一、Filebeat 日志收集器
1.1 Filebeat简介
Filebeat是用于“转发"和“集中日志数据”的“轻量型数据采集器",用go语言开发,相比Logstash来说轻便。
Filebeat会监视指定的日志文件路轻,收集日志事件并将数据转发到Elasticsearch、Logstash、Redis、Kafka等存储服务器器

1.2 Filebeat主要组件
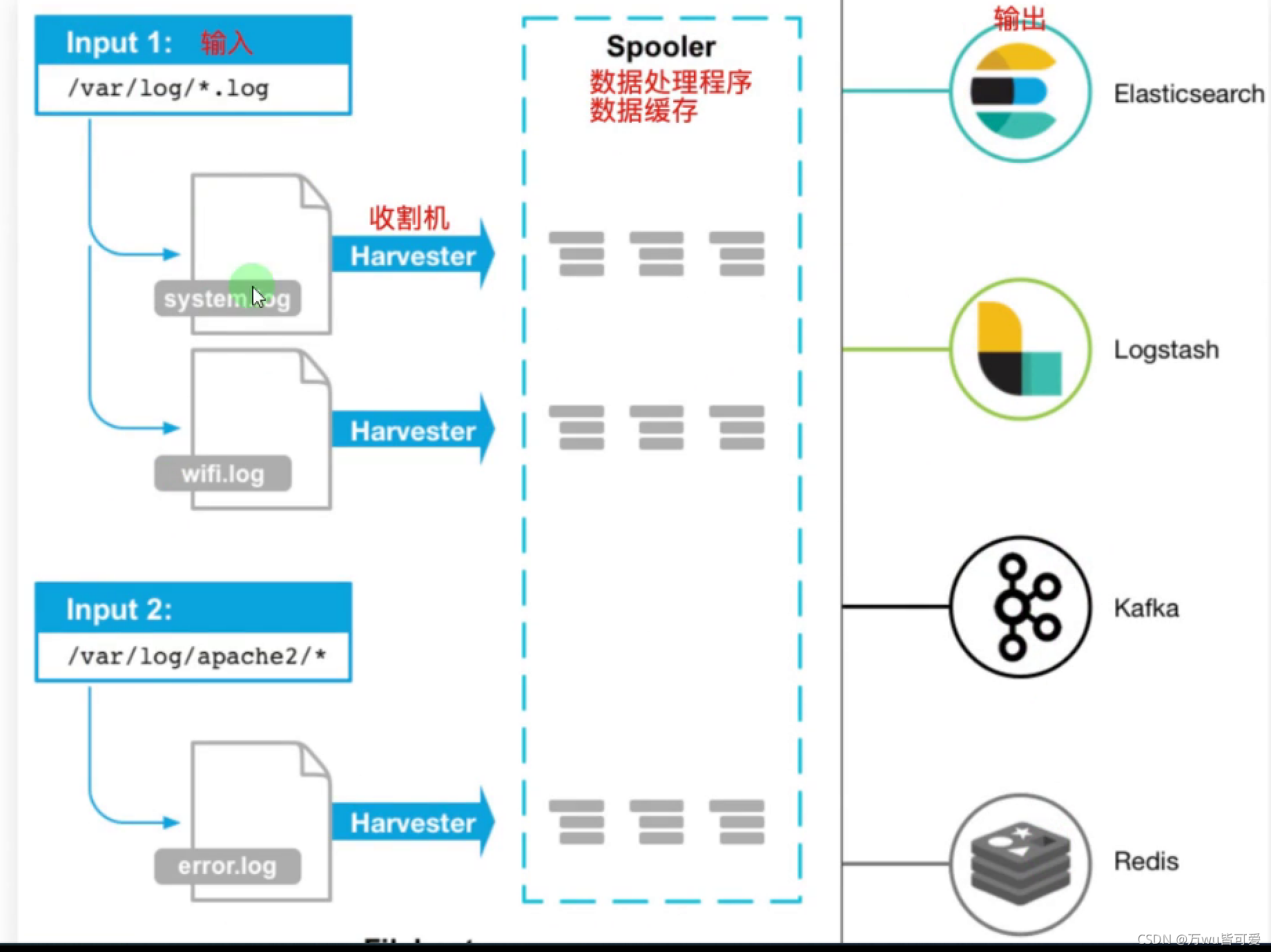
Filebeat包含两个主要组件,输入和收割机,两个组件协同工作将文件尾部最新数据发送出去
- 输入Input:输入负责管理收割机从哪个路径查找所有可读取的资源。
- 收割机Harvester:负责逐行读取单个文件的内容,然后将内容发送到输出。
1.3 Filebeat工作流程
当filebeat启动后,filebeat通过Input读取指定的日志路径,然后为该日志启动一个收割进程harvester,每一个收割进程读取一个日志文件的新内容,并发送这些新的日志数据到处理程序spooler ,处理程序会集合这些事件,最后filebeat会发送集合的数据到你指定的位置。
1.4 Filebeat 配置说明
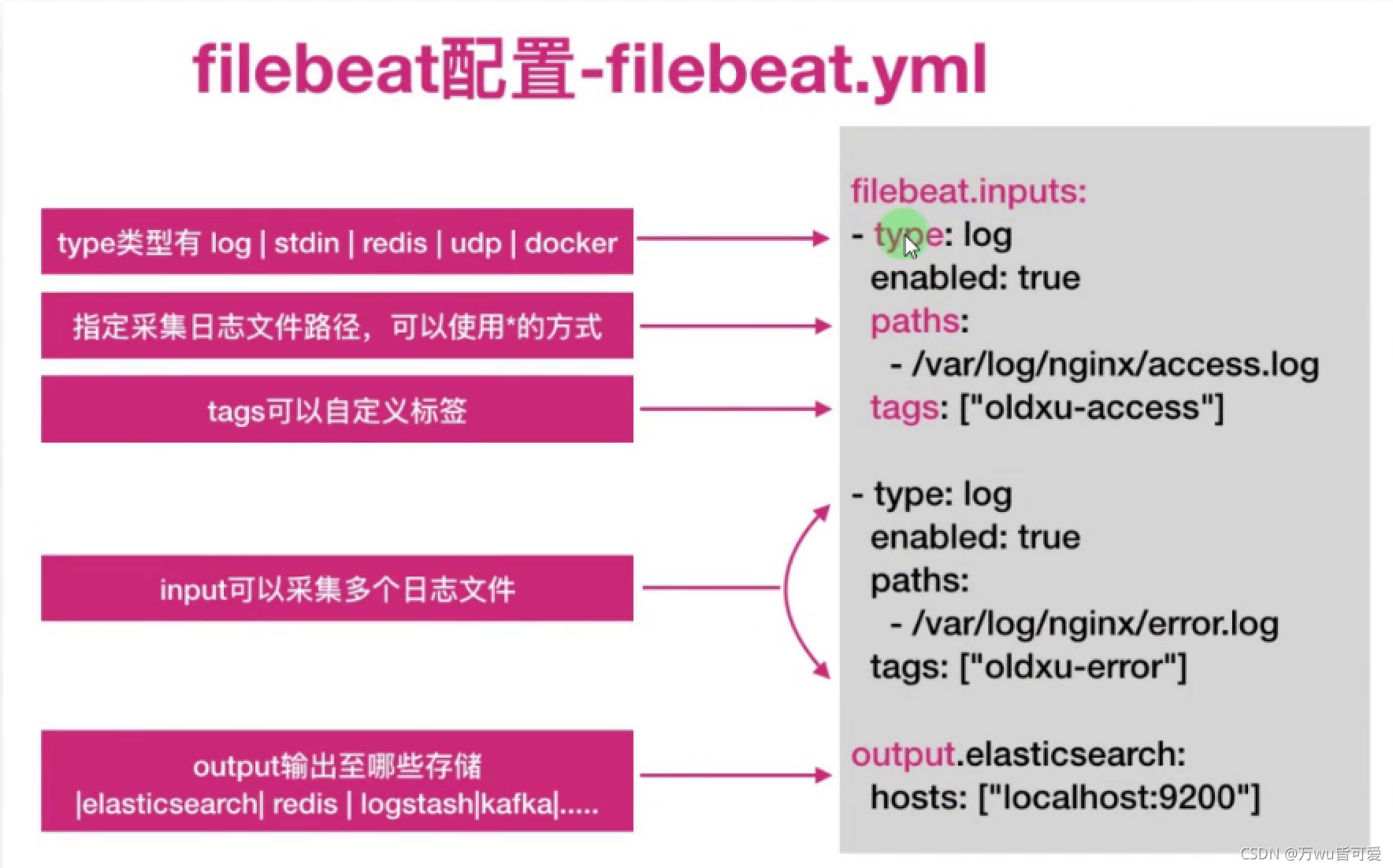
二、Filebeat基本使用
2.1 安装
需要安装在业务系统上
[root@web01 ~]# rpm -ivh filebeat-7.8.1-x86_64.rpm
启动报错: Exiting: Could not start registrar: Error loading state: Error decoding states: EOF
rm -r /var/lib/filebeat/registry
systemctl reset-failed filebeat
systemctl start filebeat
2.2 测试从终端中读入,输出到中端
[root@web01 ~]# cat /etc/filebeat/test.yml
filebeat.inputs:
- type: stdin
enabled: true
output.console:
pretty: true
enable: true
[root@web01 filebeat]# filebeat -e -c /etc/filebeat/test.yml
hello world
{
"@timestamp": "2021-10-27T13:29:07.422Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "7.8.1"
},
"log": {
"offset": 0,
"file": {
"path": ""
}
},
