强化学习
这一章会讲基于策略的强化学习Policy-based Reinforcement learning
前言
说明一下:这是我的一个学习笔记,课程链接如下:最易懂的强化学习课程
公众号:AI那些事

一、policy函数
我们回顾一下Action-Value Functions:

Policy函数记作π(a|s),是一个概率密度函数,我们可以用他来自动控制agent运动,策略函数的输入是当前状态s,它的输出是一个概率分布,给每一个输出一个概率值,有了各个动作的概率值,agent就会做一次随机抽样得到动作a,每个动作都可能被抽到,概率越大的动作越容易被抽到。
所以说只要有了一个好的策略函数π,我们就可以用π来自动控制agent运动,但是我们怎样才能得到这个策略函数呢?
假如这个游戏只有5个动作10个状态那很好办,我们画一张5*10的表,表里面每一格对应一个概率,我们通过玩游戏将这50个概率值算出来就可以了,但是超级玛丽这种游戏有无数个状态,我没法将每个状态的每个动作的概率记在一张表里,想要agent自动玩超级玛丽这种游戏,我没法直接算策略函数。
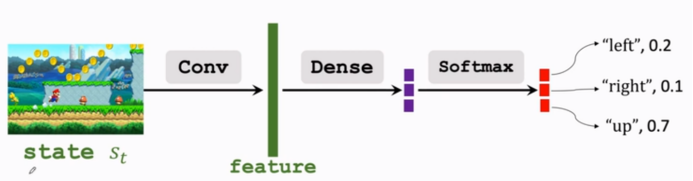
所以我得到函数近似,学出来一个函数来近似策略函数,函数近似的方法有很多,可以用线性函数、神经网络等,如果用神经网络的话,我们可以将这个函数称为Policy network策略网络,把它记为π(a|s;θ),这里的θ是神经网络的参数,一开始θ是初始化的,然后我们通过学习来改进θ,如果是超级玛丽这个问题我们可以将神经网络设置为:
由于策略函数π是一个概率密度函数,所以π要满足:
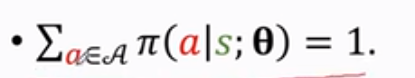
这是什么意思呢?是对于所有的动作a,把π函数的输出都加起来要等于1。
这也是为什么要在输出时放一个softmax激活函数,softmax让输出的都可以是正数,而且加和等于1。
二、state value function
我们来看状态价值函数state value function,并且对它做函数近似。
首先回顾一下DR:

折扣回报Ut,它的定义是从t时开始,未来所有奖励的加权求和,在t时刻未来的奖励R还没有观测到,所以,用大写字母表示,每个奖励的随机性都来自于前一时刻的动作和状态,动作的随机性来自于策略函数π,状态函数的随机性,来自于状态转移函数p,由于Ut是所有奖励的加和,Ut的随机性来自于未来所有的动作和状态。

Action value function动作价值函数Qπ是Ut的条件期望,这个期望把t+1时刻以后的动作和状态都消掉了,Qπ只依赖当前的状态st和动作at,Qπ还依赖于动作函数π,用不同的π得到的Qπ是不一样的,Qπ可以评价在状态st的情况下做出at的好坏程度。
state-value function,状态价值函数Vπ,Vπ是Qπ的期望,把Qπ中的动作A积掉,这里的动作A被当做随机变量,概率密度函数是π,将A消掉,这样的话Vπ只和策略函数π、当前的状态s有关了,给定策略函数π,Vπ可以评价当前状态的好坏,Vπ越大证明当前的胜算越大,给定状态S,Vπ可以评价策略π的好坏,如果π很好,Vπ就比较大,胜算就大,反之胜算就小。
如果A是离散变量,Qπ的期望就可以这样展开:

对于所有的动作a,把Qπ与概率密度函数的内积做连加,这样A就被消掉了。假如a是一个连续变量,就需要采取积分代替连加。
三、ploicy-based reinforcement learning
下面我们讲ploicy-based reinforcement learning(策略学习)
刚才我们用神经网络近似了策略函数π,现在,我们用神经网络来近似Vπ:
我们知道π的近似函数可以写成:

