今天更新一篇基础,使用Python爬取百度搜索结果,最后将爬取结果保存到txt文本文件中。
一.准备工作
1.工具
1.Google Chrom浏览器
2.Xpath Helper
3.Pycharm 开发工具
4.Python3.x
二.思路
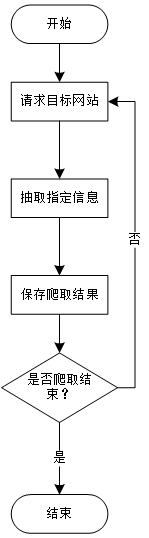
1.爬虫思路
2.数据抽取思路
- 确定目标
在搜索框输入关键字,蓝色框的文字以及对应链接是我们爬取的目标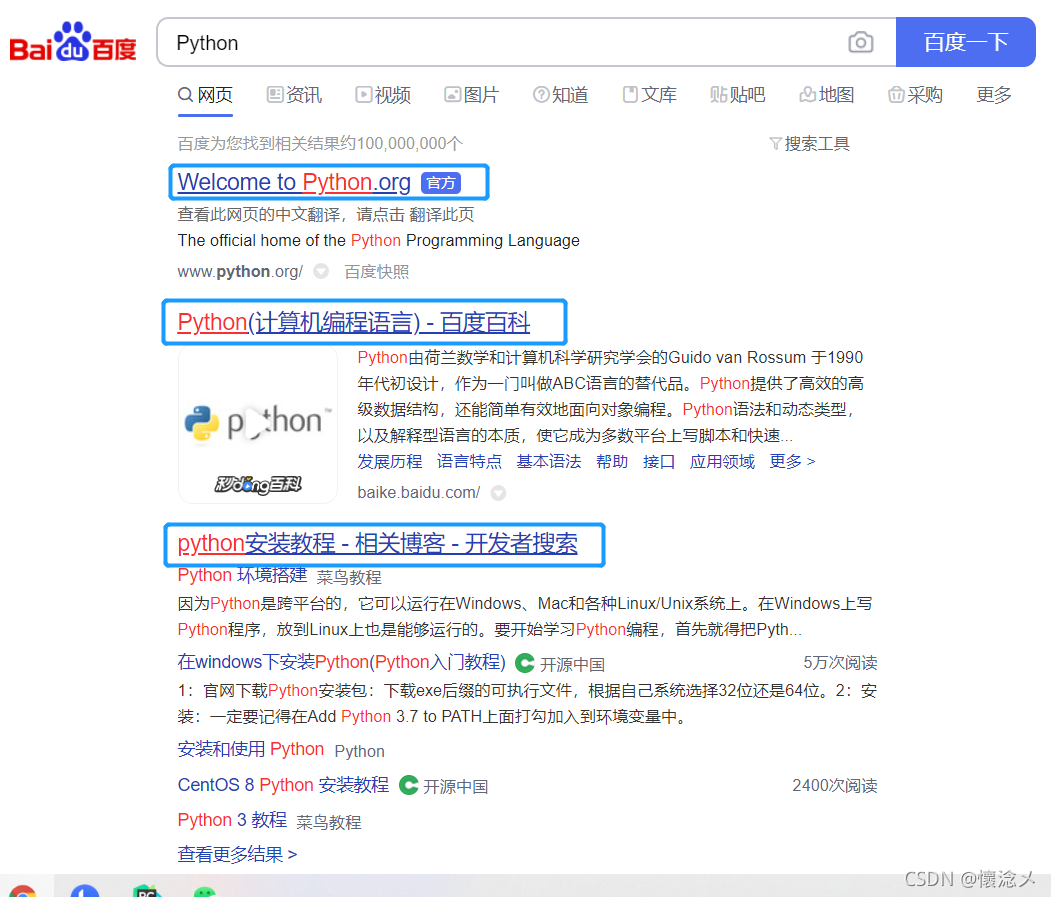
- 开发者工具定位元素属性
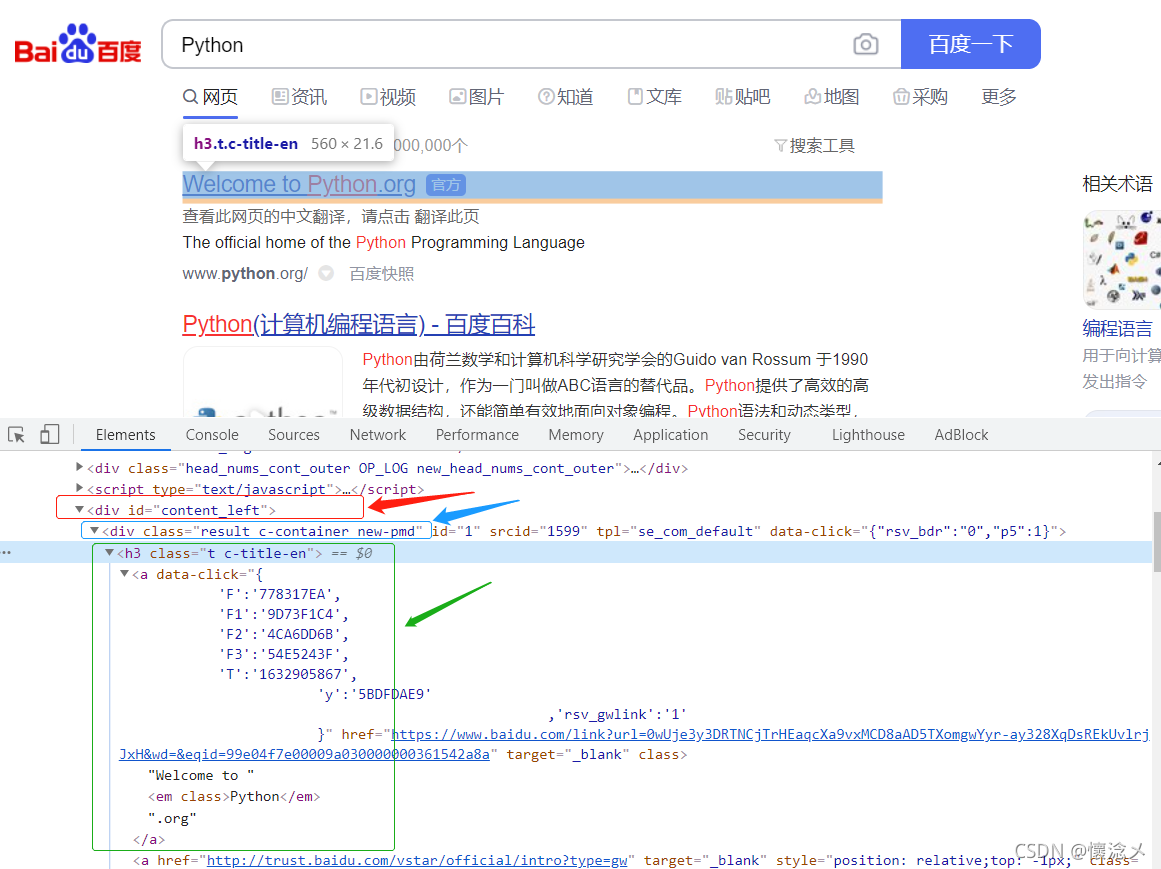
F12打开开发者工具,发现所有目标元素都在id="content_left"标签里面,单个搜索结果在class="result c-container new-pmd"中,搜索结果的标题和链接都在./h3/a中,分析清楚后,去写xpath就行了。
- 翻页页码规律1
由于我们是将所有搜索结果全部爬取,所以一定要翻页的
通过观察能发现,我们每点一次下一页> url中的pn参数会 +10比如第二页:
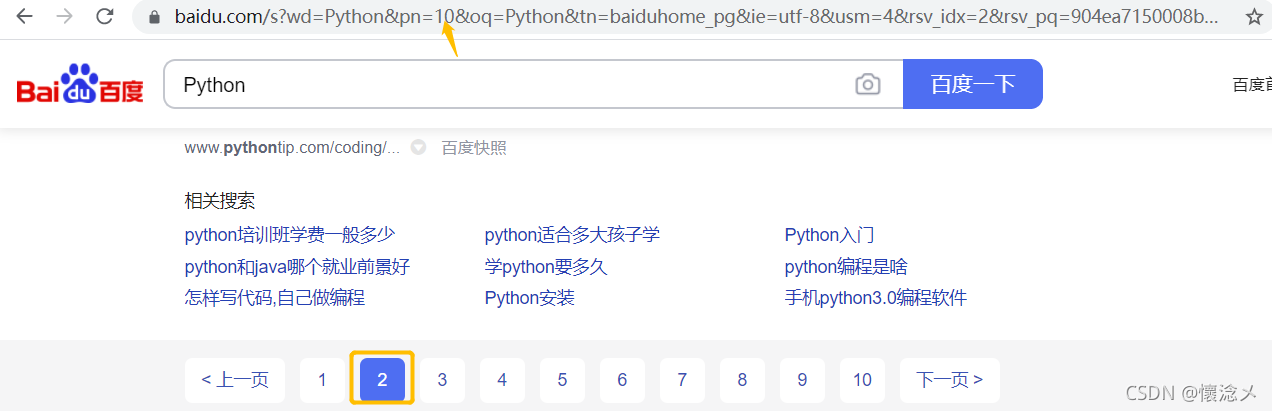
第二页pn=10 第三页 pn=20 第四页 pn=30,那么第N页,pn=(N-1)*10。 - 翻页规律2