"message": "hello world",
"input": {
"type": "stdin"
},
"ecs": {
"version": "1.5.0"
},
"host": {
"name": "web01"
},
"agent": {
"version": "7.8.1",
"hostname": "web01",
"ephemeral_id": "3d0de9b0-b486-494a-823d-305491f44950",
"id": "457b924d-450b-49eb-8126-047091c09920",
"name": "web01",
"type": "filebeat"
}
}
2.3 从文件中读取数据,输出到中端
1.修改yml文件
[root@web01 ~]# cat /etc/filebeat/test.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/test.log
output.console:
pretty: true
enable: true
2.创建/var/log/test.log目录
3.启动Filebeat
[root@web01 filebeat]# filebeat -e -c /etc/filebeat/test.yml
4.另一个终端往日志中追加数据
[root@web01 ~]# echo "test log" > /var/log/test.log
5.查看中端面板,是否能获取到数据

{
"@timestamp": "2021-10-27T13:35:20.083Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "7.8.1"
},
"log": {
"offset": 0,
"file": {
"path": "/var/log/test.log"
}
},
"message": "test log",
"input": {
"type": "log"
},
"host": {
"name": "web01"
},
"agent": {
"hostname": "web01",
"ephemeral_id": "cce5fd00-ba6f-44bb-b40a-1f9e39e27986",
"id": "457b924d-450b-49eb-8126-047091c09920",
"name": "web01",
"type": "filebeat",
"version": "7.8.1"
},
"ecs": {
"version": "1.5.0"
}
}
2.5 从文件中读取数据,输入到es集群
[root@web01 filebeat]# cat /etc/filebeat/test.yml
filebeat.inputs:
