在PyG中通过torch_geometric.data.Data创建一个简单的图,具有如下属性:
data.x:节点的特征矩阵,shape:[num_nodes, num_node_features]data.edge_index:边的矩阵,shape:[2, num_edges]data.edge_attr:边的属性矩阵,shape:[num_edges, num_edges_features]data.y:节点的分类任务,样本标签,shape:[num_nodes, *],图分类任务shape:[1, *]data.pos:节点的坐标,shape[num_nodes,num_dimension]
创建一个图
import torch
from torch_geometric.data import Data
# 定义了边的表示,是无向图,所以shape:[2, 4] ,(0,1)(1,0)(1,2)(2,1)
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
# 有三个节点,第0个节点特征是[-1],第一个节点特征是[0], 第二个节点特征是[1]
data = Data(x=x, edge_index=edge_index)
Data(x=[3, 1], edge_index=[2, 4])中x=[3,1]表示有三个节点,每个节点一个特征,edge_index=[2, 4]表示有四条边

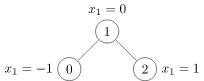
也可以通过下面的方式创建边:主要是edge_index.t().contiguous()
import torch
from torch_geometric.data import Data
edge_index = torch.tensor([[0, 1],
[1, 0],
[1, 2],
[2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index.t().contiguous())
>>> Data(edge_index=[2, 4], x=[3, 1])
除了上述的功能(节点、边、图的一些属性),data还提供了额外的方法:
print(data.keys)
>>> ['x', 'edge_index']
# 节点的特征
print(data['x'])
>>> tensor([[-1.0],
[0.0],
[1.0]])
for key, item in data:
print("{} found in data".format(key))
>>> x found in data
>>> edge_index found in data
# 边的属性
'edge_attr' in data
>>> False
# 节点的数量
data.num_nodes
>>> 3
# 边的数量
data.num_edges
>>> 4
# 节点的特征数量
data.num_node_features
>>> 1
# 是否拥有孤立的节点
data.has_isolated_nodes()
>>> False
# 是否一个环
data.has_self_loops()
>>> False
# 是不是有向图
data.is_directed()
>>> False
# Transfer data object to GPU.将data转到gpu
device = torch.device('cuda')
data = data.to(device)
创建好data之后,PyG内置了一些公开的数据集,可以导入:
from torch_geometric.datasets import TUDataset
# 数据集是对图进行分类的任务
dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES')
# 有600个图
len(dataset)
>>> 600
# 图的类别数量6
dataset.num_classes
>>> 6
# 图的每个节点的特征数量是3
dataset.num_node_features
>>> 3
# 选择第一个图
data = dataset[0]
>>> Data(edge_index=[2, 168], x=[37, 3], y=[1])
# 无向图
data.is_undirected()
>>> True
使用Cora数据集:
dataset = Planetoid(root='/tmp/Cora', name='Cora')
>>> Cora()
len(dataset)
>>> 1
dataset.num_classes
>>> 7
dataset.num_node_features
>>> 1433
# 获得这张图
data = dataset[0]
# train_mask表示训练那些节点(140个),test_mask表示测试哪些节点(1000个)
>>> Data(edge_index=[2, 10556], test_mask=[2708],
train_mask=[2708], val_mask=[2708], x=[2708, 1433], y=[2708])
data.is_undirected()
>>> True
data.train_mask.sum().item()
>>> 140
data.val_mask.sum().item()
>>> 500
data.test_mask.sum().item()
>>> 1000
PyG实现GCN、GraphSage、GAT
GCN实现
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='/tmp/Cora', name='Cora')
from torch_geometric.datasets import Planetoid
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv, SAGEConv, GATConv
dataset = Planetoid(root='/tmp/Cora', name='Cora')
class GCN_Net(torch.nn.Module):
def __init__(self, feature, hidden, classes):
super(GCN_Net, self).__init__()
self.conv1 = GCNConv(feature, hidden)
self.conv2 = GCNConv(hidden, classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GCN_Net(dataset.num_node_features, 16, dataset.num_classes).to(device)
data = dataset[0]
# optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# optimizer = torch.optim.Adam([
# dict(params=model.conv1.parameters(), weight_decay=5e-4),
# dict(params=model.conv2.parameters(), weight_decay=0)
# ], lr=0.01)
optimizer = torch.optim.Adam(model.parameters(),
lr=0.01, weight_decay=5e-4)
model.train()
for epoch in range(1000):
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
correct = out[data.train_mask].max(dim=1)[1].eq(data.y[data.train_mask]).double().sum()
# print('epoch:', epoch, ' acc:', correct / int(data.train_mask.sum()))
loss.backward()
optimizer.step()
if epoch % 10 == 9:
model.eval()
logits, accs = model(data), []
for _, mask in data('train_mask', 'val_mask', 'test_mask'):
