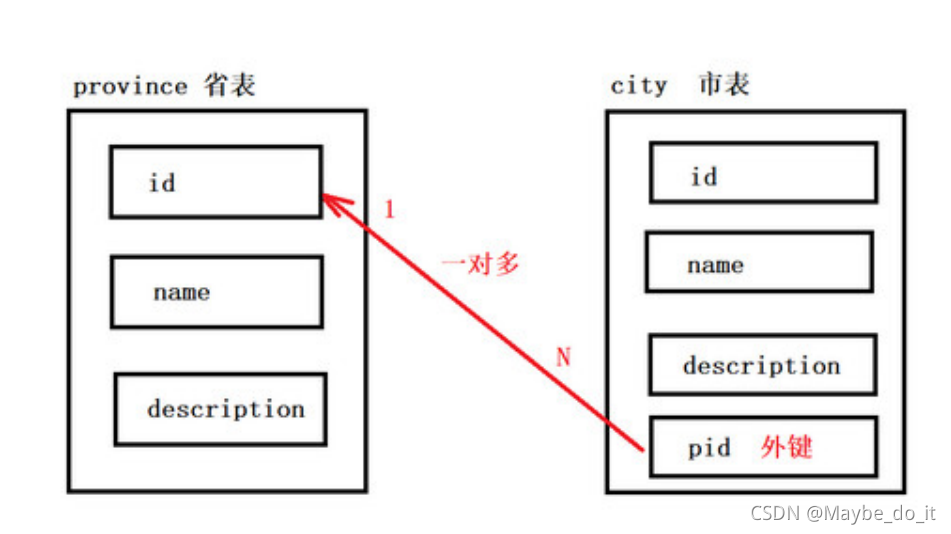
USE db3;
-- 创建省表 主表
CREATE TABLE province(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20),
description VARCHAR(20)
);
-- 市表 从表中外键指向主表中主键
CREATE TABLE city(
cid INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20),
description VARCHAR(20),
-- 创建外键 添加外键约束
pid INT,
FOREIGN KEY(pid) REFERENCES province(id)
)
设计演员与角色表(多对多关系)
一个演员可以饰演多个角色, 一个角色同样可以被不同的演员扮演
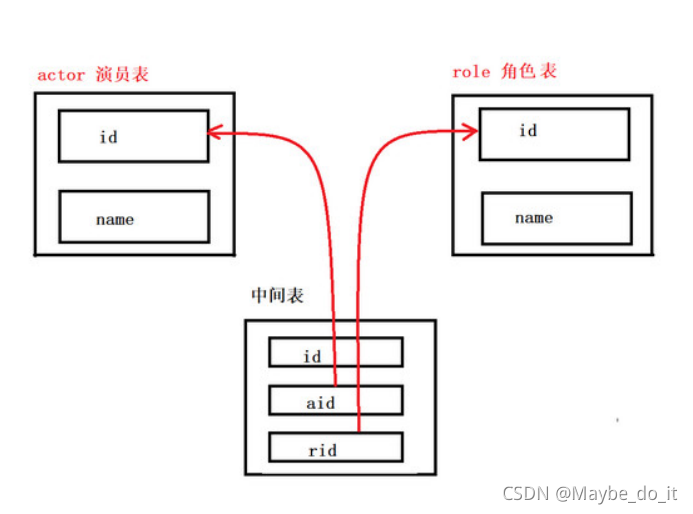
-- 多对多 演员与角色
-- 演员表
CREATE TABLE actor(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20)
);
-- 角色表
CREATE TABLE role(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20)
);
-- 创建中间表
CREATE TABLE actor_role(
-- 中间表自己的主键
id INT PRIMARY KEY AUTO_INCREMENT,
-- 指向actor 表的外键
aid INT,
-- 指向role 表的外键
rid INT
);
-- aid字段添加外键约束
ALTER TABLE actor_role ADD FOREIGN KEY(aid) REFERENCES actor(id);
-- rid字段添加外键约束
ALTER TABLE actor_role ADD FOREIGN KEY(rid) REFERENCES role(id);
多表查询
查询多张表,获取到需要的数据
比如 我们要查询家电分类下 都有哪些商品,那么我们就需要查询分类与商品这两张表
数据准备
先准备两张表
分类表 (一方 主表)
CREATE TABLE category (
cid VARCHAR(32) PRIMARY KEY ,
cname VARCHAR(50)
);
商品表 (多方 从表)
CREATE TABLE products(
pid VARCHAR(32) PRIMARY KEY ,
pname VARCHAR(50), price INT,
flag VARCHAR(2), #是否上架标记为:1表示上架、0表示下架
category_id VARCHAR(32),
-- 添加外键约束
FOREIGN KEY (category_id) REFERENCES category (cid)
);
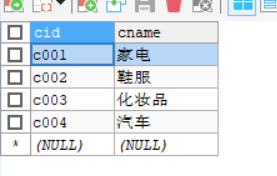
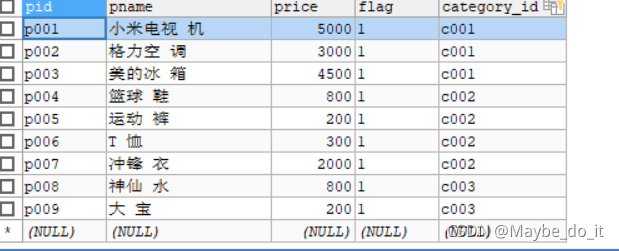