- type: log # 日志类型
enabled: true # 启动收集
paths:
- /var/log/test.log # 日志路径
output.elasticsearch:
hosts: ["172.16.1.161:9200"] # es集群ip+port
# 如果不自定义索引,则默认索引为filebeat
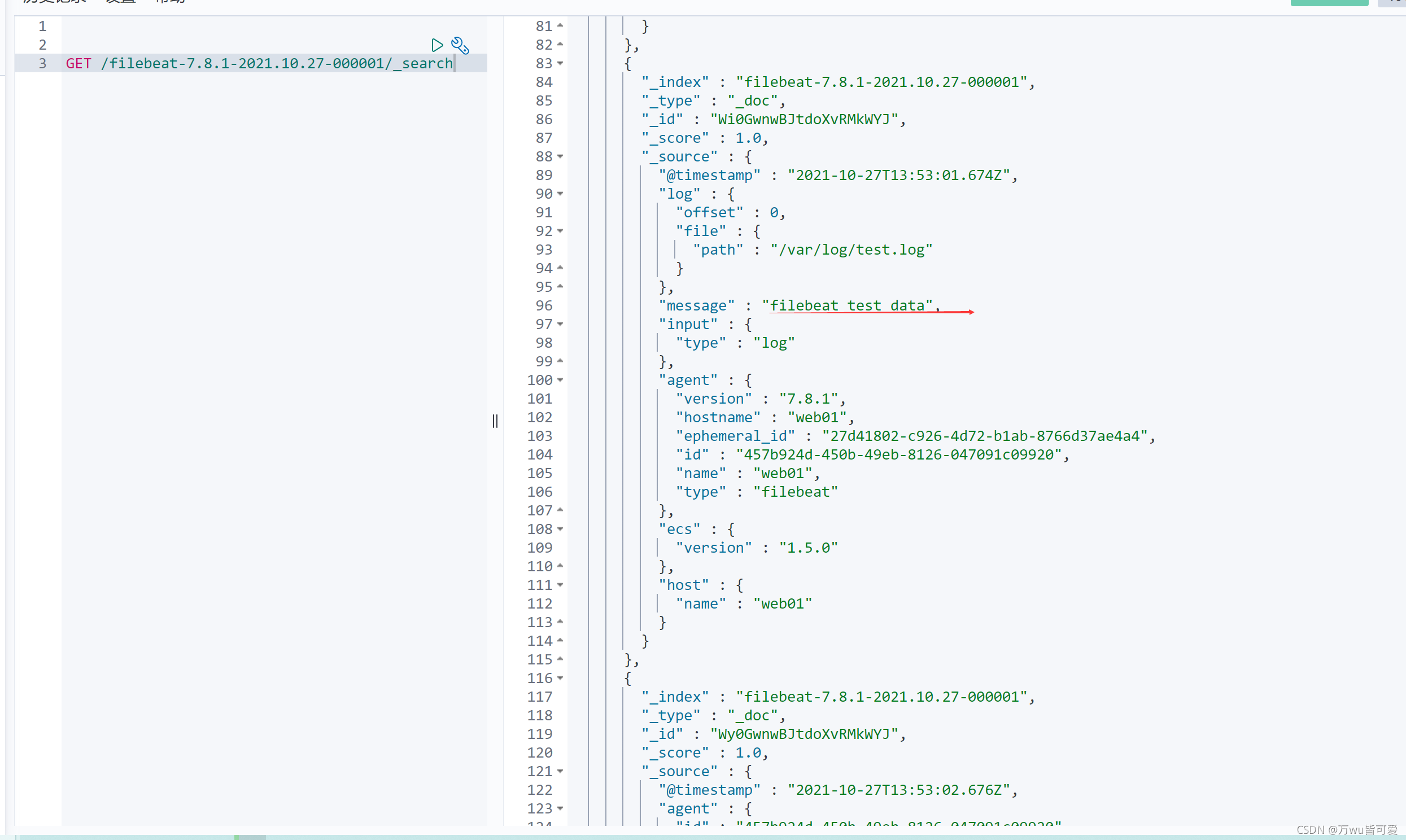
模拟日志追加数据
[root@web01 ~]# echo "filebeat test data" > /var/log/test.log
[root@web01 ~]# echo "filebeat test data123" > /var/log/test.log
去
cerebro中查看,可以看到索引,
去kibana中查看具体的数据
2.6 输出至ES集群实战
[root@web01 filebeat]# cat filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths: /var/log/messages
output.elasticsearch:
hosts: ["172.16.1.161:9200","172.16.1.162:9200","172.16.1.163:9200"]
2.7 自定义索引
默认在kibana中查看字段不方便,其实可以在Discove中查看,但是首先需要自定义索引。
kibana中点击 StackManagement ----> 创建索引模式
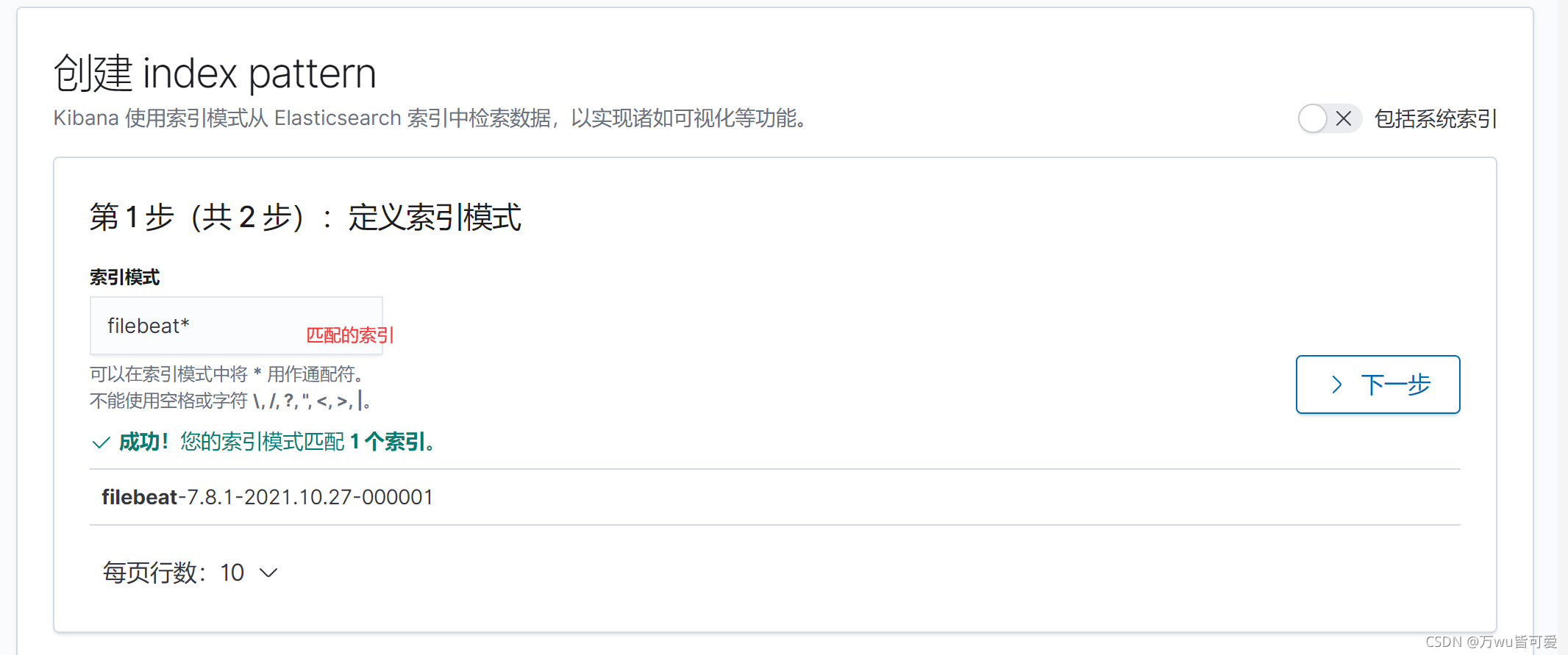
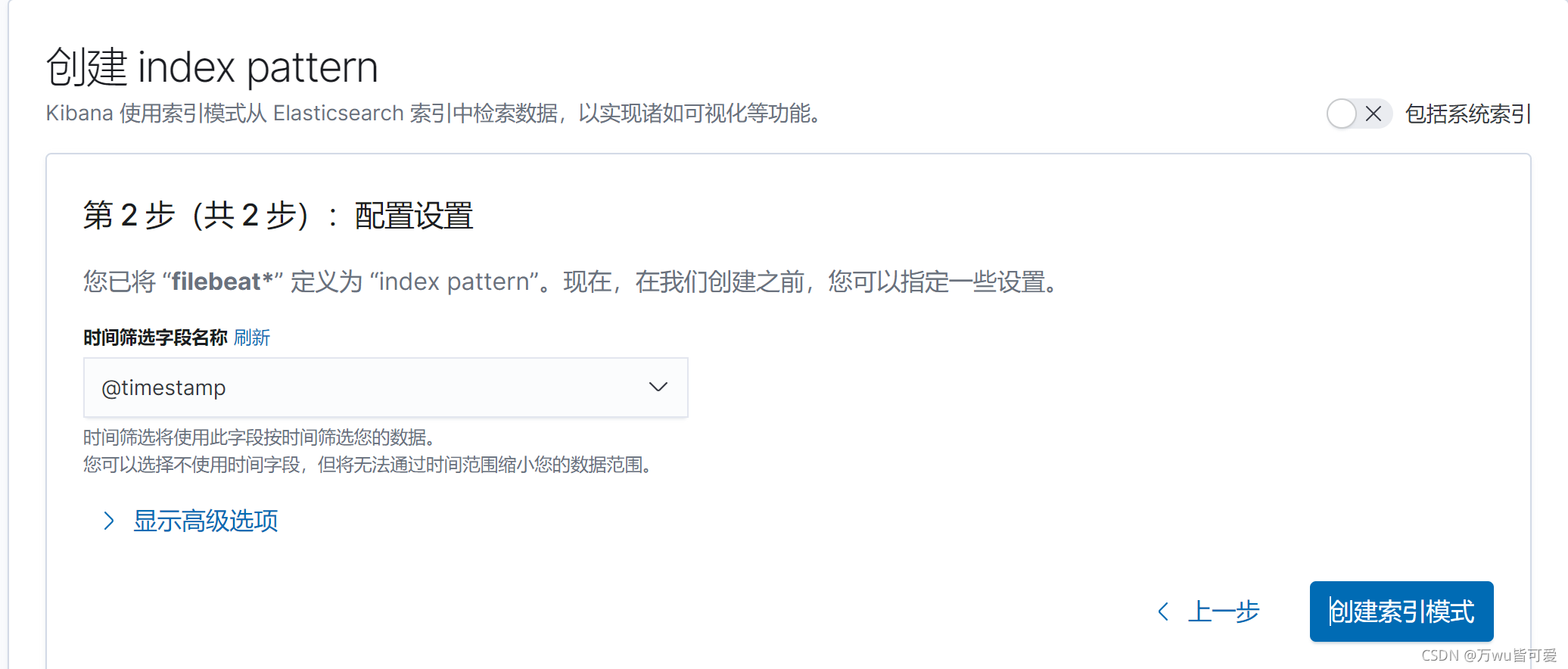
点击Discover
自己追加日志
[root@web01 ~]# echo "test bertwu" >> /var/log/messages
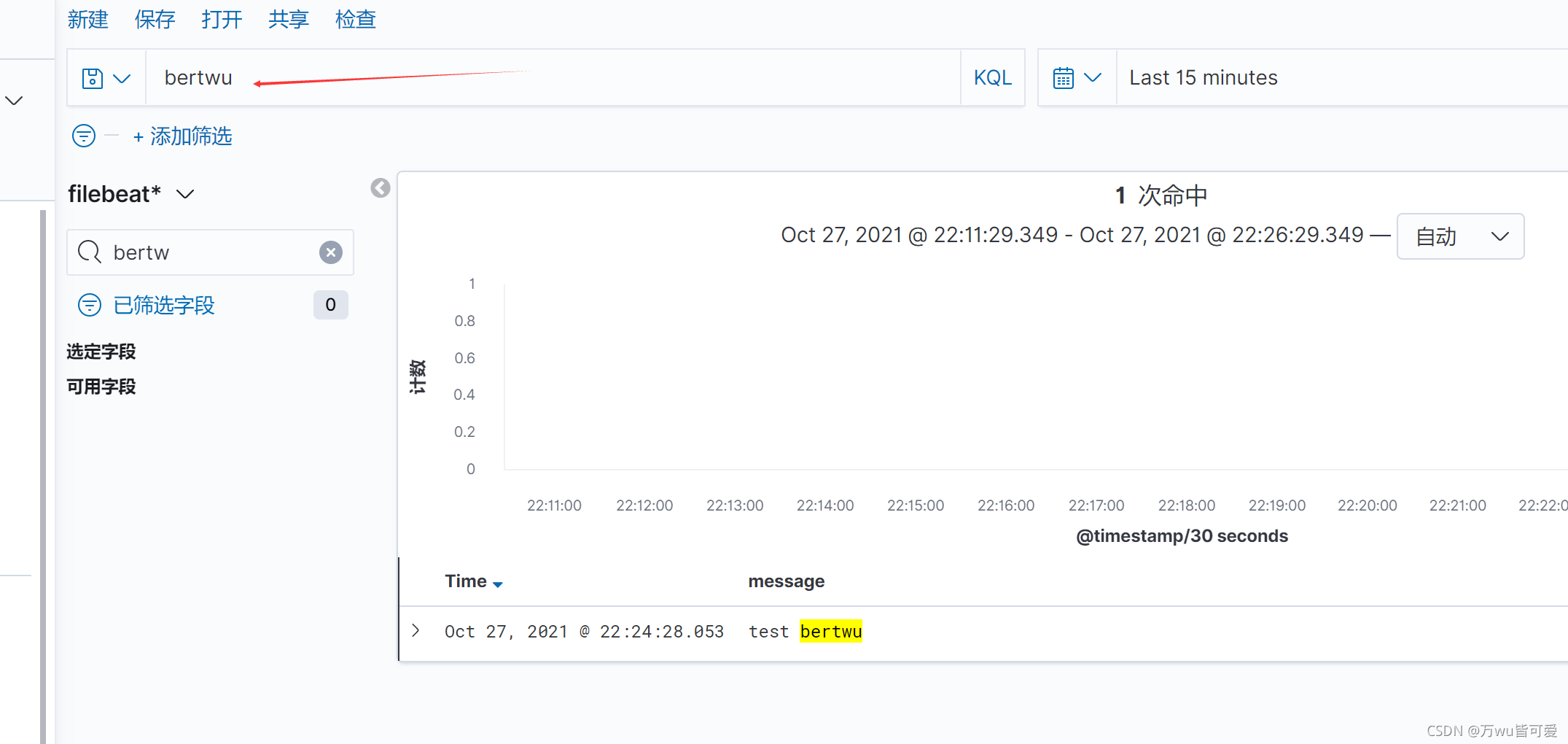
2.8 Filebeat 自定义索引名称
默认情况下,所有的索引名称文filebeat开头,难以区分,我们可以自定义索引名称
- 修改filebeat配置文件;
- 删除ES 的索引;删除Kibana的索引;
- 重启filebeat 服务重新产生新的索引;
filebeat.inputs:
- type: log
enabled: true
paths: /var/log/messages
output.elasticsearch:
hosts: ["172.16.1.161:9200","172.16.1.162:9200","172.16.1.163:9200"]
index: "message-%{[agent.version]}-%{+yyyy.MM.dd}" #自定义索引名称