pred = logits[mask].max(1)[1]
acc = pred.eq(data.y[mask]).sum().item() / mask.sum().item()
accs.append(acc)
log = 'Epoch: {:03d}, Train: {:.5f}, Val: {:.5f}, Test: {:.5f}'
print(log.format(epoch + 1, accs[0], accs[1], accs[2]))
# model.eval()
# _, pred = model(data).max(dim=1)
# correct = pred[data.test_mask].eq(data.y[data.test_mask]).sum()
# acc = int(correct) / int(data.test_mask.sum())
# print(acc)
GraphSage实现:
from torch_geometric.datasets import Planetoid
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv, SAGEConv, GATConv
dataset = Planetoid(root='/tmp/Cora', name='Cora')
class GraphSage_Net(torch.nn.Module):
def __init__(self, features, hidden, classes):
super(GraphSage_Net, self).__init__()
self.sage1 = SAGEConv(features, hidden)
self.sage2 = SAGEConv(hidden, classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.sage1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.sage2(x, edge_index)
return F.log_softmax(x, dim=1)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GraphSage_Net(dataset.num_node_features, 16, dataset.num_classes).to(device)
data = dataset[0]
# optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# optimizer = torch.optim.Adam([
# dict(params=model.conv1.parameters(), weight_decay=5e-4),
# dict(params=model.conv2.parameters(), weight_decay=0)
# ], lr=0.01)
optimizer = torch.optim.Adam(model.parameters(),
lr=0.01, weight_decay=5e-4)
model.train()
for epoch in range(1000):
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
correct = out[data.train_mask].max(dim=1)[1].eq(data.y[data.train_mask]).double().sum()
# print('epoch:', epoch, ' acc:', correct / int(data.train_mask.sum()))
loss.backward()
optimizer.step()
if epoch % 10 == 9:
model.eval()
logits, accs = model(data), []
for _, mask in data('train_mask', 'val_mask', 'test_mask'):
pred = logits[mask].max(1)[1]
acc = pred.eq(data.y[mask]).sum().item() / mask.sum().item()
accs.append(acc)
log = 'Epoch: {:03d}, Train: {:.5f}, Val: {:.5f}, Test: {:.5f}'
print(log.format(epoch + 1, accs[0], accs[1], accs[2]))
GAT 实现:
from torch_geometric.datasets import Planetoid
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv, SAGEConv, GATConv
dataset = Planetoid(root='/tmp/Cora', name='Cora')
class GAT_Net(torch.nn.Module):
def __init__(self, features, hidden, classes, heads=1):
super(GAT_Net, self).__init__()
self.gat1 = GATConv(features, hidden, heads=heads)
self.gat2 = GATConv(hidden * heads, classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.gat1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.gat2(x, edge_index)
return F.log_softmax(x, dim=1)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GAT_Net(dataset.num_node_features, 16, dataset.num_classes, heads=4).to(device)
data = dataset[0]
# optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# optimizer = torch.optim.Adam([
# dict(params=model.conv1.parameters(), weight_decay=5e-4),
# dict(params=model.conv2.parameters(), weight_decay=0)
# ], lr=0.01)
optimizer = torch.optim.Adam(model.parameters(),
lr=0.01, weight_decay=5e-4)
model.train()
for epoch in range(1000):
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
correct = out[data.train_mask].max(dim=1)[1].eq(data.y[data.train_mask]).double().sum()
# print('epoch:', epoch, ' acc:', correct / int(data.train_mask.sum()))
loss.backward()
optimizer.step()
if epoch % 10 == 9:
model.eval()
logits, accs = model(data), []
for _, mask in data('train_mask', 'val_mask', 'test_mask'):
pred = logits[mask].max(1)[1]
acc = pred.eq(data.y[mask]).sum().item() / mask.sum().item()
accs.append(acc)
log = 'Epoch: {:03d}, Train: {:.5f}, Val: {:.5f}, Test: {:.5f}'
print(log.format(epoch + 1, accs[0], accs[1], accs[2]))