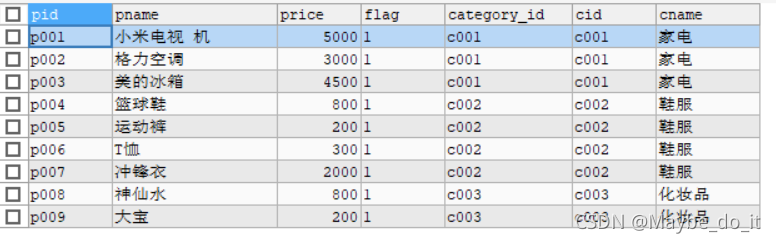
插入一些数据后两张表如下
#分类数据
INSERT INTO category(cid,cname) VALUES('c001','家电');
INSERT INTO category(cid,cname) VALUES('c002','鞋服');
INSERT INTO category(cid,cname) VALUES('c003','化妆品');
INSERT INTO category(cid,cname) VALUES('c004','汽车');
#商品数据
INSERT INTO products(pid, pname,price,flag,category_id) VALUES('p001','小米电视 机',5000,'1','c001');
INSERT INTO products(pid, pname,price,flag,category_id) VALUES('p002','格力空 调',3000,'1','c001');
INSERT INTO products(pid, pname,price,flag,category_id) VALUES('p003','美的冰 箱',4500,'1','c001');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p004','篮球 鞋',800,'1','c002');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p005','运动 裤',200,'1','c002');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p006','T 恤',300,'1','c002');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p007','冲锋 衣',2000,'1','c002');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p008','神仙 水',800,'1','c003');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p009','大 宝',200,'1','c003');
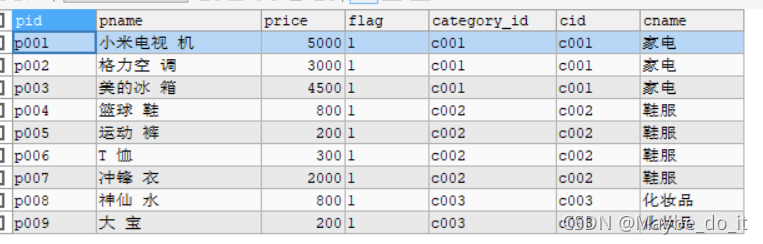
分类表
商品表
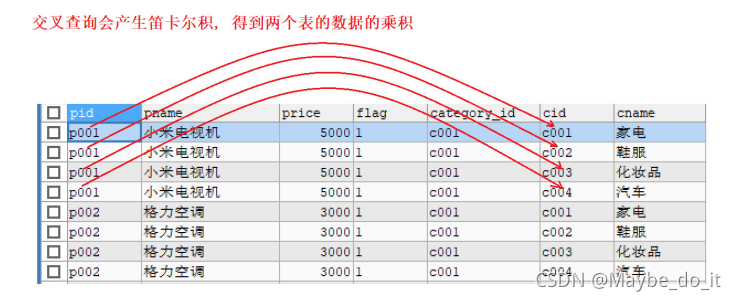
笛卡尔积
多表查询 交叉连接查询
SELECT * FROM products, category;
会直接得到一个产生一个笛卡尔积
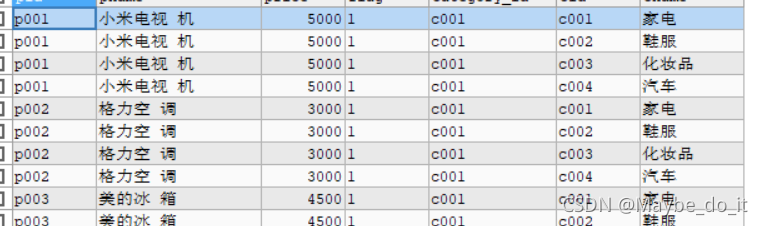
结果是有4×9=36条数据
这样的结果是不对的,我们需要按照一定的规则进行查询
多表查询方式一:内连接查询
特点: 通过特定条件 去匹配两张表中的内容,匹配不上的就不显示
隐式内连接
语法格式 select 字段名... from 左表,右表 where 连接条件