setup.ilm.enabled: false # 索引生命周期,需要关闭自定义的索引名称才能生效
setup.template.name: "message" #定义模板名称
setup.template.pattern: "message-*" #定义模板的匹配索引名称
# 如果是 filebeat--elasticsearch--kibana 架构,可以这样设置分片,否则无效。
#setup.template.settings:
# index.number_of_shards: 3
# index.number_of_replicas: 0
创建在kibana中message索引即可检索到。
默认情况下 Filebeat 写入到 ES 的索引分片为1,如果需要修订分片,可以通过如下两种方式:
方式一:修改filebeat配置文件,增加如下内容;然后删除索引的模板,以及索引,重新产生数据;
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 1
方式二:使用 cerebro web页面修改;
1.修改模板 settings 配置,调整分片以及副本;
2.删除模板关联的索引;
3.重启filebeat产生新的索引;
二、Filebeat收集系统日志
2.1.系统日志有哪些
系统日志其实很宽泛、通常我们说的是 messages、secure、cron、dmesg、ssh、boot 等日志。
2.2 系统日志收集思路
系统中有很多日志,挨个配置收集就变得非常麻烦了。所以我们需要对这些日志进行统一、集中的管理。可以通过 rsyslog 将本地所有类型的日志都写入/var/log/system.log 文件中,然后使用 filebeat 对该文件进行收集即可。
rsyslog+filebeat --> elasticsearch集群 <–kibana

2.3 环境准备
| 主机名称 | 服务 | IP地址 |
|---|---|---|
| web01 | rsyslog+filebeat | 172.16.1.7 |
| es-node1 | es | 172.16.1.161 |
| es-node2 | es | 172.16.1.162 |
| es-node3 | es | 172.16.1.163 |
2.4 rsyslog安装及配置
[root@web01 ~]# yum install rsyslog -y
[root@web01 ~]# vim /etc/rsyslog.conf
#配置收集日志的方式
#*.* @IP:514 #将本地所有日志通过网络发送给远程服务器
*.* /var/log/oldxu.log #将本地所有日志保存至本地/var/log/system.log
