注明:《Redis设计与实现》的个人学习总结,这本书对redis的讲解清晰易懂,如果深入学习可以看看这本书。
目录
第6章 整数集合
- 整数集合是集合键的底层实现之一,如果只有整数而且数量不多的时候就可以使用整数集合的结构。
redis> SADD numbers 1 3 5 7 9
(integer) 5
redis> OBJECT ENCODING numbers
"intset"
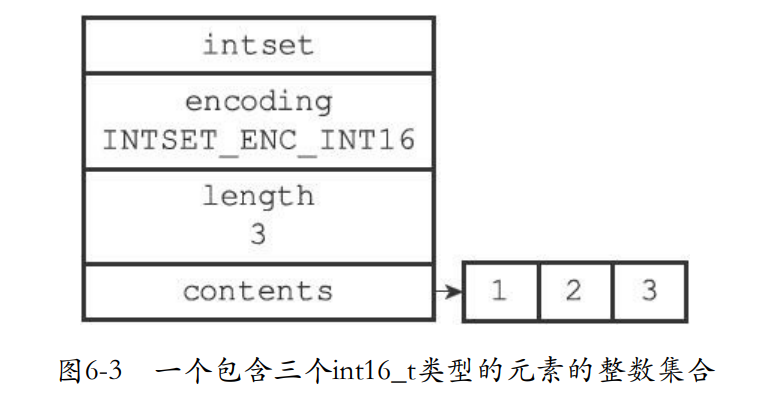
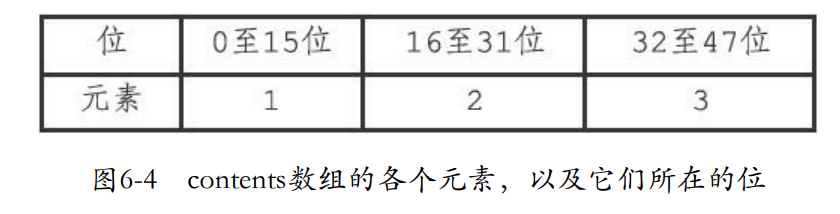
6.1 整数集合的实现
- 整数集合是redis保存整数值的抽象数据结构
typedef struct intset {
//
编码方式
uint32_t encoding;
//
集合包含的元素数量
uint32_t length;
//
保存元素的数组
int8_t contents[];
} intset;
- contents就是元素数组,但是并不是uint32_t的类型,它由encoing决定
- length:数组长度
- encoding决定contents的类型
- INTSET_ENC_INT16这个说明只有16个bit的int类型
- INTSET_ENC_INT32这个是32位
- INTSET_ENC_INT64这个是64位
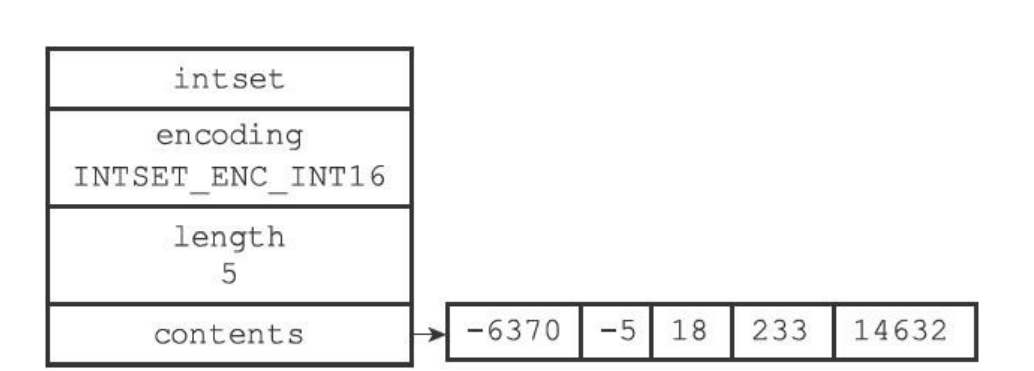
- 对于下面的这种情况有3个是16位的比如1,3,5,但是第一个数很明显就是64位,所以只能够把整个数组升级为64位的
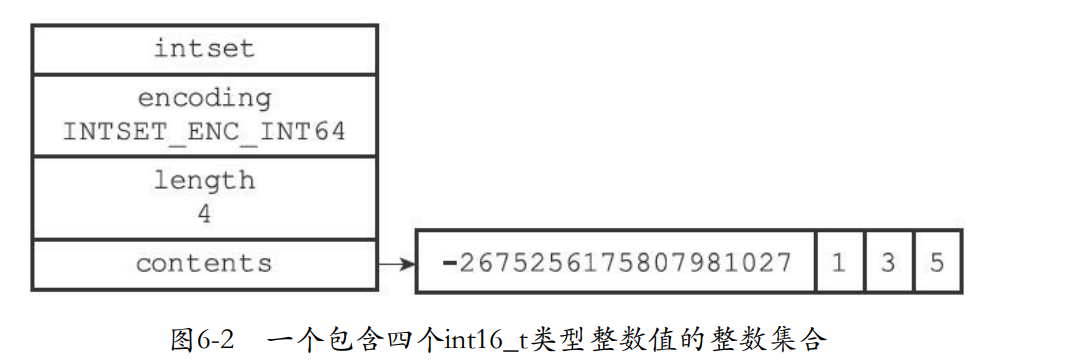
6.2 升级
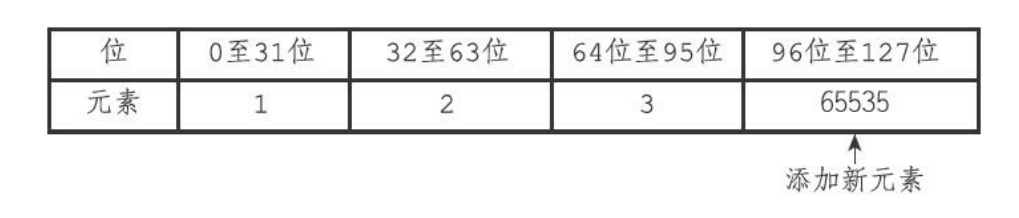
- 如果新加入的元素占用的bit非常多,那么就需要去拓展其他元素的bit。比如数组原本是16bit,现在加入一个32bit的那么其他所有元素都要拓展成32bit的。
集合添加升级元素步骤
- 根据新元素类型分配空间
- 底层把数组转换成和新元素类型相同的数组,把原来的元素放入正确的位置
- 加入新元素、
下面就是整个过程


6.3 升级的好处
6.3.1 提升灵活性
- 可以通过升级把各种类型的int放入集合,原本的c数组要么就是16要么就是32不能够一起放。
6.3.2 节约内存
- 能够在有需要的时候才拓展而不是一开始就直接使用64bit保存int
6.4 降级
- 整数集合不能够支持降级,保持升级之后的编码
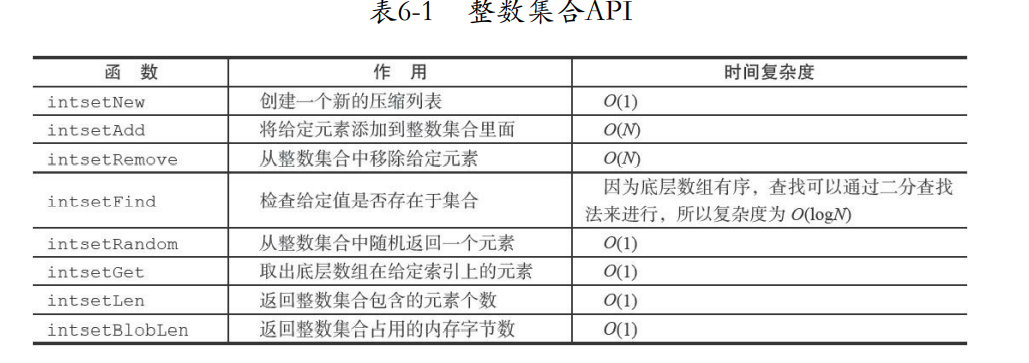
6.5 整数集合API
6.6 重点回顾
- 整数集合是集合键底层实现之一
- 实现有序而且无重复保存正数int
- 还有升级功能,能够保存多个类型的int,但是不支持降级
第7章 压缩列表
- 压缩列表是列表键和哈希键的实现方法之一
- 如果列表键包含少数列表项,那么就可以使用压缩列表
redis> RPUSH lst 1 3 5 10086 "hello" "world"
(integer)6
redis> OBJECT ENCODING lst
"ziplist"
- 列表键包含1,3,5,10086,hello world的列表项
- 如果哈希键也是只包含少数的键值对,小整数或者是长度短的字符串那么也可以使用ziplist。
redis> HMSET profile "name" "Jack" "age" 28 "job" "Programmer"
OK
redis> OBJECT ENCODING profile
"ziplist"
7.1 压缩列表的构成
- 压缩列表为了redis节约内存开发的。由一系列特殊编码的内存块组成顺序型数据结构
- 包含多个节点,可以保存小整数或者是小字符串


- zlbytes:表示压缩类表的有多少个字节长度
- zltail:如果有一个指向压缩类表起点的p,p+zltail(偏移量),能够得到表尾节点。
- zllen:表示表中包含多少个节点。
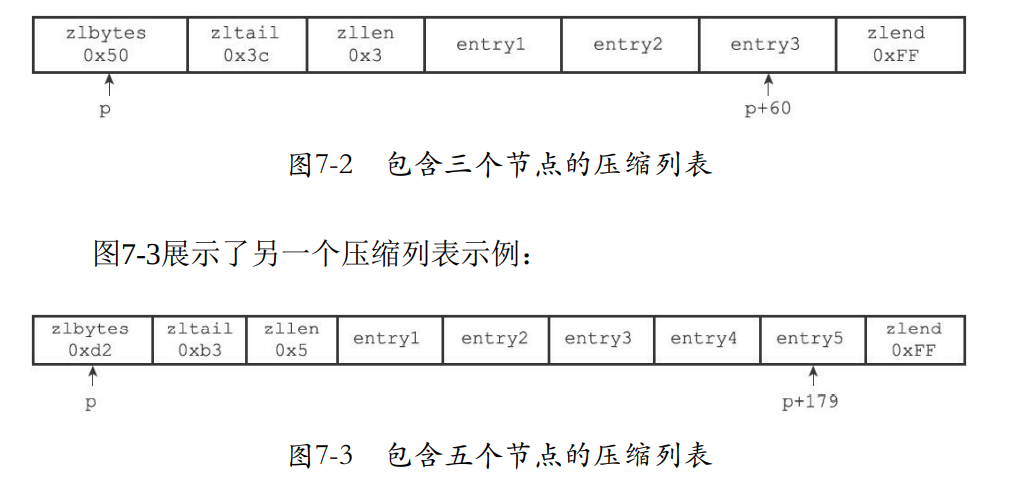
7.2 压缩列表节点的构成
- 压缩链表的数组大小
- 长度<=63(2^6 –1)个字节
- 长度<=于16383(2^14 –1)
- 长度<=4294967295(2^32 –1)
- 整数值的长度
- 4bit,0-12的无符号整数
- 1字节有符号整数
- 3字节符号整数
- int16_t
- int32_t
- int64_t
节点组成部分

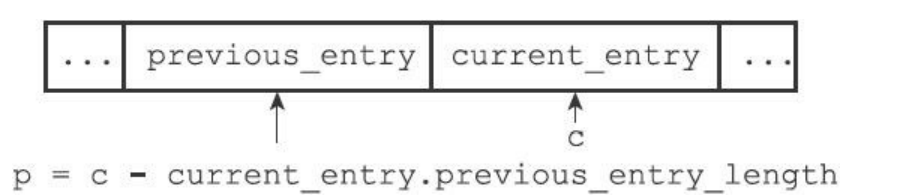
7.2.1 previous_entry_length
- 以字节为单位。记录压缩列表前一个节点的长度,这个属性长度可以是1或者是5字节。
- 如果前一个节点<256字节,那么previous_entry_length可以是1字节
- 否则就是5字节
- 对于下面的图来说,0xFE是表明这个长度是5字节长度,后面四个字节才是表示前一个节点占有的字节数量。

- 所以可以通过指针运算出前一个节点的位置,所以表尾指向表头就是这么实现的。
7.2.2 encoding
- 记录content的类型和长度
- 一字节或者是2字节或者是5字节,00,01,10这些是每个记录的占用字节,数组长度就是encoding减去前2个位后面的就是长度。比如00xxxxxx,去掉00,那么xxxxxx就是数组的长度设置。前面的00和01这些就是每个元素占用的字节数。
- 一字节长,值的开始是11就是整数编码,表明content保存的是整数


7.2.3 content
- encoding的信息:00是一个字节数组,1011就是长度是11。
- content内容是hello world。

7.3 连锁更新
- 所谓的连锁更新就是现在e1-en的previous_entry_length都是253,253只需要previous_length使用1个字节,但是现在加入一个新的节点大小大于等于254,这个时候对于e1来说previout_entry_length就要拓展到5个字节,这个时候e1占用空间>254,那么e2也要拓展,拓展之后e3也要。。。这种就是连锁更新。
- 删除也是会产生连锁更新,比如删除e1前面的small,原本e1存入的是previous_entry_length是一个字节,但是删除small之后,small前面可能就是比较大的e0,这个时候e1就要拓展到5个字节,如果后面的e2和e3是>250字节的话那么也是需要拓展的
- 时间复杂度是n^2
- 但是对于这种来连续是>250但是<253的情况很少见。对于少数的几个进行连锁更新是没有问题的。