分析了页码规律,还不算完,还要确定是否有下一页> ,我们可以手动翻页,或者手动修改"pn"参数,到最大页码,这里发现,当我们翻到76页(pn=75)时下一页> 按钮,消失了。

- 确定翻页标志
这样就好弄了,直接判断页面上有没有下一页>这个元素即可:
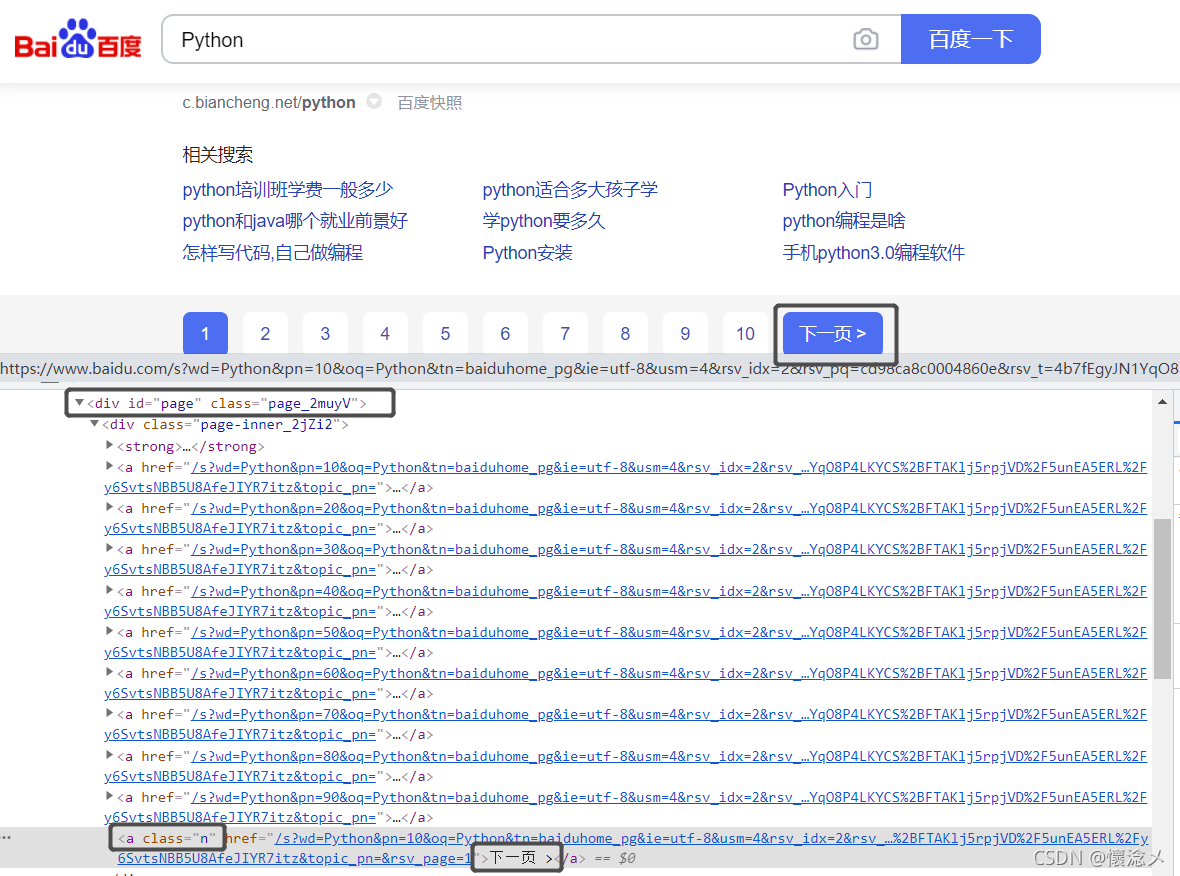
这里我们发现这个元素在id="page"的div下的div下的最后一个a标签的文本中,xpath可以这样写:
//div[@id=“page”]/div/a[last()]/text()
三.源代码
crawl_baidu_search_result.py
#-*-coding:utf-8-*-
import requests
from lxml import etree
import time
class BaiDu_Spider(object):
def __init__(self,keyword):
self.base_url='https://www.baidu.com/s?wd={}'
self.keyword=keyword
self.url=self.base_url.format(self.keyword)+'&pn={}&ie=utf-8'
def get_html(self,page):