# 启动
systemctl start rsyslog
2.5 配置filebeat
[root@web01 ~]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths: /var/log/sys.log
output.elasticsearch:
hosts: ["172.16.1.161:9200","172.16.1.162:9200","172.16.1.163:9200"]
index: "system-%{[agent.version]}-%{+yyyy.MM.dd}" #自定义索引名称
setup.ilm.enabled: false
setup.template.name: "system" #定义模板名称
setup.template.pattern: "system-*" #定义模板的匹配索引名称
2.6 kibana创建system索引并查看

2.7 优化
kibana 展示的结果上有很多 Debug 消息,其实该类消息无需收集,所以我们可以对收集的日志内容进行优化,只收集警告 WARN、ERR、sshd 相关的日志;
[root@web01 ~]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths: /var/log/sys.log
include_lines: ["WARN","ERR","sshd"] #包含这些
# exclude_lines: ["DEBUG","INFO"] # 或者排除这些
output.elasticsearch:
hosts: ["172.16.1.161:9200","172.16.1.162:9200","172.16.1.163:9200"]
index: "system-%{[agent.version]}-%{+yyyy.MM.dd}" #自定义索引名称
setup.ilm.enabled: false
setup.template.name: "system" #定义模板名称
setup.template.pattern: "system-*" #定义模板的匹配索引名称
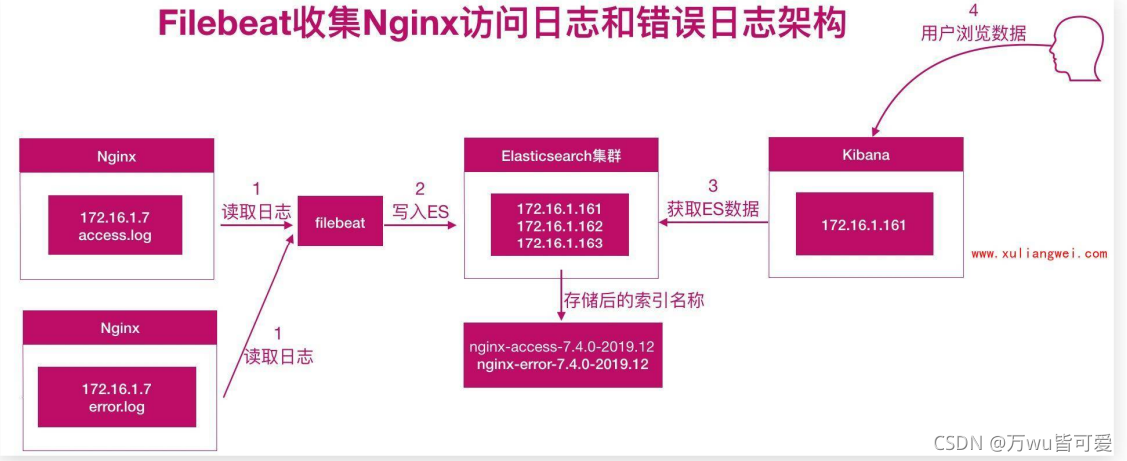
三、Filebeat收集Nginx日志
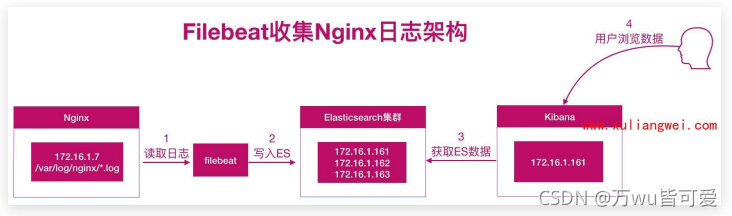
我们需要获取用户的信息,比如:来源的IP是哪个地域,网站的PV、UV、状态码、访问时间等等;所以需要收集 Nginx 日志;
3.1 Nginx日志收集架构图
nginx+filebeat --> elasticsearch <–kibana
3.2 安装nginx并配置默认访问站点
[root@web01 filebeat]# cat /etc/nginx/conf.d/elk.conf