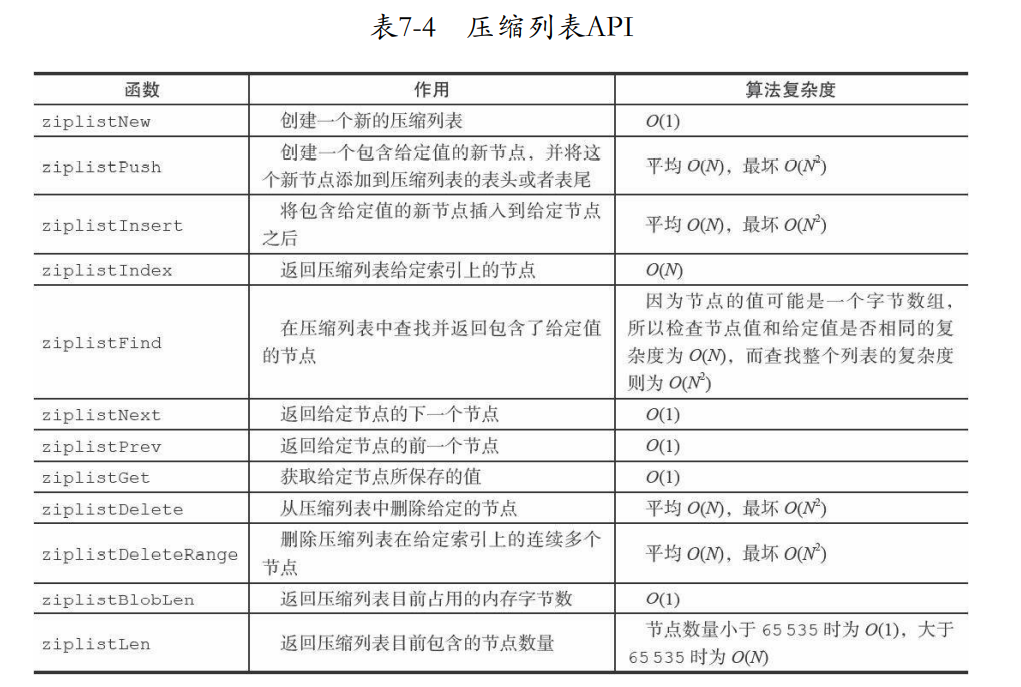
7.4 压缩列表API
7.5 重点回顾
- 压缩列表可以节约空间
- 但是有连锁更新问题
- 压缩列表可以有多个节点,通过记录前一个节点大小能够快速定位前一个节点初始位置。
第8章 对象
- redis数据库基于sds,双端链表、字典、压缩列表、整数集合来创建对象系统。
- 字符串对象,列表对象、哈希对象、集合对象、有序集合对象
- 对象可以通过多个数据结构实现。
- 通过引用计数技术来进行内存回收,如果对象没有被使用那么就会被回收,还能实现对象共享。多个数据库键共享一个对象
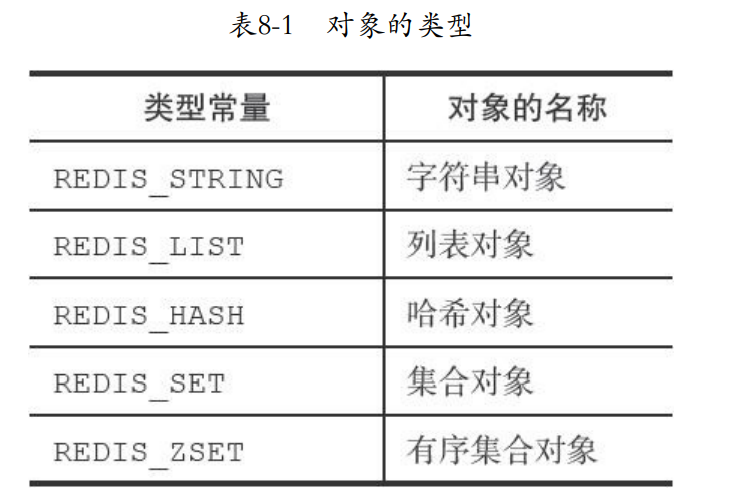
8.1 对象的类型与编码
- 每次创建键值对都会创建两个对象,一个是键的对象,一个是值的对象。
redis> SET msg "hello world"
OK
- 上面这个创建字符串 msg对象和hello world字符串对象
typedef struct redisObject {
//
类型
unsigned type:4;
//
编码
unsigned encoding:4;
//
指向底层实现数据结构的指针
void *ptr;
// ...
} robj;
- 每个对象的结构就是redisObject,一共有3个属性
8.1.1 类型
- type:指定对象的类型
- 当称呼一个键是字符串键,那么其实就是这个数据库键的值就是一个字符串对象
- 如果称呼是列表键,说明这个键的值就是一个列表对象
#
键为字符串对象,值为字符串对象
redis> SET msg "hello world"
OK
redis> TYPE msg
string
#
键为字符串对象,值为列表对象
redis> RPUSH numbers 1 3 5
(integer) 6
redis> TYPE numbers
list
#
键为字符串对象,值为哈希对象
redis> HMSET profile name Tom age 25 career Programmer
OK
redis> TYPE profile
hash
#
键为字符串对象,值为集合对象
redis> SADD fruits apple banana cherry
(integer) 3
redis> TYPE fruits
set
#
键为字符串对象,值为有序集合对象
redis> ZADD price 8.5 apple 5.0 banana 6.0 cherry
(integer) 3
redis> TYPE price
zset
- type命令就是看这个键到底是什么类型。但是只能看到值的类型。通常键都是一个字符串对象,但是值的类型就包含了5种。

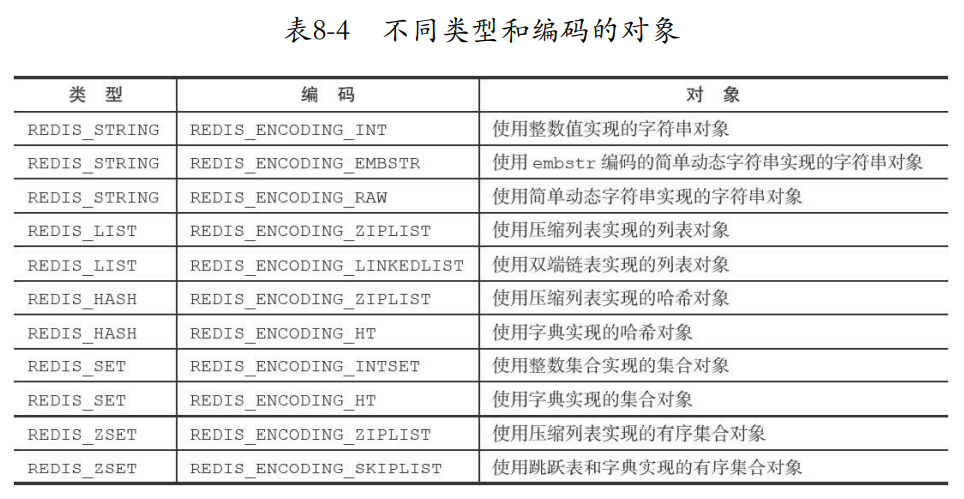
8.1.2 编码和底层实现
- encoding决定了ptr指向的数据结构类型

- 每种类型对象都有两种编码,实际上就是一个对象可能可以由不同数据结构构成。
- OBJECT ENCODING命令可以查询键的值的一个编码情况。
redis> SET msg "hello wrold"
OK
redis> OBJECT ENCODING msg
"embstr"
redis> SET story "long long long long long long ago ..."
OK
redis> OBJECT ENCODING story
"raw"
redis> SADD numbers 1 3 5
(integer) 3
redis> OBJECT ENCODING numbers
"intset"
redis> SADD numbers "seven"
(integer) 1
redis> OBJECT ENCODING numbers
"hashtable"
- 对于encoding来说可以对应不同场景使用不同的编码也就是使用不同的底层实现数据结构
- 比如元素比较少的时候可以使用压缩列表,这个比双端链表更节约内存。可以快速被加载进缓存,因为他是连续块。但是元素增多的时候还是得使用双端链表。
8.2 字符串对象
- 字符串对象的编码可以是int、raw或者embstr。
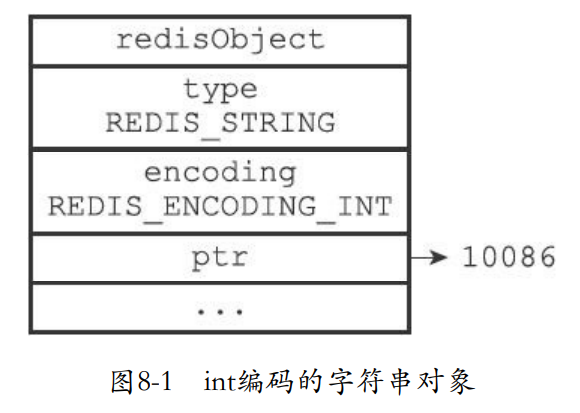
redis> SET number 10086
OK
redis> OBJECT ENCODING number
"int"
- 上面这种保存的是一个整数或者是long类型的那么就可以直接使用一个int来进行保存
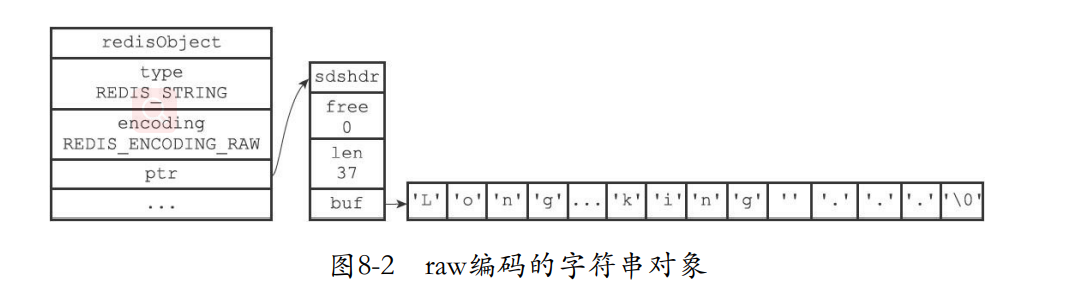
redis> SET story "Long, long ago there lived a king ..."
OK
redis> STRLEN story
(integer) 37
redis> OBJECT ENCODING story
"raw"
-
上面这种如果字符串值长度大于32个字节,那么就要使用sds来进行保存,这个编码就是raw
-
如果是小于32个字节那么就使用embstr,这种一样是由redisObj和sds结构,但是raw进行两次内存分配,但是对于embstr来说就只进行了一次内存分配。空间连续的两个结构存储到了一起。上面那种就是通过指针连接起来,所以分配了两部分的内存。
-
embstr的好处
- 内存只分配一次
- 由于数据连续存储能够更好利用缓存
-
对于long和double这些都是使用字符串进行的保存。计算的时候会进行类型转换再进行计算。

8.2.1 编码的转换
- 对于int编码来说如果整数被修改为字符串那么就会转化成raw,比如下面
redis> SET number 10086
OK
redis> OBJECT ENCODING number
"int"
redis> APPEND number " is a good number!"
(integer) 23
redis> GET number
"10086 is a good number!"
redis> OBJECT ENCODING number
"raw"
- 对于embstr来说没有任何拓展程序,所以要修改就要先变为raw。
8.2.2 字符串命令的实现

8.3 列表对象
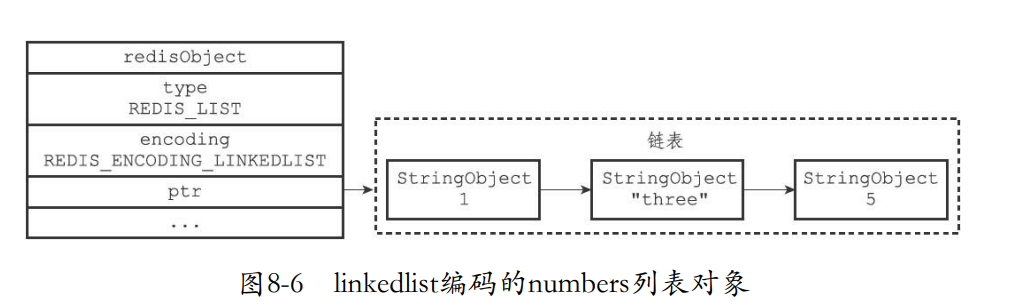
-
列表对象的编码可以是ziplist或者是linkedlist
-
rpush创建一个列表对象作为numbers键的值。加入三个元素,底层是ziplist
redis> RPUSH numbers 1 "three" 5
(integer) 3

- 下面是双端链表。
8.3.1 编码转换
满足条件使用ziplist
- 列表对象保存所有字符串元素长度都是小于64个字节的。
- 列表对象保存的元素数量小于512个。不然就只能使用linkedlist了
如果不符合条件那么就要转换成linkedlist,这个是保存长度太大。还有一种可能就是保存元素超过512个
#
所有元素的长度都小于64
字节
redis> RPUSH blah "hello" "world" "again"
(integer)3
redis> OBJECT ENCODING blah
"ziplist"
#
将一个65
字节长的元素推入列表对象中
redis> RPUSH blah "wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww"
(integer) 4
#
编码已改变
redis> OBJECT ENCODING blah
"linkedlist"
8.3.2 列表命令的实现