- 查询所有商品信息和对应的分类信息
SELECT * FROM products, category WHERE category_id = cid;
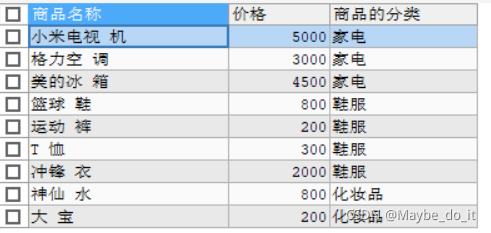
2. 查询商品表的商品名称 和 价格,以及商品的分类信息
通过给表起别名的方式, 方便我们的查询
-- 查询商品表的商品名称 和 价格,以及商品的分类信息
SELECT
p.`pname` AS "商品名称",
p.`price` "价格",
c.`cname` "商品的分类"
FROM products p, category c WHERE p.`category_id` = c.`cid`;
3. 查询 格力空调是属于哪一分类下的商品
SELECT
p.pname,
c.cname
FROM products p,category c WHERE p.category_id = c.cid AND p.pname = '格力空调';
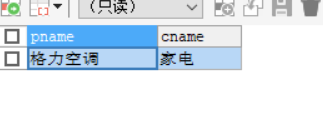
显式内连接
语法格式 select 字段名... from 左表 [inner] join 右表 on 连接条件
inner可以省略
- 查询所有商品信息和对应的分类信息
SELECT
*
FROM products p
INNER JOIN category c ON p.category_id = c.cid;
2. 查询鞋服分类下,价格大于500的商品名称和价格
表的连接条件一般都是 从表.外键 = 主表.主键
SELECT
p.pname,
p.price
FROM products p INNER JOIN category c ON p.category_id = c.cid
WHERE c.cname = '鞋服' AND p.price > 500;
多表查询方式二:外连接查询
外连接查询分为左外了解和右外连接
左外连接
关键字left [outer] join
语法格式
select 字段名 from 左表 left join 右表 on 连接条件
特点:以左表为基准,匹配右表中的数据,如果匹配上就显示
如果匹配不上,左表中的数据正常显示,右表数据显示为null
示例
-- 左外连接查询
SELECT * FROM category c LEFT JOIN products p ON c.`cid`= p.`category_id`;
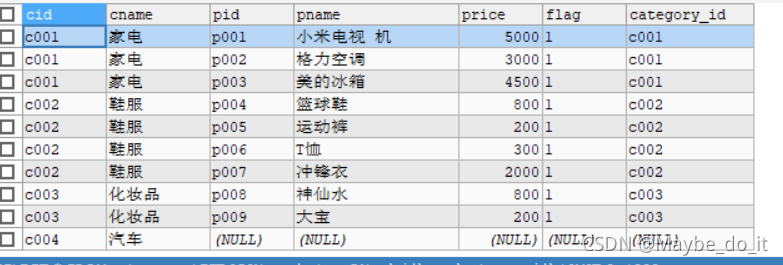
从最后一栏c004,可体现这就是以左表为基准的,products中并没有c004
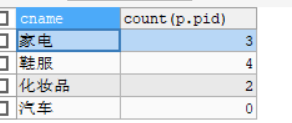
左外连接, 查询每个分类下的商品个数
步骤:
- 查询的表
- 查询的条件 分组 统计
- 查询的字段 分类 分类下商品个数信息
- 表的连接条件
SELECT
c.cname,
COUNT(p.pid)
FROM
-- 表连接
category c LEFT JOIN products p ON c.`cid`= p.`category_id`
-- 分组