server {
listen 5555;
server_name elk.bertwu.net;
location / {
root /code;
index index.html;
}
}
3.3 配置filebeat
[root@web01 filebeat]# cat filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths: /var/log/nginx/access.log
output.elasticsearch:
hosts: ["172.16.1.161:9200","172.16.1.162:9200","172.16.1.163:9200"]
index: "nginx-access-%{[agent.version]}-%{+yyyy.MM.dd}" #自定义索引名称
setup.ilm.enabled: false
setup.template.name: "nginx" #定义模板名称
setup.template.pattern: "nginx-*" #定义模板的匹配索引名称
3.4 kibana创建索引并展示
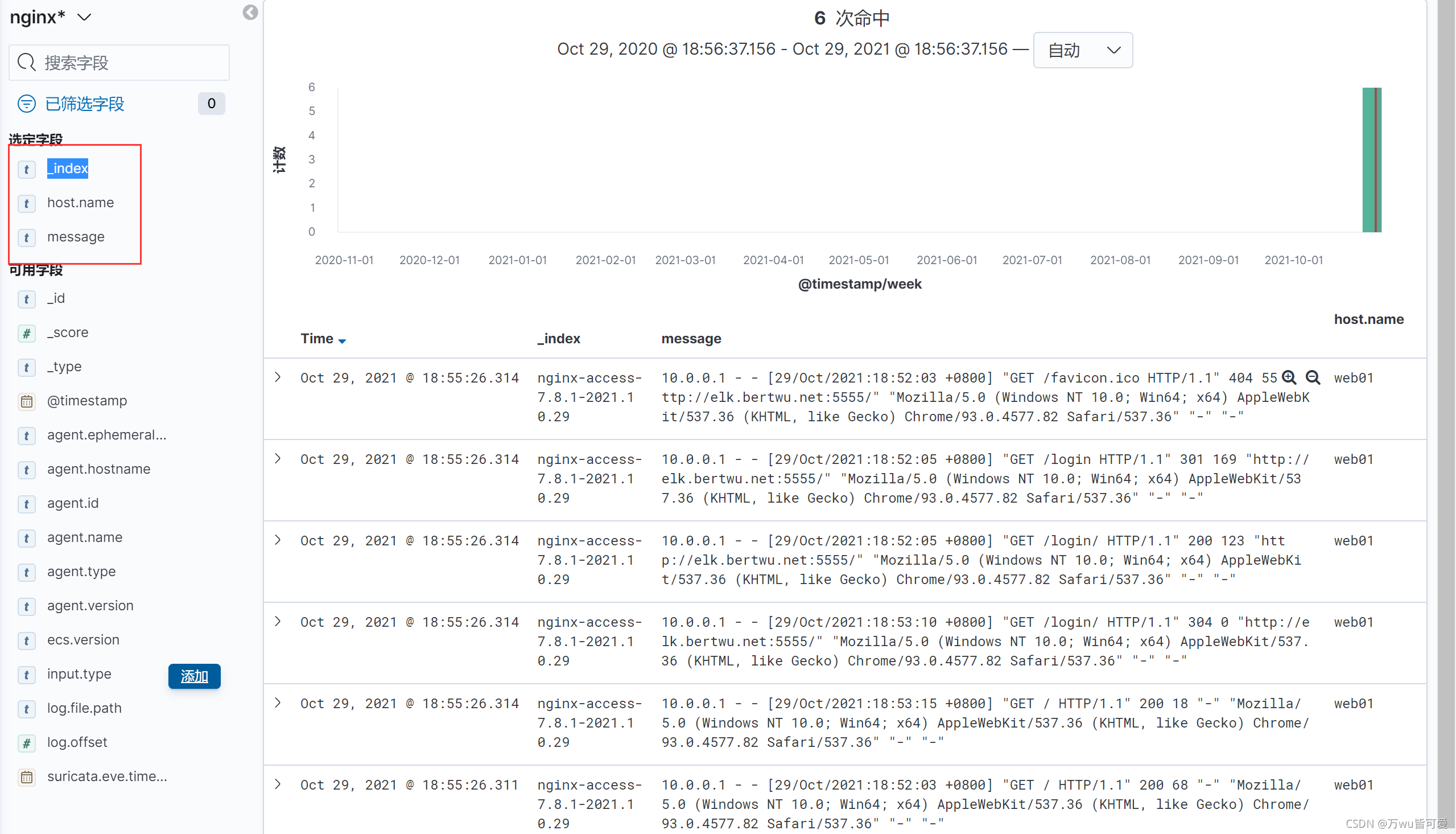
3.5 Nginx json日志收集
3.5.1 原始收集问题
我们实现了 Nginx 日志的收集,但是所有的数据都在 message 字段中,无法满足分析的需求,比如:
需要统计状态码的情况;
统计所有请求总产生的流量大小;
统计来源使用的客户端;等等
这些是没有办法实现的
3.5.2 解决方案
需要将日志中的每一个选项都拆分出来,拆分成 key-value 的形式,那么就需要借助 json 的格式。
3.5.3 将nginx日志格式转换为json
1.重置nginx日主格式为json格式
log_format json '{ "time_local": "$time_local",'
'"remote_addr": "$remote_addr",'
'"referer": "$http_referer",'
'"request": "$request",'
'"status": $status,'
'"bytes": $body_bytes_sent,'
'"test_agent": "$http_user_agent",'
'"x_forwarded": "$http_x_forwarded_for",'
'"up_addr": "$upstream_addr",'
'"up_host": "$upstream_http_host",'
'"upstream_time": "$upstream_response_time",'
'"request_time": "$request_time"'