8.4 哈希对象
- 哈希对象的编码可以是ziplist或者是hashtable
- 这种保存是先把键送到压缩列表的表尾,再把值送到表尾。
- 键值对挨在一起
- 最早的加入在表头,最晚加入在表尾。
- 下面举个例子,展示整个压缩列表的结构。
redis> HSET profile name "Tom"
(integer) 1
redis> HSET profile age 25
(integer) 1
redis> HSET profile career "Programmer"
(integer) 1
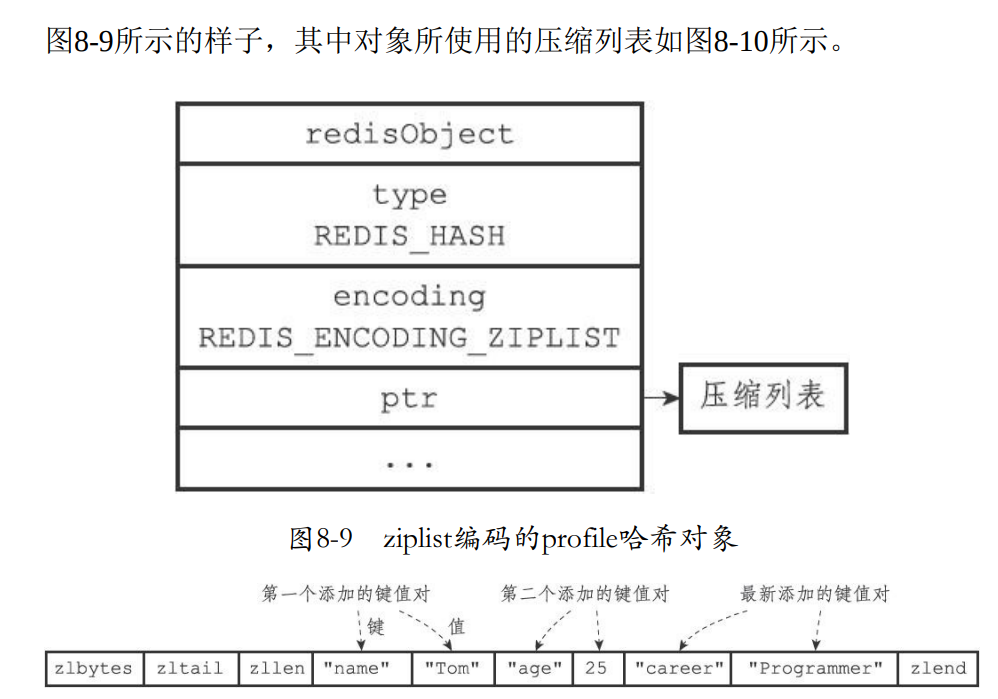
- 如果是hashtable编码那就是使用字典进行的实现。
- 字典每个键都是字符串对象,对象保存了键
- 值也是一个字符串对象
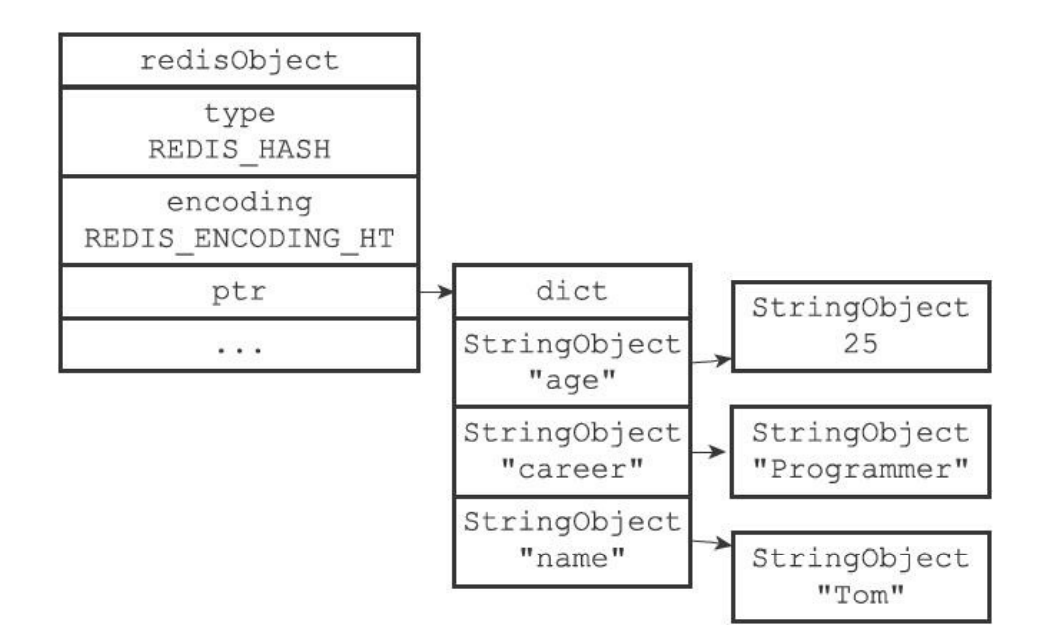
8.4.1 编码转换
ziplist的条件
- 哈希对象保存的键和值都是<64字节的。
- 键值对数量必须少于512个
如果不是那么全部都是使用hashtable
8.4.2 哈希命令的实现

8.5 集合对象
-
编码可以是intset或者是hashtable
-
intset使用整数集合实现集合对象

redis> SADD numbers 1 3 5
(integer) 3
- hashtable就是使用字典来作为集合的底层实现。
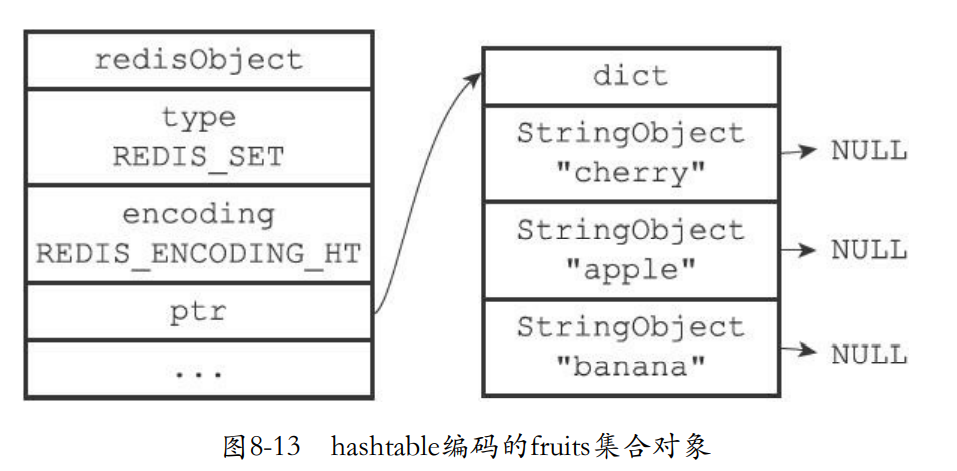
SAD Dfruits "apple" "banana" "cherry"
(integer)3
8.5.1 编码的转换
如果是inset条件
- 元素是整数
- 元素数量不超过512个
其它都是使用hashtable
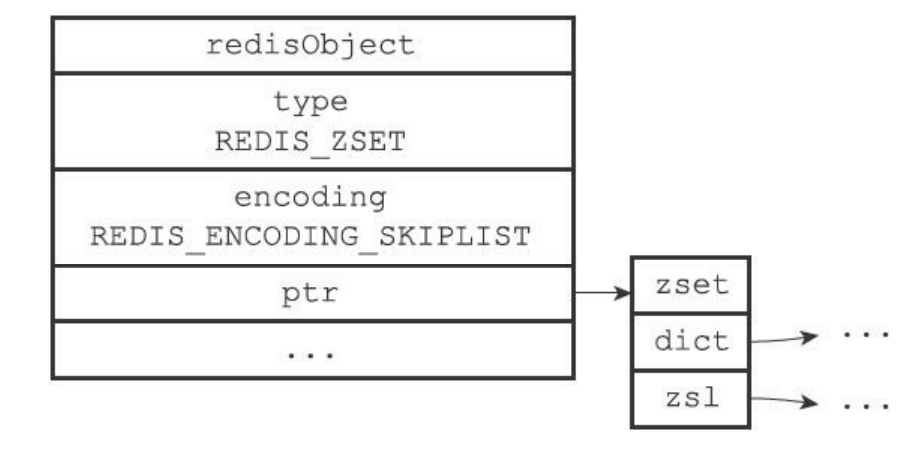
8.6 有序集合对象
-
编码是ziplist或者是skiplist
-
如果是ziplist,第一个元素是保存member,第二个元素保存分值。
redis> ZADD price 8.5 apple 5.0 banana 6.0 cherry
(integer) 3
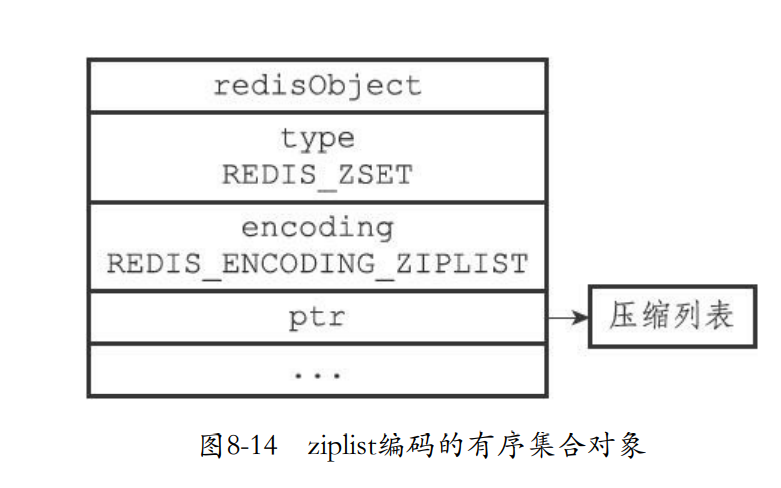
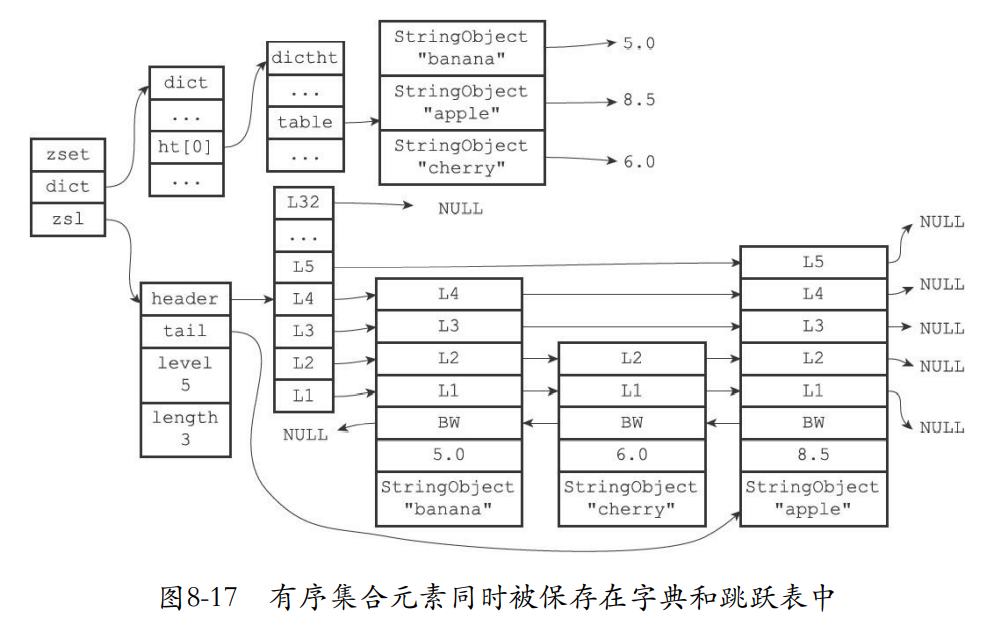
- 对于skiplist来说,有序集合对象包含了一个zset结构,一个zset又包含了一个跳表和一个字典
typedef struct zset {
zskiplist *zsl;
dict *dict;
} zset;