现在,我们将Vπ中的π用神经网络来替代,Vπ就变成V(St;θ),这里的θ是神经网络中的参数。
3.1 策略学习的主要思想
我们刚才用了策略网路来近似策略函数,这样一来,状态价值函数就可以写成:
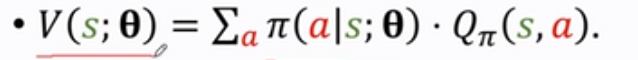
V可以评价状态s和策略网络的好坏,给定状态s,策略网络越好,v的值就越大,那么怎么才能然v的值变得越来越好呢?
对,我们可以改进模型参数θ,来让V(s;θ)变大。
基于这个想法,我们就可以把目标函数定义为V(s;θ)的期望,记为J(θ),这个期望是关于s求的,这里把s作为一个随机变量用期望给去掉,这样一来变量只剩下θ了,目标函数J(θ)就是对策略网络的评价,策略网络越好,J(θ)越大,所以呢,策略学习policy based learning目标就是改进θ,使得J(θ)越大越好,怎么样才能使J(θ)越大,怎么去改进θ呢?
我们需要采用策略梯度算法policy gradient ascent,让agent玩游戏,每一步都会观测到一个不同的状态s,这个s就相当于是从状态的概率分布中随机抽样得来的,θ的更新我们用下列公式:
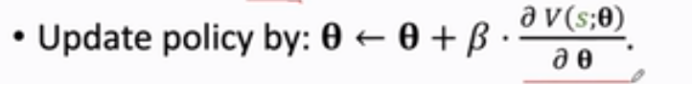
我们用梯度上升来更新θ,这里的β是学习率,其中V(s;θ)关于θ求导不是梯度,真正的梯度是J(θ)关于θ求导,这里的V(s;θ)关于θ求导是一个随机梯度,随机性来源于s,为什么要用梯度上升呢?因为我们需要J(θ)越来越大,这里V(s;θ)关于θ的倒数我们称它为策略梯度-policy gradient。

3.2 如何求策略梯度
下面我们讲为怎么求policy gradient
由于:
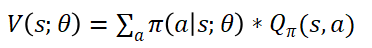
所以求V(s;θ)关于θ的倒数为:

这里面我们将Qπ看做一个常数,就是认为它和θ无关,但这是不太对的,因为Qπ和π有关,而θ是π的参数,所以它们是有关的,这个推导并不严谨,但是能让我们比较容易理解。
最终我们能够得到下列公式:

有人会有疑问,第二行的公式怎么得来的,我们可以从第二个往第一个推,能够推出来:
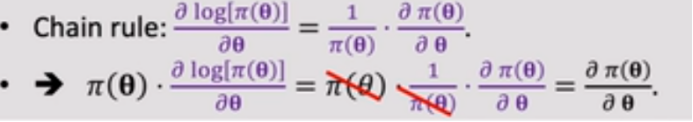
我们已经推出来了策略梯度的两种形式,这两个形式是等价的:

有了上述两个公式,我们就能够实际计算策略梯度了:

如果动作是离散的,我们可以用第一个公式:

具体是怎么计算策略梯度呢?
我们将π(a|s;θ)关于θ的倒数和Qπ的乘积作为函数f(a,θ),对于每个动作a,我们将f(a,θ)的值计算出来就好了。
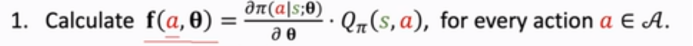
根据上述的公式,对于离散动作的策略梯度,我们将每个动作a的f(a,θ)都计算出来再加和就好了。但这个方法不适合连续动作。
对于连续动作我们可以用第二个公式:

这里面,我们看到需要关于随机变量A求期望,A是一个连续变量,所以要求它就需要做定积分,但是积分是做不到的,因为我们的π函数是一个神经网络极其复杂,我们没法用数学公式将其算出。
这里就需要做蒙特卡洛近似,将其近似算出来:




我们已经用推导了policy gradient策略梯度,并且知道怎么样使用策略梯度来学习策略网络。下面我们总结下:

1、在t时刻观测到状态st。
2、接下来我们用蒙特卡洛近似策略梯度,将策略网络π作为概率密度函数,用它随机抽样得到一个动作at,比如说at是向左的动作。
3、然后是计算价值函数Qπ的值将结果记作qt,
4、再是对策略网络求导,算出log(π(a|s;θ)关于θ的导数,得到结果是一个向量矩阵或者张量。d(θ,t)和θ的大小是一样的。
5、第五步是近似的算策略梯度。
6、最后是根据近似的策略梯度来更新网络参数θ。

四、总结
期待大家和我交流,留言或者私信,一起学习,一起进步!麻烦大家可用关注公众号:AI那些事,感谢!!!