'}';
2.重新配置nginx.conf
[root@web01 filebeat]# cat /etc/nginx/conf.d/elk.conf
server {
listen 5555;
server_name elk.bertwu.net;
access_log /var/log/nginx/access.log json; # 定义日志格式为json
location / {
root /code;
index index.html;
}
}
3.重新配置filebeat文件
[root@web01 filebeat]# cat filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths: /var/log/nginx/access.log
json.keys_under_root: true # Flase会将json解析的格式存储至messages,改为true则不存储至
json.overwrite_keys: true #覆盖默认message字段,使用自定义json格式的key
output.elasticsearch:
hosts: ["172.16.1.161:9200","172.16.1.162:9200","172.16.1.163:9200"]
index: "nginx-access-%{[agent.version]}-%{+yyyy.MM.dd}" #自定义索引名称
setup.ilm.enabled: false
setup.template.name: "nginx" #定义模板名称
setup.template.pattern: "nginx-*" #定义模板的匹配索引名称
4.重启filebeat、Nginx,然后清空日志,在重新产生json格式的日志
[root@web01 nginx]# > /var/log/nginx/access.log
[root@web01 nginx]#
[root@web01 nginx]#
[root@web01 nginx]# systemctl restart nginx
[root@web01 nginx]# systemctl restart filebeat
5.查看
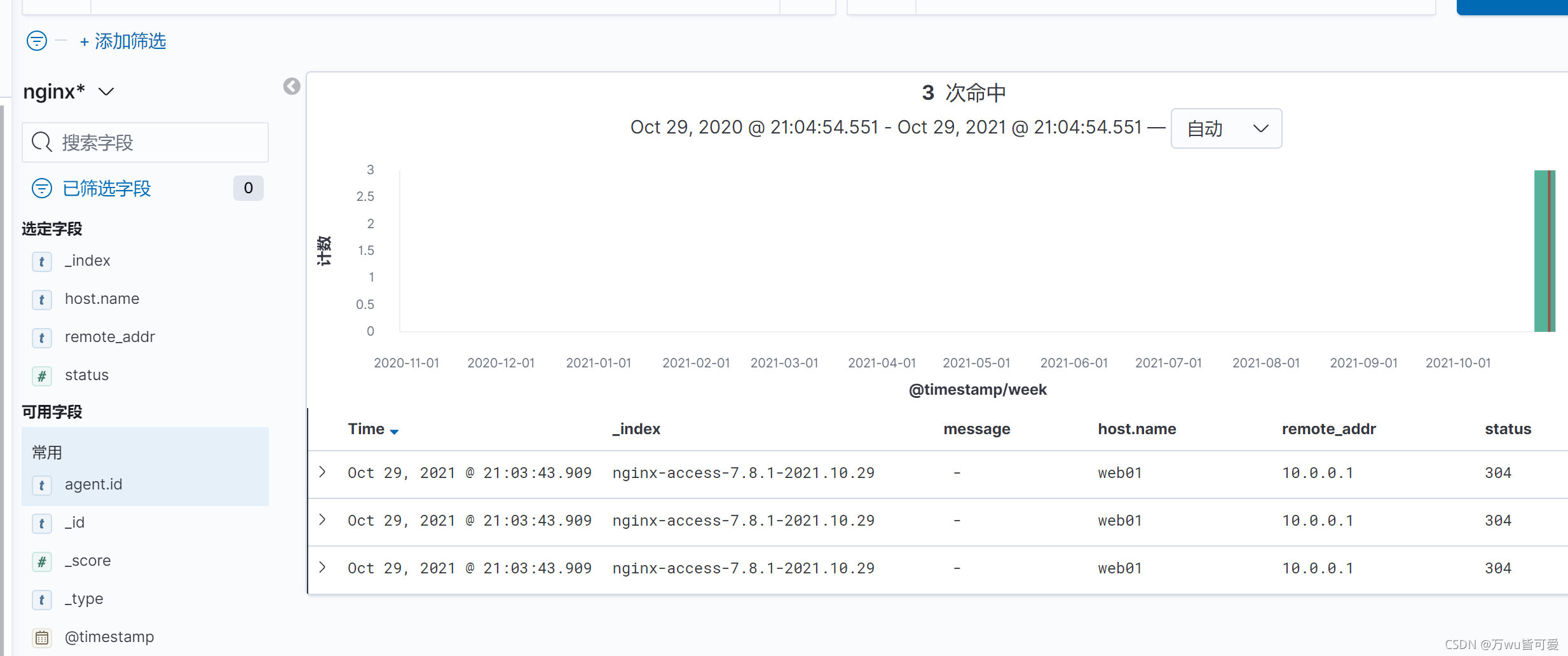
3.6 nginx多种日志类型收集
nginx 存在访问日志和错误日志,那么如何使用filebeat 同时收集 nginx 的访问日志、错误日志;
我们希望的状态如下:
nginx访问日志 --存储–> nginx-access-xxx 索引
nginx错误日志 --存储–> nginx-error-xxx 索引
1.配置 filebeat 收集多个日志,需要通过 tags 标签进行区分;