-
zset结构的zsl跳跃表从小到大保存所有集合元素。这里的跳跃表的obj保存了member。score保存了元素的分值
-
这个时候就可以使用zrank或者是zrange了,底层就是跳跃表的api。
-
zset还通过字典来把成员和分值进行一个映射。字典的键就是元素成员,值就是成员的分值,可以快速定位成员的分值。zscore就是这么实现的
-
有序集合的成员都是字符串对象,分值都是double类型
-
虽然使用了两个结构,但是他们可以通过指针来共享同一个元素成员和分值。
为什么有序集合需要同时使用跳跃表和字典来实现?
- 如果只是使用字典,查找分值速度非常快,但是是无序的
- 如果只是使用跳跃表那么就是有序,但是查找分值速度就慢很多了。因为需要使用到二分法去查找。
- 所以两种一起使用可以避免对象造成的缺点。
8.6.1 编码的转换
满足ziplist的条件
- 保存元素小于128个
- 所有元素的长度都是小于64字节的。
其它情况都是使用skiplist的。
8.7 类型检查与命令多态
- SET、GET、APPEND、STRLEN等命令只能对应string类型操作
- HDEL、HSET、HGET、HLEN只能对哈希键进行操作
8.7.1 类型检查的实现
- 也就是对于不同的操作命令都是要对对象的类型进行检验。
- 比如对于llen操作就是要验证数据是一个列表的结构
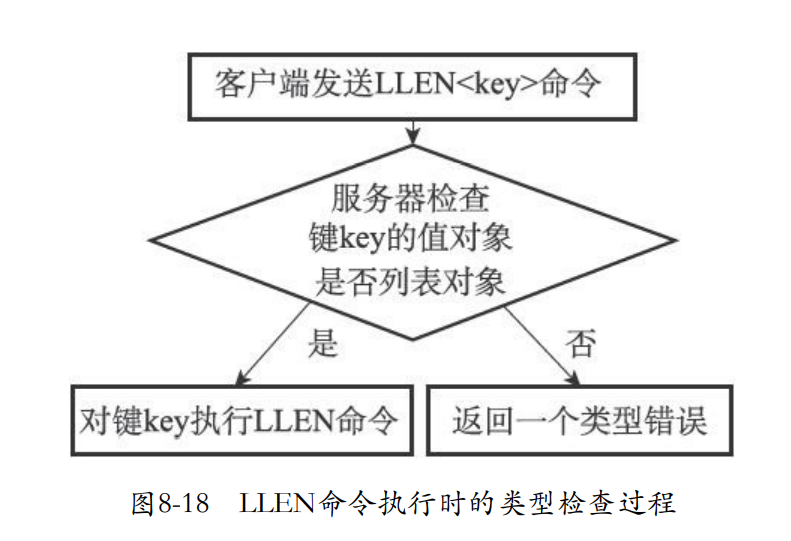
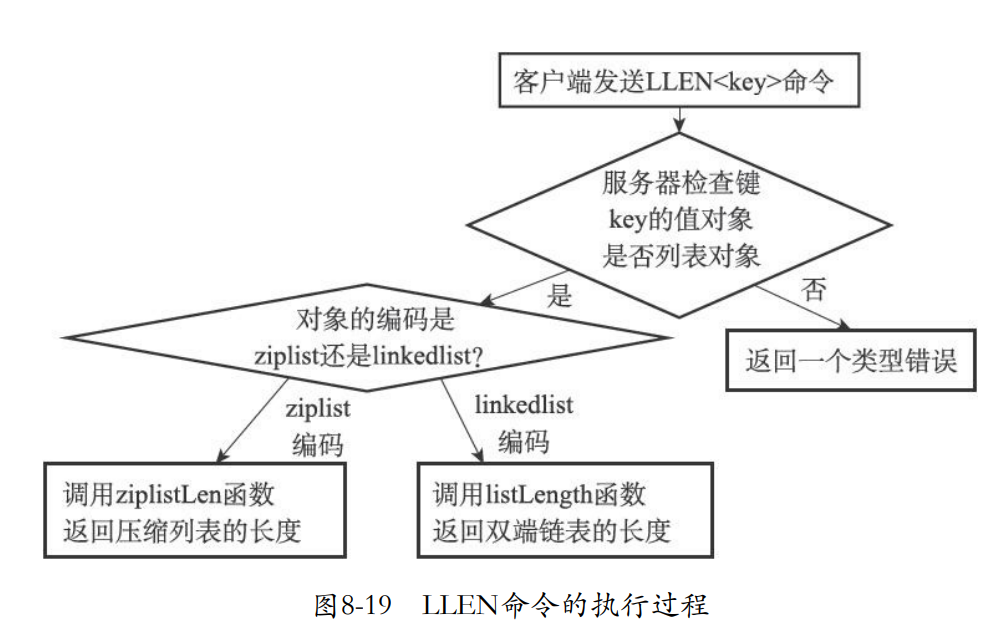
8.7.2 多态命令的实现
- 而且对于LLEN命令来说,操作的列表可能有不同的api实现,因为列表有两种底层结构ziplist和linkedlist
- ziplist调用的是ziplistLen函数
- linkedlist调用的是listLength函数。
- 也就是这个LLEN对于列表来说就是多态的,一个命令但是有两种不同api的实现。
- DEL、EXPIRE、TYPE这些也是多态命令,只不过是针对于不同type的对象的多态,llen是不同底层实现的多态。
8.8 内存回收
- 内存回收就是通过引用计数技术,这个计数存在于recount。
- 创建对象的时候初始化为1
- 每次有新的程序引用的时候就会加1
- 当引用变为0的时候就会被回收。
typedef struct redisObject {
// ...
//
引用计数
int refcount;
// ...
} robj;

- 对象创建到释放的过程
//
创建一个字符串对象s
,对象的引用计数为1
robj *s = createStringObject(...)
//
对象s
执行各种操作...
//
将对象s
的引用计数减一,使得对象的引用计数变为0
//
导致对象s
被释放
decrRefCount(s)
8.9 对象共享
- 如果A引用整数100,这个时候B也要创建整数100。那么他们都会引用同一个整数。
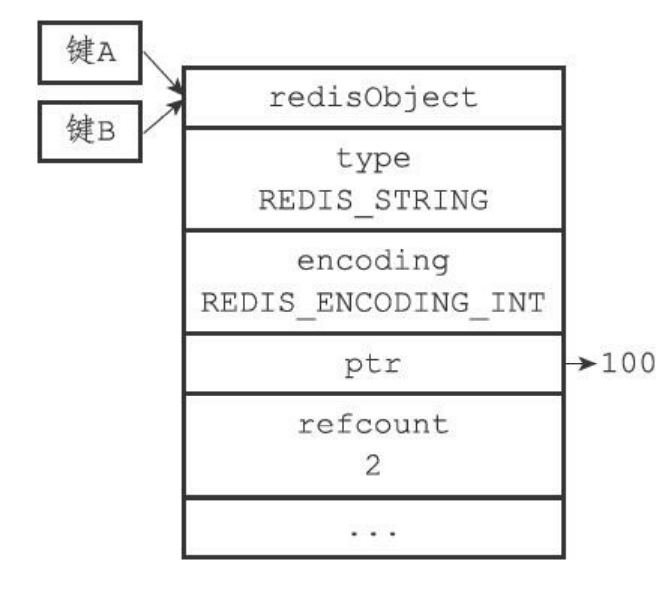
为什么Redis不共享包含字符串的对象?
- 字符串越长,也就是共享对象越复杂的时候就需要判断每个对象创建的那个到底和共享池里面的字符串是不是相同。虽然可以节约内存,但是如果大量的插入就会导致插入速度非常慢,大部分拿去判断了。
8.10 对象的空转时长
- 对象空转时长并没有存储在redisObj中,他主要是记录了上一次访问的时间戳lru。
typedef struct redisObject {
// ...
unsigned lru:22;
// ...
} robj;
- 可以使用object idletime xxx来得到当前的时间-对象上次访问的lru获取现在的空转时长。
- 空转时长的作用就是在回收键的时候,如果时长越长说明键使用频率低,就优先回收这些键。
8.11 重点回顾
- redis每个键值对的键和值都分别是一个对象。
- redis有五种类型列表,集合,有序集合,字符串,哈希,而且不同的类型有多个底层结构,结构可以通过编码指定,而且使用哪种结构需要通过具体的情景来决定
- 执行命令之前都会判断键的类型是不是符合,如果不符合不会执行的
- 内存回收机制依靠的就是引用计数法
- redis可以共享值0-9999的字符串对象
- 对象可以记录最后一次访问自己的时间,并且可以通过当前的时间减去上次访问时间得到空转时间,用于在淘汰缓存的时候使用。
第9章 数据库
9.1 服务器中的数据库
- 每个数据库就是一个redisDb的结构吗,而且每个服务器有多个这样的数据库。
- 默认的数据库数量是16
struct redisServer {
// ...
//
一个数组,保存着服务器中的所有数据库
redisDb *db;
// ...
};
struct redisServer {
// ...
//
服务器的数据库数量
int dbnum;
// ...
};
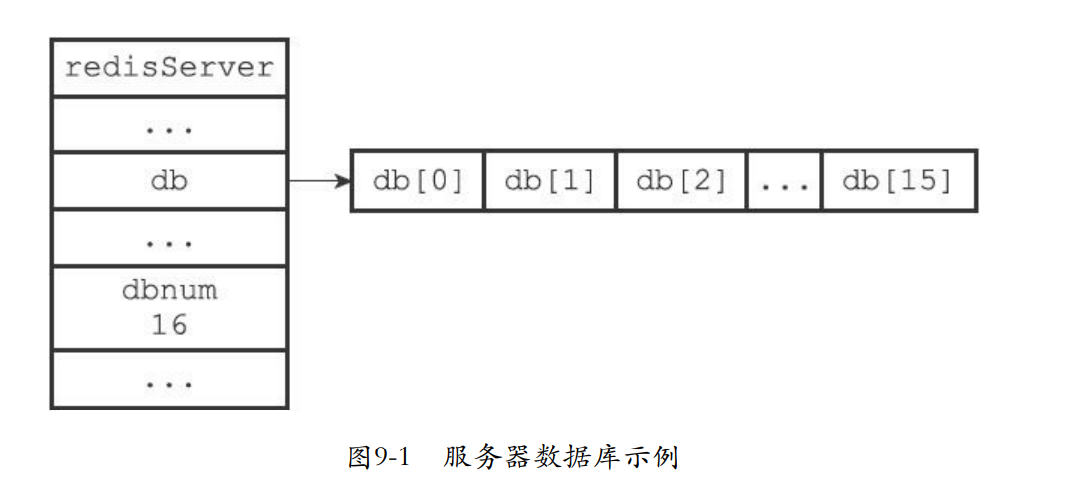
9.2 切换数据库
- 可以通过select x来切换数据库
redis> SET msg "hello world"
OK
redis> GET msg
"hello world"
redis> SELECT 2
OK
redis[2]> GET msg
(nil)
redis[2]> SET msg"another world"
OK
redis[2]> GET msg
"another world"
- 下面的结构就是记录当前client使用的数据库,server和client都是同时引用同一个数据库的数组。
typedef struct redisClient {
// ...
//
记录客户端当前正在使用的数据库
redisDb *db;
// ...
} redisClient;
9.3 数据库键空间
- 每个数据库的组成都是一个字典,而且数据库中有非常多的键值对。这个字典就是键空间。
typedef struct redisDb {
// ...
//
数据库键空间,保存着数据库中的所有键值对
dict *dict;
// ...
} redisDb;
- 键空间的键就是一个字符串对象
- 键空间的值可能是5种不同类型的对象
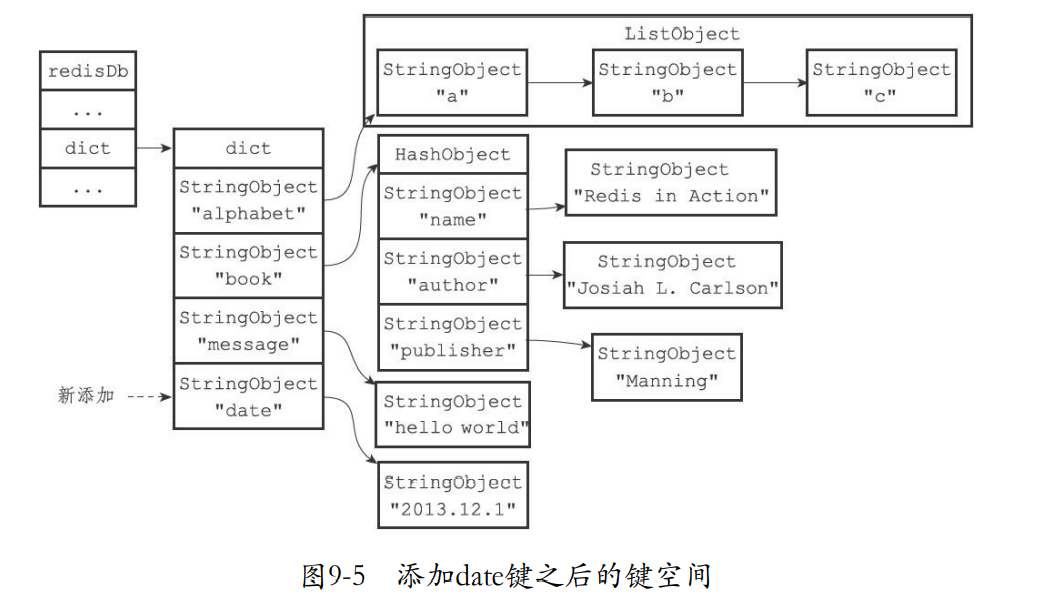
- 下面就是一个关联的例子。可以发现这里的db有一个键空间,键空间的键通过哈希结构指向值的对象。
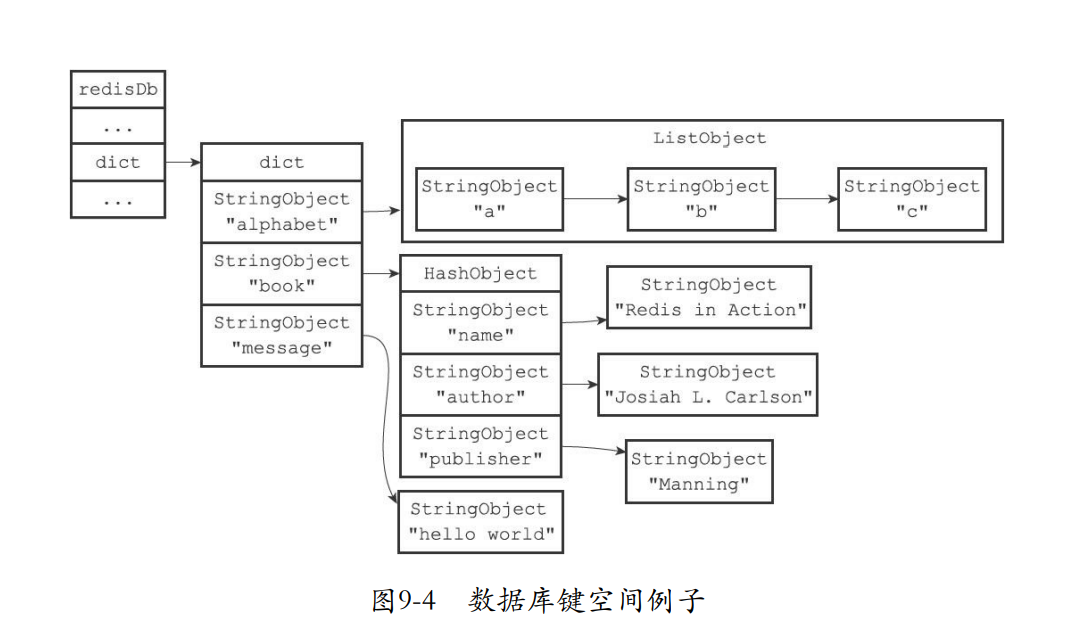
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WG4LzRvR-1637163359251)(C:/Users/11914/AppData/Roaming/Typora/typora-user-images/image-20211117130546911.png)]
9.3.1 添加新键
- 相当于就是添加一个新的键对象和值对象。
redis> SET date "2013.12.1"
OK
9.3.2 删除键
- 可以通过del来把键值对给删除。
redis> DEL book
(integer) 1