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
try:
r=requests.get(self.url.format(page),headers=headers)
r.encoding='utf-8'
res=etree.HTML(r.text)
selector=res.xpath('//div[@id="content_left"]/div[@class="result c-container new-pmd"]')
data_list=[]
for data in selector:
item={
}
item['title']=''.join(data.xpath('./h3/a/text()'))
item['link']=''.join(data.xpath('./h3/a/@href'))
data_list.append(item)
flag=res.xpath('//div[@id="page"]/div/a[last()]/text()')
print(flag)
if flag:
return data_list,True
else:
return data_list,False
except:
pass
def save_data(self,item):
with open(crawl_result,'a',encoding='utf-8')as f:
data=item['title']+'\t'+item['link']
print(data)
f.write(data+'\n')
def main():
n=10
while True:
data_list,flag=spider.get_html(n)
for data in data_list:
spider.save_data(data)
time.sleep(1)
if flag is True:
n+=10
else:
print(f'程序已经退出,在{
int(n/10)+1}页......')
break
if __name__ == '__main__':
keyWord='Python'
crawl_result=f'./crawl_{
keyWord}.txt'
spider=BaiDu_Spider(keyWord)
main()
四.结果

五.总结
本次内容比较基础,是对静态网页进行数据提取,主要依赖xpath。百度存在访问频率限制的反爬,所以加入了一秒的延时。
xpath的定位方法可以参考
欢迎大家提出自己的看法,思路、代码方面有什么不足欢迎各位大佬指正、批评!

扫描二维码关注公众号,回复:
13208989 查看本文章