GROUP BY c.cid;
右外连接查询
关键字 right [outer] join
语法格式
select 字段名 from 右表 left join 左表 on 条件
以右表为基准,匹配左边表中的数据,如果能匹配到,展示匹配到的数据
如果匹配不到,右表中的数据正常展示, 左边展示为null
-- 右外连接查询
SELECT * FROM products p RIGHT JOIN category c ON p.`category_id` = c.`cid`;
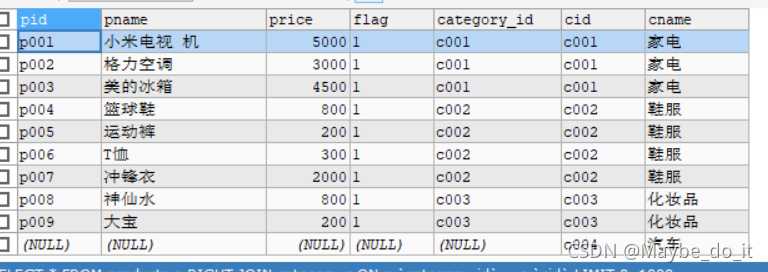
子查询 subQuery
一条select 查询语句的结果, 作为另一条 select 语句的一部分
特点:
- 子查询必须放在小括号中
- 子查询一般作为父查询的查询条件使用
-- 查询价格最高的商品信息
SELECT * FROM products WHERE price = (SELECT MAX(price) FROM products);
分类:
- where型子查询: 将子查询的结果, 作为父查询的比较条件
- from型子查询 : 将子查询的结果, 作为 一张表,提供给父层查询使用
- exists型子查询: 子查询的结果是单列多行, 类似一个数组, 父层查询使用 IN 函数 ,包含子查询的结果
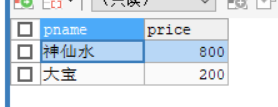
- 查询化妆品分类下的 商品名称 商品价格
#查询化妆品分类下的 商品名称 商品价格
-- 先查出化妆品分类的 id
SELECT cid FROM category WHERE cname = '化妆品';
-- 根据分类id ,去商品表中查询对应的商品信息
SELECT
p.pname,
p.price
FROM products p
WHERE p.category_id = (SELECT cid FROM category WHERE cname = '化妆品');
3. 查询小于平均价格的商品信息
#查询小于平均价格的商品信息
-- 查询平均价格
SELECT AVG(price) FROM products;
-- 获取小于平均价格的商品信息
SELECT
*
FROM products p
WHERE p.price < (SELECT AVG(price) FROM products);
子查询结果作为一张表
语法格式
SELECT 查询字段 FROM (子查询)表别名 WHERE 条件;
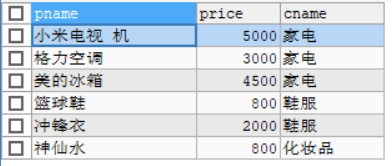
需求:查询商品中,价格大于500的商品信息,包括 商品名称 商品价格 商品所属分类名称
SELECT
p.pname,
p.price,
c.cname
-- 子查询作为一张表使用时 要起别名 才能访问表中字段 就像下面中的c
FROM products p INNER JOIN (SELECT * FROM category) c ON p.category_id = c.cid
WHERE p.price > 500;
子查询的结果是单列多行
子查询的结果是单列多行,作为父查询的in函数中的条件使用