9.3.3 更新键
- 同样也可以通过set等命令来重新设置键的值。
9.3.4 对键取值
- 也能够通过get,lrange等命令取出值遍历。
9.3.6 读写键空间时的维护操作
- 每次读取都会更新服务器中的键缓存命中次数。
- 每次读取都会更新的键的LRU,也就是上面说的最后一次访问时间
- 如果读取到键过期那么就要删除
- watch监视键,如果修改那么就会标记这个键为脏。
- 还有就是数据库通知,如果键发生什么改变都能够按照配置发送数据库通知。
9.4 设置键的生存时间或过期时间
- 可以expire或者是pexipre来设置生存时间
redis> SET key value
OK
redis> EXPIRE key 5
(integer) 1
redis> GET key // 5
秒之内
"value"
redis> GET key // 5
秒之后
(nil)
- 通过EXPIREAT 命令或PEXPIREAT命令设置过期时间。过期时间是一个unix时间戳。到期就会自动删除。
9.4.1 设置过期时间
-
EXPIRE设置的是生存时间ttl秒
-
PEXPIRE设置的是生存时间是ttl毫秒
-
EXPIREAT:设置过期时间的timestamp的指定秒数时间戳
-
PEXPIREAT:也是设置过期时间的毫秒时间戳
-
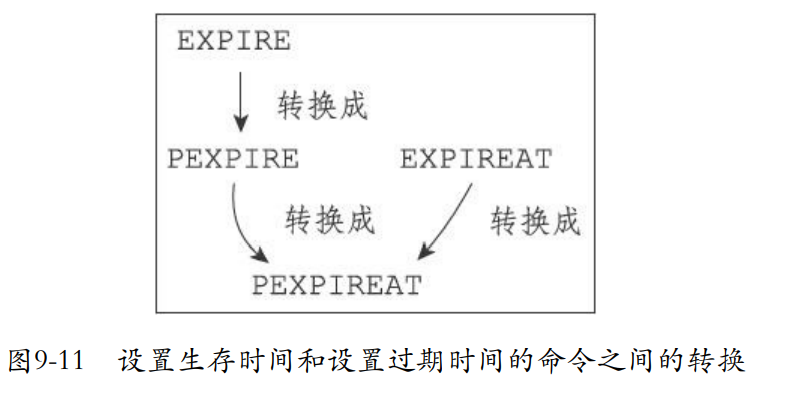
EXPIRE、 PEXPIRE、EXPIREAT都是通过PEXPIREAT来实现的。
首先是expire转换成expire
def EXPIRE(key,ttl_in_sec):
#
将TTL
从秒转换成毫秒
ttl_in_ms = sec_to_ms(ttl_in_sec)
PEXPIRE(key, ttl_in_ms)
- 然后就是pexpire转化成pexpireat。获取毫秒格式的过期时间。所以都是在计算出最后的过期时间。
def PEXPIRE(key,ttl_in_ms):
#
获取以毫秒计算的当前UNIX
时间戳
now_ms = get_current_unix_timestamp_in_ms()
#
当前时间加上TTL
,得出毫秒格式的键过期时间
PEXPIREAT(key,now_ms+ttl_in_ms)
- 也可以通过expireat转换成pexpireat。
def EXPIREAT(key,expire_time_in_sec):
#
将过期时间从秒转换为毫秒
expire_time_in_ms = sec_to_ms(expire_time_in_sec)
PEXPIREAT(key, expire_time_in_ms)
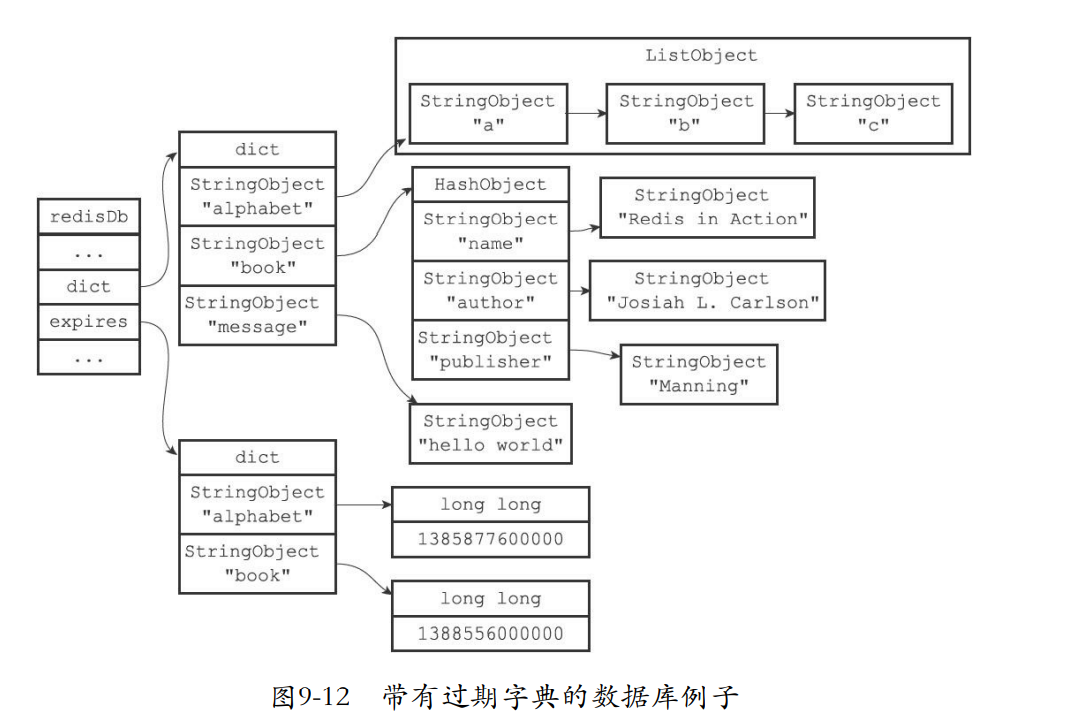
9.4.2 保存过期时间
- redisDb的expires字典保存了所有键的过期时间。这个就是过期字典。
- 一旦我们要设置过期时间,那么就会把对应的数据库键和过期时间进行关联存储。
typedef struct redisDb {
// ...
//
过期字典,保存着键的过期时间
dict *expires;
// ...
} redisDb;
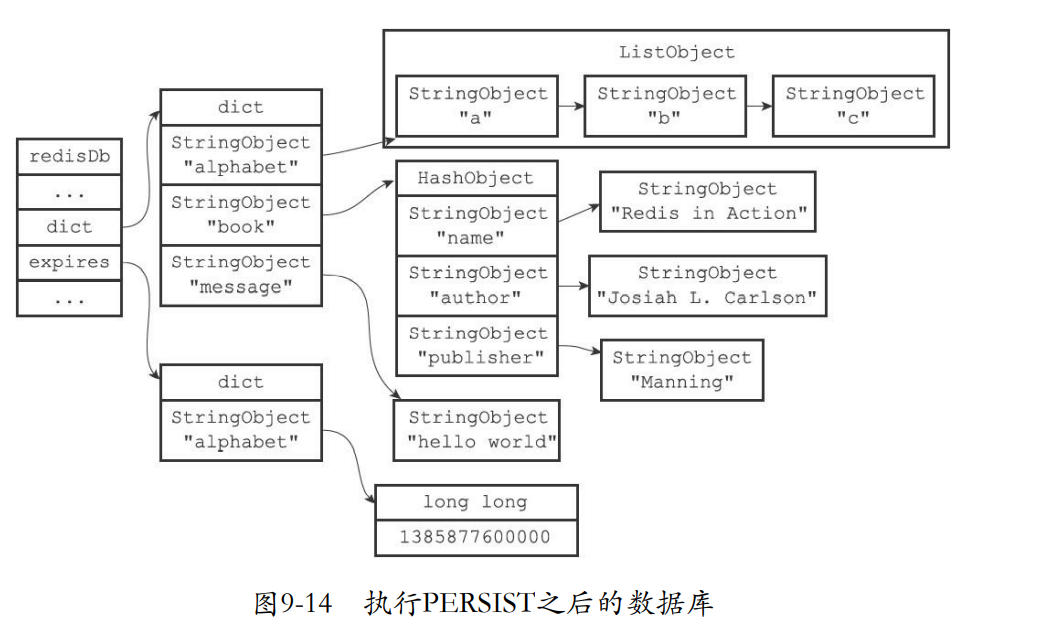
9.4.3 移除过期时间
- PERSIST可以移除一个键的过期时间
redis> PEXPIREAT message 1391234400000
(integer) 1
redis> TTL message
(integer) 13893281
redis> PERSIST message
(integer) 1
redis> TTL message
(integer) -1
- 比如下面移除一个book的过期时间
redis> PERSIST book
(integer) 1
- 移除的伪代码实现
def PERSIST(key):
#
如果键不存在,或者键没有设置过期时间,那么直接返回
if key not in redisDb.expires:
return0
#
移除过期字典中给定键的键值对关联
redisDb.expires.remove(key)
#
键的过期时间移除成功
return 1
9.4.4 计算并返回剩余生存时间
- TTL和PTTL都是通过过期时间减去当前时间得到的剩余生存时间
- TTL就是调用一次PTTL然后转换单位而已。
def PTTL(key):
#
键不存在于数据库
if key not in redisDb.dict:
return-2
#
尝试取得键的过期时间
#
如果键没有设置过期时间,那么 expire_time_in_ms
将为 None
expire_time_in_ms = redisDb.expires.get(key)
#
键没有设置过期时间
if expire_time_in_ms is None:
return -1
#
获得当前时间
now_ms = get_current_unix_timestamp_in_ms()
#
过期时间减去当前时间,得出的差就是键的剩余生存时间
return(expire_time_in_ms - now_ms)
def TTL(key):
#
获取以毫秒为单位的剩余生存时间
ttl_in_ms = PTTL(key)
if ttl_in_ms < 0:
#
处理返回值为-2
和-1
的情况
return ttl_in_ms
else:
#
将毫秒转换为秒
return ms_to_sec(ttl_in_ms)
9.4.5 过期键的判定
- 键是否存在过期字典
- unix时间戳是不是大于当前的过期时间。
def is_expired(key):
#
取得键的过期时间
expire_time_in_ms = redisDb.expires.get(key)
#
键没有设置过期时间
if expire_time_in_ms is None:
return False
#
取得当前时间的UNIX
时间戳
now_ms = get_current_unix_timestamp_in_ms()
#
检查当前时间是否大于键的过期时间
if now_ms > expire_time_in_ms:
#
是,键已经过期
def is_expired(key):
#
取得键的过期时间
expire_time_in_ms = redisDb.expires.get(key)
#
键没有设置过期时间
if expire_time_in_ms is None:
return False
#
取得当前时间的UNIX
时间戳
now_ms = get_current_unix_timestamp_in_ms()
#
检查当前时间是否大于键的过期时间
if now_ms > expire_time_in_ms:
#
是,键已经过期
9.5 过期键删除策略
- 定时删除:设定定时器,过期立刻删除
- 惰性删除:等到取这个键的时候删除
- 定期删除:每过一段时间删除一次。
9.5.1 定时删除
- 对内存友好,但是对CPU不友好,每次都要做一个定时器,然后过期之后立刻删除,而且定时器需要用到redis的时间事件,还要通过时间复杂度n的查找工作,如果是cpu紧张的时候这种并不是特别友好
9.5.2 惰性删除
- 取出键的时候才会检查并且删除,但是对内存不友好,原因就是那些不被访问的过期键就会堆在一起占用大量内存,但是对CPU非常友好。比如说日志这种,可能就会有大量垃圾数据堆积
9.5.3 定期删除
- 每隔一段时间进行删除,这种可以调控适应cpu当前工作量,和基于内存产生过期垃圾的速度来进行设置
- 不能删太快,不然和定时删除一样的毛病
- 不能删太慢,不然会堆积很多垃圾数据。
9.6 Redis的过期键删除策略
- 使用的惰性删除+定期删除。
- 合理使用cpu时间+避免浪费空间
9.6.1 惰性删除策略的实现
- 惰性删除通过db.c/expireIfNeeded函数实现。在调用redis命令同时还会调用expireNeeded对键进行检查。
- 过期删除
- 不过期不处理
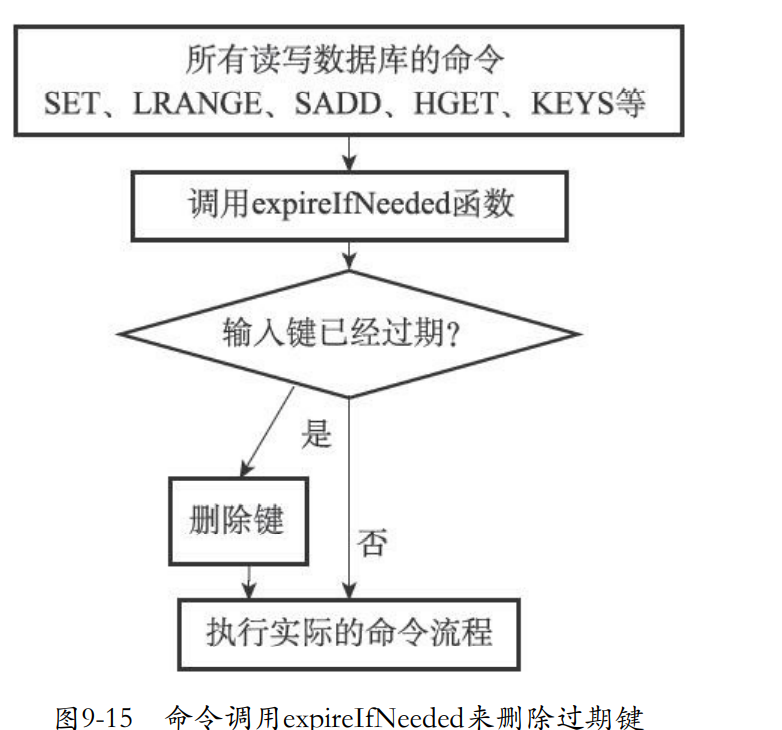
9.6.2 定期删除策略的实现
- 定期删除的策略通过redis.c/activeExpireCycle函数实现。
- 周期性操作通过redis.c/serverCron函数进行处理。分多次遍历所有数据库的过期字典。
#
默认每次检查的数据库数量
DEFAULT_DB_NUMBERS = 16
#
默认每个数据库检查的键数量
DEFAULT_KEY_NUMBERS = 20
#
全局变量,记录检查进度
current_db = 0
def activeExpireCycle():
#
初始化要检查的数据库数量
#
如果服务器的数据库数量比 DEFAULT_DB_NUMBERS
要小
#
那么以服务器的数据库数量为准
if server.dbnum < DEFAULT_DB_NUMBERS:
db_numbers = server.dbnum
else:
db_numbers = DEFAULT_DB_NUMBERS
#
遍历各个数据库
for i in range(db_numbers):
#
如果current_db
的值等于服务器的数据库数量
这表示检查程序已经遍历了服务器的所有数据库一次
#
将current_db
重置为0
,开始新的一轮遍历
if current_db == server.dbnum:
current_db = 0
#
获取当前要处理的数据库
redisDb = server.db[current_db]
#
将数据库索引增1
,指向下一个要处理的数据库
current_db += 1
#
检查数据库键
for j in range(DEFAULT_KEY_NUMBERS):
#
如果数据库中没有一个键带有过期时间,那么跳过这个数据库
if redisDb.expires.size() == 0: break
#
随机获取一个带有过期时间的键
key_with_ttl = redisDb.expires.get_random_key()
#
检查键是否过期,如果过期就删除它
if is_expired(key_with_ttl):
delete_key(key_with_ttl)
#
已达到时间上限,停止处理
if reach_time_limit(): return
activeExpireCycle函数的工作模式
- 全局变量current_db记录了activeExpireCycle函数当前的遍历数据库的进度。它会接上上一次遍历的进度继续,如果已经遍历完一次那么就重新设置为0,重新遍历。
9.7 AOF、RDB和复制功能对过期键的处理
9.7.1 生成RDB文件
- save和bgsave创建新的RDB,过期的键是不会存入RDB的。
9.7.2 载入RDB文件
- 对于主服务器来说过期的键会在载入的时候被忽略
- 如果是从服务器,无论是否过期都会载入。
9.7.3 AOF文件写入
- 过期的键不会对AOF产生影响
- 如果删除的过期键,那么就会在AOF中加入一条删除语句。
- 因为AOF记录的是操作语句,RDB记录的是键值对。
9.7.4 AOF重写
- 重写的AOF会忽略过期的键。
9.7.5 复制
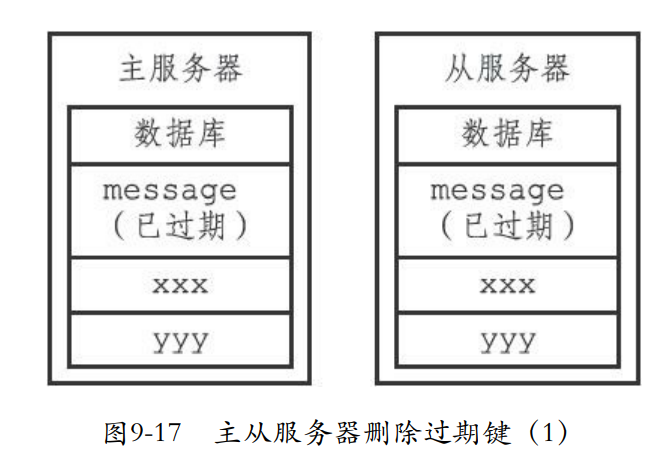
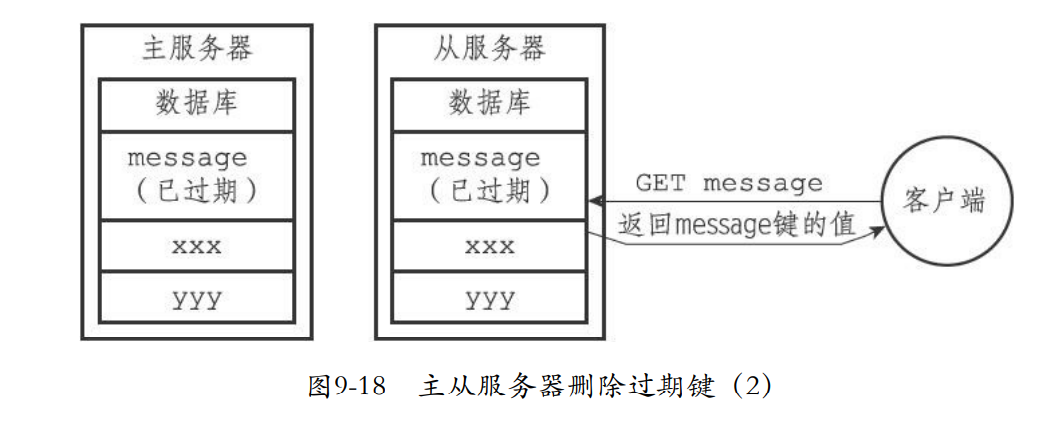
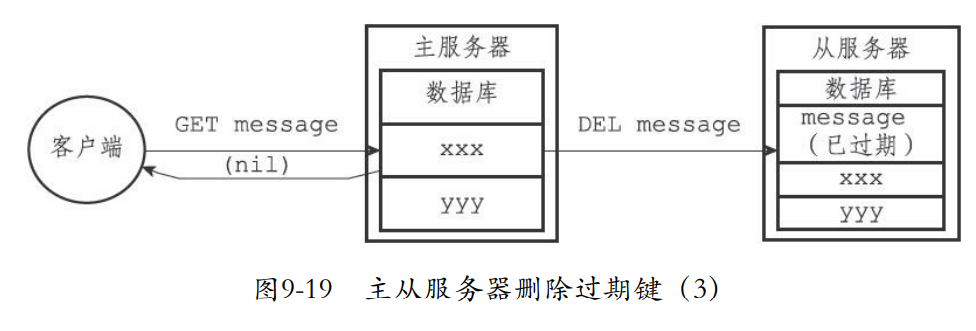
- 如果主服务器删除了过期键就要通知所有从服务器删除
- 从服务器就算读到过期键,也不会删除
- 只有从服务器获取命令那么才会删除,保证主从一致性。
9.8 数据库通知
- 主要就是语句对某个键做了什么操作,数据库通知客户端,让客户端感知到数据库的变化。这个是键空间通知。
127.0.0.1:6379> SUBSCRIBE _ _keyspace@0_ _:message
Reading messages... (press Ctrl-C to quit)
1) "subscribe" //
订阅信息
2) "__keyspace@0__:message"
3) (integer) 1
1) "message" //
执行SET
命令
2) "_ _keyspace@0_ _:message"
3) "set"
1) "message" //
执行EXPIRE
命令
2) "_ _keyspace@0_ _:message"
3) "expire"
1) "message" //
执行DEL
命令
2) "_ _keyspace@0_ _:message"
3) "del"
- 这种是对键的事件进行通知,就是看数据库对哪个键操作了,那么就返回这个键。这个就是键时间通知。
127.0.0.1:6379> SUBSCRIBE _ _keyevent@0_ _:del
Reading messages... (press Ctrl-C to quit)
1) "subscribe" //
订阅信息
2) "_ _keyevent@0_ _:del"
3) (integer) 1
1) "message" //
键key
执行了DEL
命令
2) "_ _keyevent@0_ _:del"
3) "key"
1) "message" //
键number
执行了DEL
命令
2) "_ _keyevent@0_ _:del"
3) "number"
1) "message" //
键message
执行了DEL
命令
2) "_ _keyevent@0_ _:del"
3) "message"
- notify-keyspace-events可以设置为我们需要的通知类型
- AKE:键空间通知和键事件通知。
- AK:键空间通知
- AE:键事件通知。
9.8.1 发送通知
- notify.c/notifyKeyspaceEvent函数来实现通知。
void notifyKeyspaceEvent(int type,char *event,robj *key,int dbid);
-
type决定了发送通知的类型。
-
event、key、dbid是事件的名称、产生事件的键、以及产生时间的数据库号码。
-
每个redis命令如果要发送通知就会调用notify-KeyspaceEvent函数
-
比如sadd
void saddCommand(redisClient*c){
// ...
//
如果至少有一个元素被成功添加,那么执行以下程序
if (added) {
// ...
//
发送事件通知
notifyKeyspaceEvent(REDIS_NOTIFY_SET,"sadd",c->argv[1],c->db->id);
}
// ...
}
9.8.2 发送通知的实现
- type如果不是服务器允许发送的类型那么就不能发送。server.notify_keyspace_events就是之前设置好的通知参数。
- 接下来就是判断是不是键空间通知发送,如果是就发送
- 最后就看看是不是键事件发送。
def notifyKeyspaceEvent(type, event, key, dbid):
#
如果给定的通知不是服务器允许发送的通知,那么直接返回
if not(server.notify_keyspace_events & type):
return
#
发送键空间通知
if server.notify_keyspace_events & REDIS_NOTIFY_KEYSPACE:
#
将通知发送给频道__keyspace@<dbid>__:<key>
#
内容为键所发生的事件 <event>
#
构建频道名字
chan = "__keyspace@{dbid}__:{key}".format(dbid=dbid, key=key)
#
发送通知
pubsubPublishMessage(chan, event)
#
发送键事件通知
if server.notify_keyspace_events & REDIS_NOTIFY_KEYEVENT:
#
将通知发送给频道__keyevent@<dbid>__:<event>
内容为发生事件的键 <key>
#
构建频道名字
chan = "__keyevent@{dbid}__:{event}".format(dbid=dbid,event=event)
#
发送通知
pubsubPublishMessage(chan, key)
9.9 重点回顾
- redis数据库都存在了redisServer.db中,数据库数量在redisServer.num中
- 客户端可以修改数据库指针访问数据库
- 数据库其实就是一个字典组成。键对应各种值对象
- 过期字典里面过期时间是一个unix时间戳
- redis的删除过期键策略
- 定期
- 惰性
- save和bgsave都要检查过期键
- aof的写入不需要管过期键
- 但是aof重写需要过滤过期键。
第10章 RDB持久化
- redis的数据存于内存中,所以持久化就需要RDB的支持
- 通过写入多个数据库到RDB,并且下次使用的时候恢复数据库。
10.1 RDB文件的创建与载入
- save和bgsave都可以生成RDB文件
- save:数据库会停止所有服务,并且专心写入RDB文件
- bgsave:开创一个子进程去完成RDB的写入。并且主进程还是在处理请求。
- 下面的函数就可以看出他们的区别。
def SAVE():
#
创建RDB
文件
rdbSave()
def BGSAVE():
#
创建子进程
pid = fork()
if pid == 0:
#
子进程负责创建RDB
文件
rdbSave()
#
完成之后向父进程发送信号
signal_parent()
elif pid > 0:
#
父进程继续处理命令请求,并通过轮询等待子进程的信号
handle_request_and_wait_signal()
else:
#
处理出错情况
handle_fork_error()
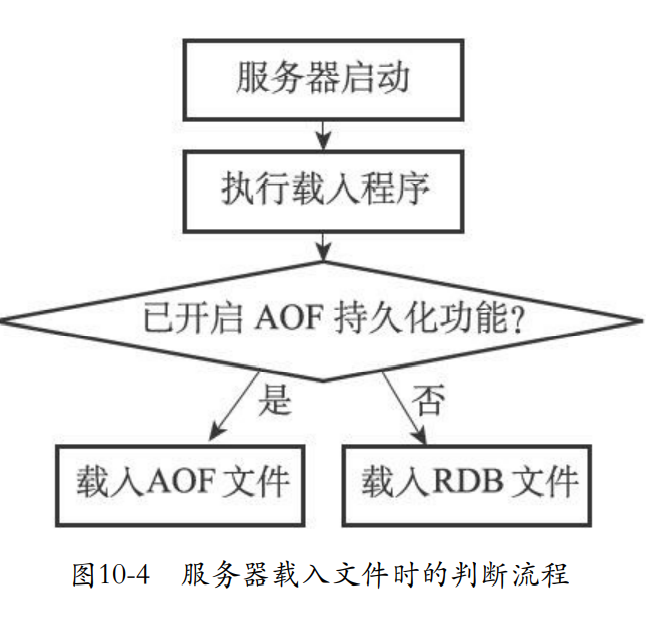
- 载入没有特别的命令,每次服务器启动就会自动载入RDB文件。
- 如果使用AOF那么就会优先AOF的持久化。
10.1.1 SAVE命令执行时的服务器状态
- save会阻塞服务器的所有处理。
- 只有执行完才会让服务器去处理请求。
10.1.2 BGSAVE命令执行时的服务器状态
- bgsave通过子进程来完成RDB写入。
- bgsave和save不能同时执行,会产生竞争条件
- BGSAVE期间,bgrewriteaof会等待bgsave执行后执行
- 但是bgrewriteaof期间bgsave会被拒绝,防止两个子进程同时写入磁盘。
10.1.3 RDB文件载入时的服务器状态
- 服务器载入的时候那么就会进入阻塞状态
10.2 自动间隔性保存
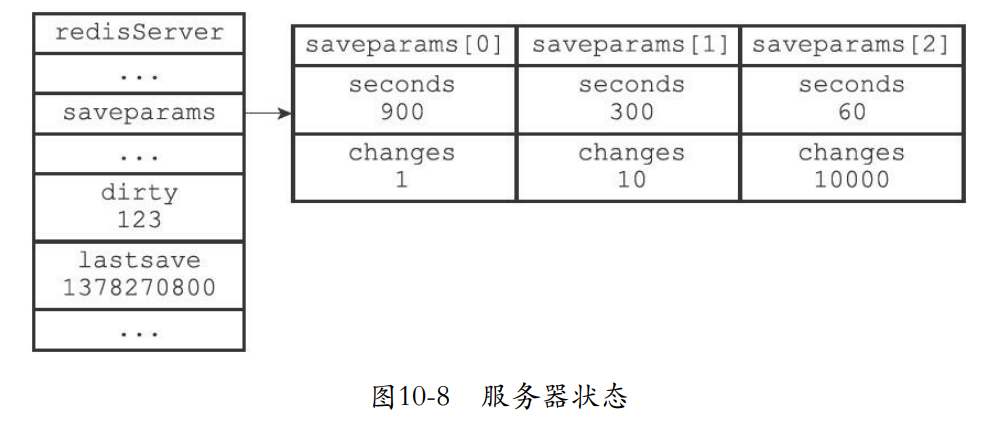
- 下面这个是bgsave的执行条件,每900s如果至少更新一次那么就要写入RDB,调用bgsave
save 900 1
save 300 10
save 60 10000
10.2.1 设置保存条件
- 上面是默认选项,我们可以自己设置。
- 设置之后这些参数会保存到下面的redisServer的结构中。
struct redisServer {
// ...
//
记录了保存条件的数组
struct saveparam *saveparams;
// ...
};
struct saveparam {
//
秒数
time_t seconds;
//
修改数
int changes;
};
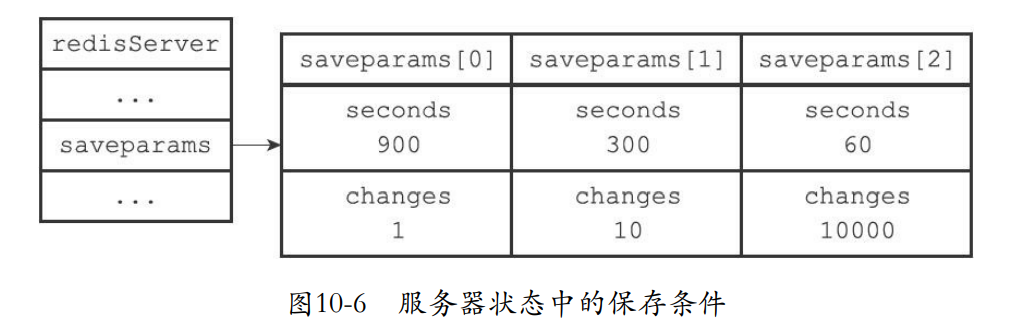
10.2.2 dirty计数器和lastsave属性
- 服务还维护了一个dirty计数器和一个lastsave
- dirty:距离上一次save或者bgsave之后修改了多少次
- lastsave:上一次save的unix时间戳
struct redisServer {
// ...
//
修改计数器
long long dirty;
//
上一次执行保存的时间
time_t lastsave;
// ...
};
10.2.3 检查保存条件是否满足
- redis的serverCron会周期性执行一次检查是否满足保存RDB条件。
- 条件就是我们设置的保存条件,程序会进行遍历。如果符合立刻调用bgsave
- 更新之后就会重新设置这个dirty和上一次修改的时间。
def serverCron():
# ...
#
遍历所有保存条件
for saveparam in server.saveparams:
#
计算距离上次执行保存操作有多少秒
save_interval = unixtime_now()-server.lastsave
#
如果数据库状态的修改次数超过条件所设置的次数
#
并且距离上次保存的时间超过条件所设置的时
那么执行保存操作
if server.dirty >= saveparam.changes and \
save_interval > saveparam.seconds:
BGSAVE()
# ...