语法格式:select 字段名 from 表名 where 字段 in(子查询)
需求:查询价格小于两千的商品,来自于哪些分类(名称)
-- 查询价格小于两千的商品,来自于哪些分类(名称)
-- 1.查询小于2000的商品分类id
SELECT DISTINCT category_id FROM products p WHERE p.price < 2000;
-- 2.根据分类id查询分类信息
SELECT * FROM category c
WHERE c.cid IN
(SELECT DISTINCT category_id FROM products p WHERE p.price < 2000);
distinct 是去重关键字
需求:查询家电类 与 鞋服类下面的全部商品信息
-- 先查询出家电与鞋服类的 分类ID
SELECT cid FROM category WHERE cname IN ('家电','鞋服');
-- 根据cid 查询分类下的商品信息
SELECT * FROM products
WHERE category_id IN
(SELECT cid FROM category WHERE cname IN ('家电','鞋服'));
子查询的总结
- 子查询是单列(字段),就在where后面做条件
- 如果是多个字段(多列),就当作一张表使用,记得要起别名
数据库设计三范式
三范式就是设计数据库的规则,建立冗余较小、结构合理的数据库
范式是符合某一种设计要求的总结
第一范式 1NF
这是满足最低要求的范式
- 列具有原子性, 设计列要做到列不可拆分
- 数据库表里面字段都是单一属性的,不可再分, 如果数据表中每个
字段都是不可再分的最小数据单元,则满足第一范式

第二范式 2NF
满足第一范式的基础上,进一步满足更多的规范
- 目标是确保表中的每列都和主键相关。
- 一张表只能描述一件事
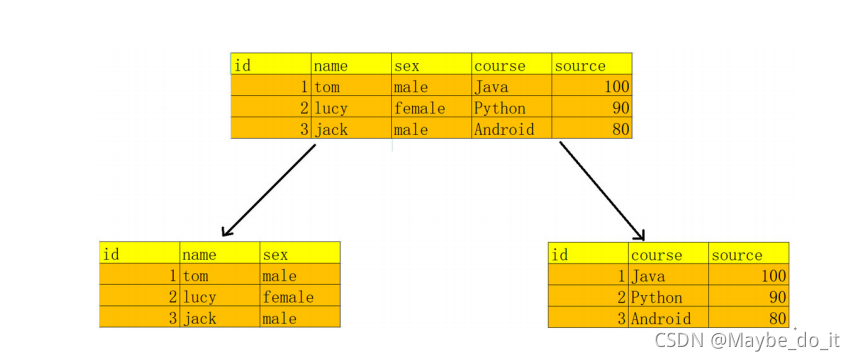
学员信息表中其实在描述两个事物 , 一个是学员的信息,一个是课程信息
如果放在一张表中,会导致数据的冗余,如果删除学员信息, 成绩的信息也被删除了
要确保一张表只做一件事情
第三范式 3NF
以此类推,满足第二范式的基础上,满足更多的规范
- 消除传递依赖
- 表中的信息,如果能够被推导出来,就不应该单独的设计一个字段来存放
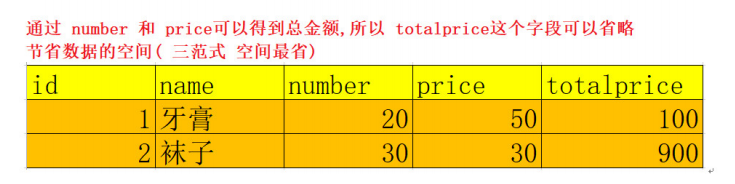
通过number 与 price字段就可以计算出总金额,不要在表中再做记录
3NF就是空间最省原则
数据库反三范式
反范式化指的是通过增加冗余或重复的数据来提高数据库的读性能
浪费存储空间,节省查询时间 (以空间换时间)
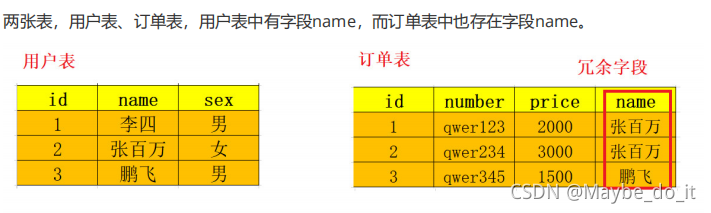
- 当需要查询“订单表”所有数据并且只需要“用户表”的name字段时, 没有冗余字段 就需要去join
- 连接用户表,假设表中数据量非常的大, 那么会这次连接查询就会非常大的消耗系统的性能.
- 这时候冗余的字段就可以派上用场了, 有冗余字段我们查一张表就可以了
- 合理的加入冗余字段这个润滑剂,减少join,让数据库执行性能更高更快