10.3 RDB文件结构

- 开头部分redis长度是5个字节。
- db_version:长度4个字节,表示RDB的版本号
- databases:0个或者多个数据库键值对数据
- EOF:说明正文结束,也就是数据库键值对载入完毕
- check_sum就是校验号

10.3.1 databases部分


- 数据库在RDB的存储结构
- selectdb:遇到这个值说明后面就是数据库的编号,占用1个字节
- db_number:数据库编号,长度可以是1字节,2字节,5字节
- key_value_pairs:保存数据库所有的键值对数据。

10.3.2 key_value_pairs部分
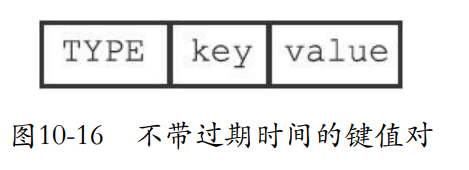
- type记录了值对象的类型。也就是对象的encoding编码。
- key:就是键,而且一定是字符串对象。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s67EVD6J-1637163359271)(C:/Users/11914/AppData/Roaming/Typora/typora-user-images/image-20211117171356903.png)]
- EXPIRETIME_MS:遇到这个说明后面那个就是过期时间,单位是毫秒。
10.3.3 value的编码
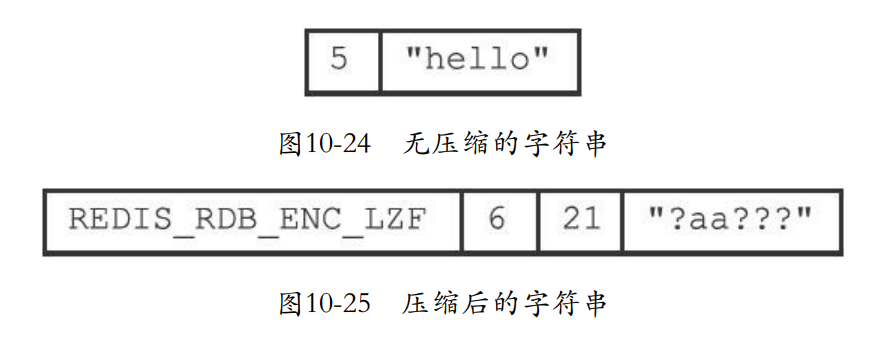
1.字符串对象
-
如果TYPE是REDIS_RDB_TYPE_STRING,那么字符串的编码就可能是REDIS_ENCODING_INT(不超过32位的整数)或者REDIS_ENCODING_RAW。
-
如果int类型,可能是8位也可能是16位等。

- 如果是字符串那么直接使用raw,而且小于20字节不需要压缩

- 大于20字节那么字符串就要被压缩。

2.列表对象
- 如果TYPE的值为REDIS_RDB_TYPE_LIST,那么value的保存就是REDIS_ENCODING_LINKEDLIST,下面就是在RDB的结构。
- 前一个是字符串长度,后一个是值。比如5和hello
- 第一个3就是列表有多少个元素。


3.集合对象
- 如果type是REDIS_RDB_TYPE_SET,那么value的值就是REDIS_ENCODING_HT编码的集合对象。
- 对于每elemx,前面一个是长度,后面一个是字符串。比如5和apple。还有6和banana


4.哈希表对象
- 对于TYPE的值为REDIS_RDB_TYPE_HASH,value保存的编码是REDIS_ENCODING_HT编码的集合对象。
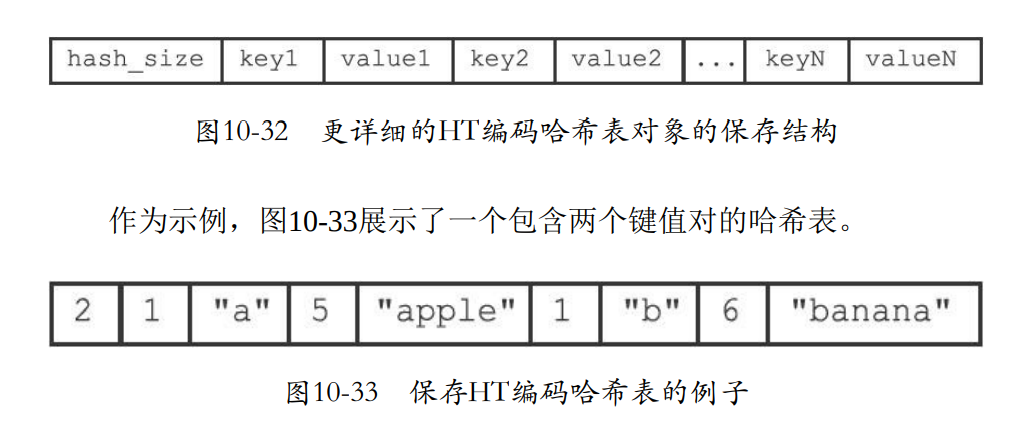
- hash_size就是哈希的长度
- key1和value1挨着存放。分别有长度和值。
5.有序集合对象
- 如果type是REDIS_RDB_TYPE_ZSET,那么value保存的编码是REDIS_ENCODING_SKIPLIST编码。那么就是member+分值字符串的存储。


6.INTSET编码的集合
- TYPE的值为REDIS_RDB_TYPE_SET_INTSET,那么value的保存的就是一个整数集合的对象。把这个整数集合转变成字符串然后再存入RDB文件
7.ZIPLIST编码的列表、哈希表或者有序集合
- 如果TYPE的值为REDIS_RDB_TYPE_LIST_ZIPLIST、 REDIS_RDB_TYPE_HASH_ZIPLIST或者 REDIS_RDB_TYPE_ZSET_ZIPLIST
- value就是压缩列表对象。
- 压缩列表转换成字符串对象。存入RDB
10.4 分析RDB文件
10.4.1 不包含任何键值对的RDB文件
- 可以使用od命令来看看整个文件的存储结构。
- 下面就是一个空文件结构。
- 五个字节的redis
- 四个字节是版本号0006
- 一个字节EOF,377
- 八个字节的校验和。334 263 C 360 Z 334 362 V
$ od -c dump.rdb
0000000 R E D I S 0 0 0 6 377 334 263 C 360 Z 334
0000020 362 V
0000022
- 下面是设置一个msg键
- \0 003 M S G 005 H E L L O这部分就是存储的键值对类型。
- 0006之后的376就是selectdb常量
$ od -c dump.rdb
0000000 R E D I S 0 0 0 6 376 \0 \0 003 M S G
0000020 005 H E L L O 377 207 z = 304 f T L 343
0000037
- 下面设置了过期时间
- REDIS0006:文件标志和版本号
- 376\0切换到0数据库也就是selectdb+数据库编号、
- 374:就是expiretime_ms常量
- \2 365 336@001\0\0:八字节长的过期时间。
- \0 003 M S G:\0表示的是字符串键,003是键的长度,msg就是内容
- 377:就是EOF的常量
- 后面全部都是校验和。
redis> FLUSHALL
OK
redis> SETEX MSG 10086 "HELLO"
OK
redis> SAVE
OK
$ od -c dump.rdb
0000000 R E D I S 0 0 0 6 376 \0 374 \ 2 365 336
0000020 @ 001 \0 \0 \0 003 M S G 005 H E L L O 377
0000040 212 231 x 247 252 } 021 306
0000050
10.5 重点回顾
- RDB文件用于恢复数据库
- save保存会阻塞,但是bgsave不会
- RDB是一个二进制文件,多个部分组成,包括databases,EOF,校验码,还有就是版本号等。常量+值。
第11章 AOF持久化
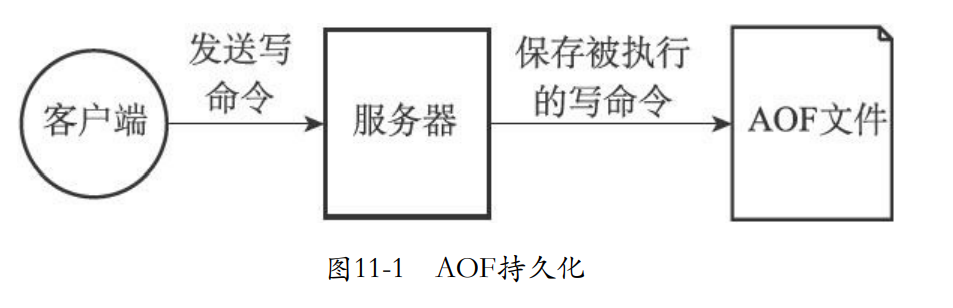
- 下面的这三个命令都会保存到AOF
- AOF就是通过重新执行命令操作恢复数据库。
- AOF所有命令都是redis命令的请求协议格式保存。
redis> SET msg "hello"
OK
redis> SADD fruits "apple" "banana" "cherry"
(integer) 3
redis> RPUSH numbers 128 256 512
(integer) 3
11.1 AOF持久化的实现
分为三个步骤
- append命令追加
- 文件写入
- 文件同步
11.1.1 命令追加
- 执行完写命令后会把命令写入到aof_buf缓冲区末尾
struct redisServer {
// ...
// AOF
缓冲区
sds aof_buf;
// ...
};
11.1.2 AOF文件的写入与同步
- redis服务器进程就是事件循环。每个事件可能是接收客户端请求,以及回复。
- 所以执行写命令的时候可以调用flushAppendOnlyFile函数。考虑是不是要把aof_buf缓冲区写入。和保存到AOF文件里面。
def eventLoop():
while True:
#
处理文件事件,接收命令请求以及发送命令回复
#
处理命令请求时可能会有新内容被追加到 aof_buf
缓冲区中
processFileEvents()
#
处理时间事件
processTimeEvents()
#
考虑是否要将 aof_buf
中的内容写入和保存到 AOF
文件里面
flushAppendOnlyFile()
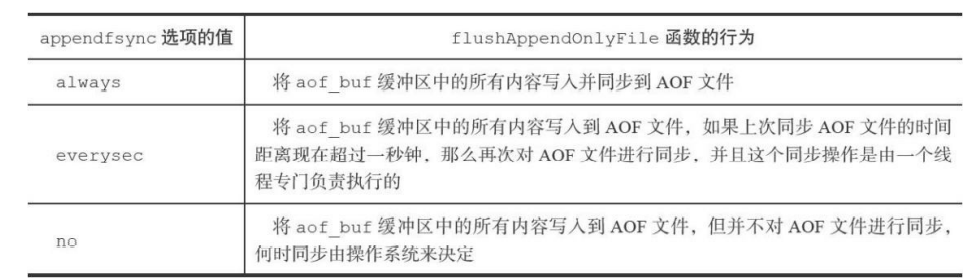
- appendfsync选项决定了flushAppendOnlyFile的行为。默认是everysec,必须是距离上一次同步超过1s才能够写入。这次写入只是写入到操作系统的缓存区。然后再同步到磁盘
- appendfync参数介绍
- always:每个事件都要刷新aof缓存写入aof文件,并且同步。它比较慢,但是如果发生故障丢失的命令数据很少
- everysec:每隔一秒就要同步一次,这种最多只会丢失1s的数据。
- no:宕机的话所有数据丢失,但是写入aof文件速度最快。同步由操作系统决定。
11.2 AOF文件的载入与数据还原
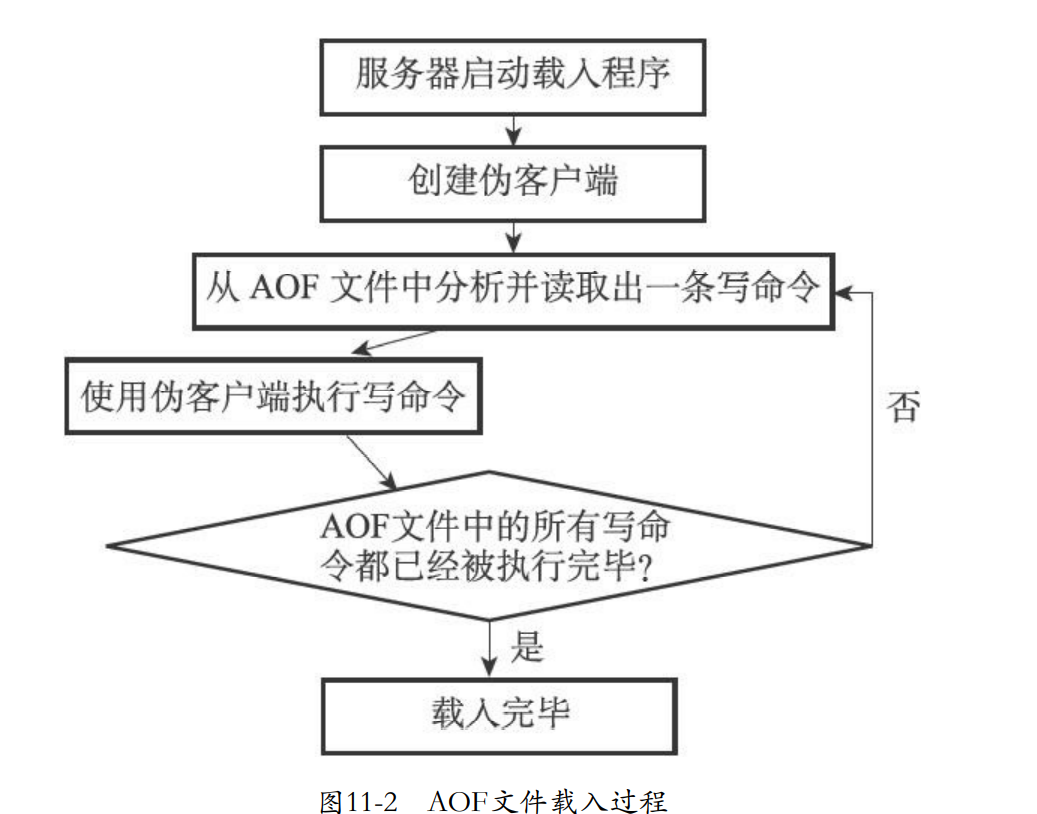
- 载入只需要重新执行AOF的所有命令。
还原步骤
- 创建一个不带网络连接的伪客户端,执行AOF的保存的写命令。
- 从aof文件分析读取写命令。
- 使用伪客户端执行被读出的写命令。
- 然后一直重复2和3直到所有写命令被使用完。
- 服务器先读入select 0,然后就是set,sadd等命令执行。还原状态。
*2\r\n$6\r\nSELECT\r\n$1\r\n0\r\n
*3\r\n$3\r\nSET\r\n$3\r\nmsg\r\n$5\r\nhello\r\n
*5\r\n$4\r\nSADD\r\n$6\r\nfruits\r\n$5\r\napple\r\n$6\r\nbanana\r\n$6\r\ncherry\r\n
*5\r\n$5\r\nRPUSH\r\n$7\r\nnumbers\r\n$3\r\n128\r\n$3\r\n256\r\n$3\
11.3 AOF重写
- AOF持久化的原理就是执行保存的写命令来恢复数据库。
- 所以AOF会越来越大。因为命令不断在追加。
- 所以需要减少AOF的体积,这个时候就需要重写。
11.3.1 AOF文件重写的实现
- AOF重写通过读取数据库的状态而不是旧的AOF文件生成的。
- 假设执行下面的命令,AOF文件就要存入6个命令,重写AOF的话直接看数据库状态,只生成一条语句就可以完成了。
redis> RPUSH list "A" "B" // ["A", "B"]
(integer) 2
redis> RPUSH list "C" // ["A", "B", "C"]
(integer) 3
redis> RPUSH list "D" "E" // ["A", "B", "C", "D", "E"]
(integer) 5
redis> LPOP list // ["B", "C", "D", "E"]
"A"
redis> LPOP list // ["C", "D", "E"]
"B"
redis> RPUSH list "F" "G" // ["C", "D", "E", "F", "G"]
(integer) 5
- 对于下面的命令可以综合为一条SADD animals"Dog"“Panda”“Tiger”“Lion”“Cat”
redis> SADD animals "Cat"
// {
"Cat"}
(integer) 1
redis> SADD animals "Dog" "Panda" "Tiger" // {
"Cat", "Dog", "Panda", "Tiger"}
(integer) 3
redis> SREM animals "Cat" // {
"Dog", "Panda", "Tiger"}
(integer) 1
redis> SADD animals "Lion" "Cat" // {
"Dog", "Panda", "Tiger",
(integer) 2 "Lion", "Cat"}
- 整个重写过程
- 遍历数据库
- 遍历数据库的所有的键值对,然后重写,忽略过期的键。
- 关闭文件
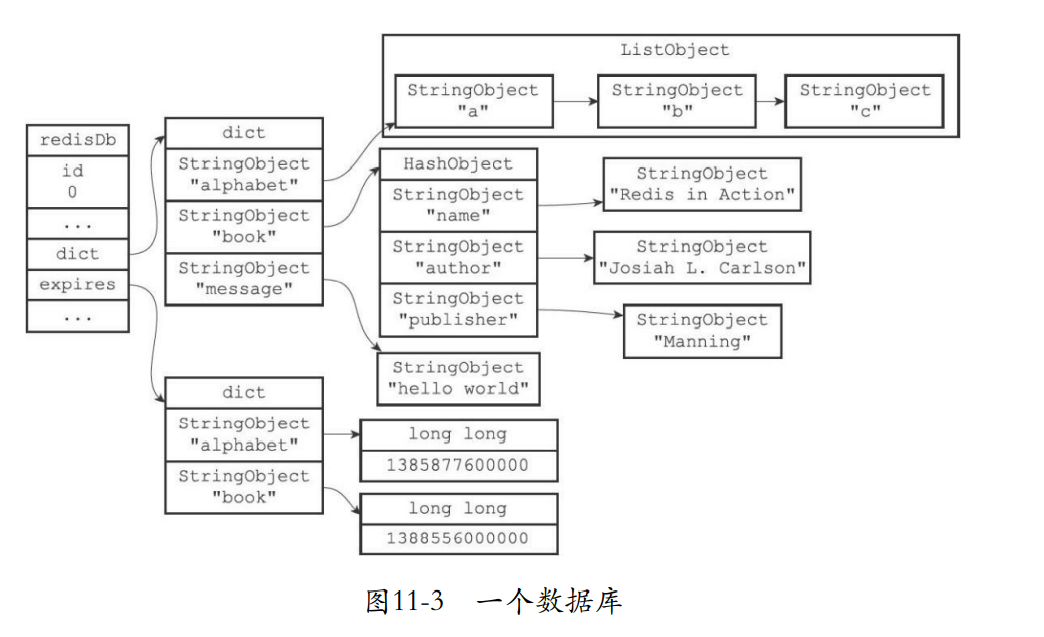
- 对于下面的数据库,重写之后的所有命令
SELECT 0
RPUSH alphabet "a" "b" "c"
EXPIREAT alphabet 1385877600000
HMSET book "name" "Redisin Action"
"author" "Josiah L. Carlson"
"publisher" "Manning"
EXPIREAT book 1388556000000
SET message "hello world"
-
-
客户端缓冲区如果不够用,就需要通过多条命令来写。
11.3.2 AOF后台重写
- aof_rewrite函数完成了aof重写
- 但是重写aof的时候要保证服务器端被阻塞,所以可能就是重写线程由于服务器写入操作太多,一直被阻塞。
- 所以要把aof重写让子进程进行处理。
- 服务器进程可以处理命令
- 子进程带有服务器副本,所以可以避免争夺锁的情况。因为线程需要争夺数据的锁才能够进行修改。
- 但是子进程异步执行,主进程仍然可以接收请求修改数据库。所以可能导致aof和当前数据库的状态不一致。