[root@web01 filebeat]# cat filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths: /var/log/nginx/access.log
json.keys_under_root: true
json.overwrite_keys: true
tags: ["access"]
- type: log
enabled: true
paths: /var/log/nginx/error.log
tags: ["error"]
output.elasticsearch:
hosts: ["172.16.1.161:9200","172.16.1.162:9200","172.16.1.163:9200"]
indices:
- index: "nginx-access-%{[agent.version]}-%{+yyyy.MM.dd}" #自定义索引名称
when.contains:
tags: "access"
- index: "nginx-error-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
tags: "error"
setup.ilm.enabled: false
setup.template.name: "nginx" #定义模板名称
setup.template.pattern: "nginx-*" #定义模板的匹配索引名称
2.kibana中创建nginx-err索引并查看
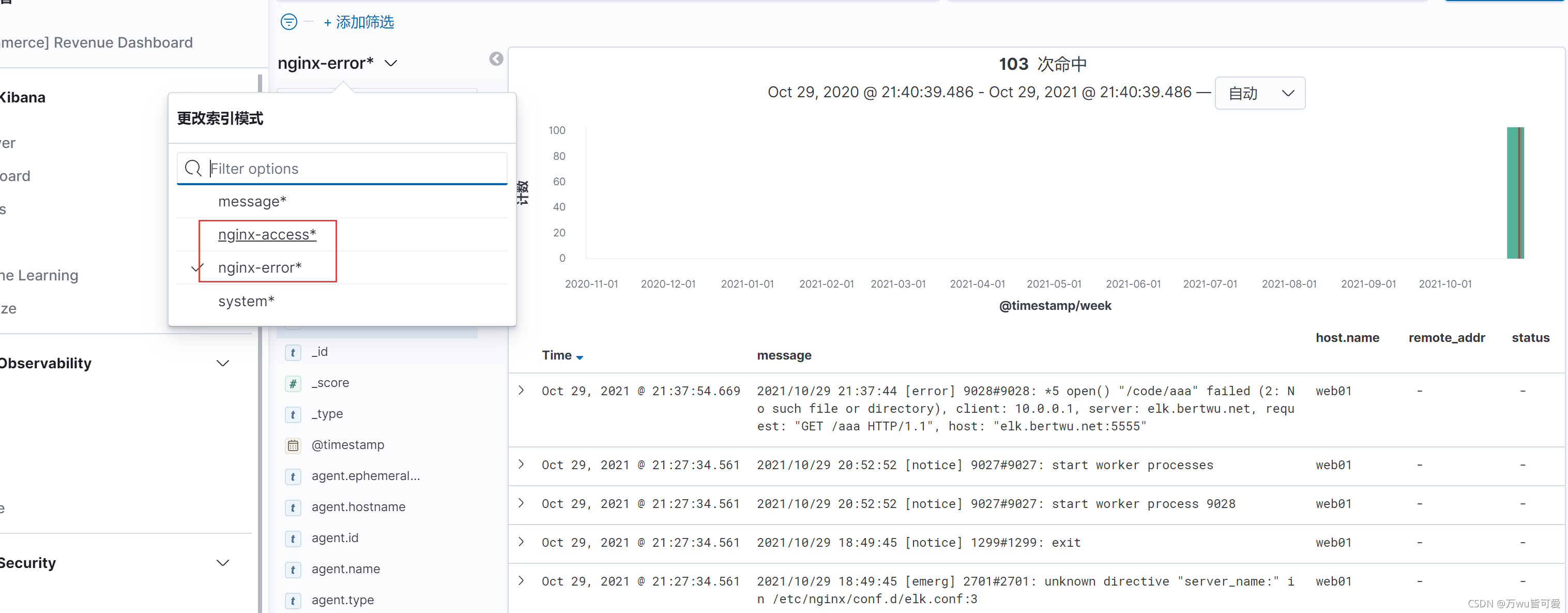
3.7 Nginx多虚拟主机收集
Nginx 如果有多个站点;filebeat 该如何收集多个域名的访问日志
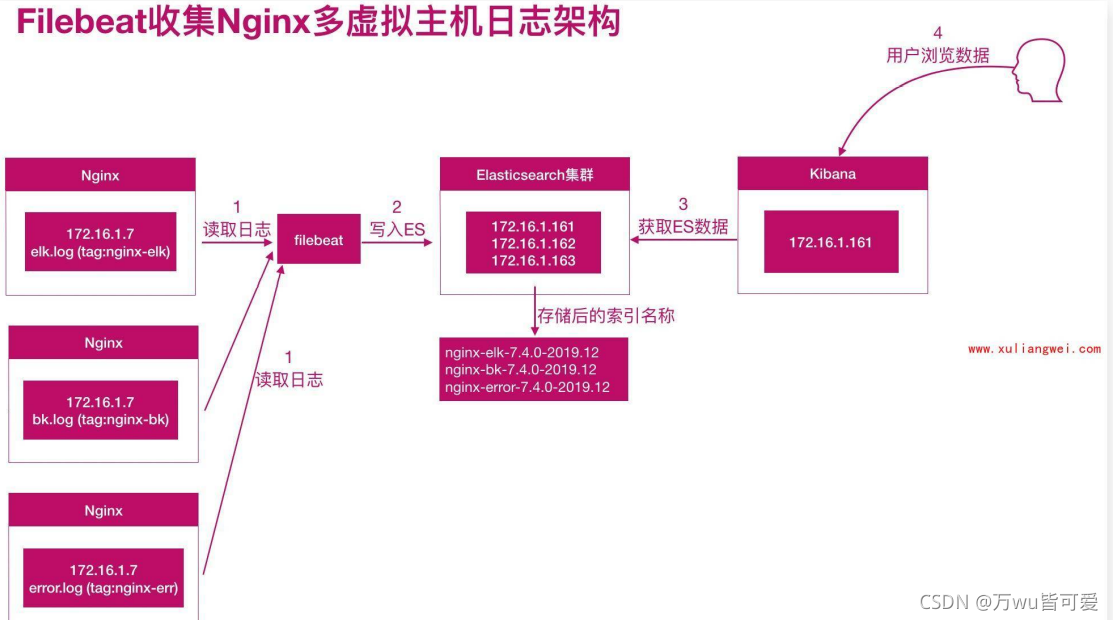
基于原有的基础上改进
1.配置nginx多站点
[root@web01 ~]# cat /etc/nginx/conf.d/elk.conf
server {
listen 5555;
server_name elk.bertwu.net;
access_log /var/log/nginx/access.log json;
location / {
root /code;
index index.html;
}
}
server {
listen 5555;
server_name blog.bertwu.net;
access_log /var/log/nginx/blog.log json;
location / {
root /code;
index index.html;
}
}
server {
listen 5555;
server_name www.bertwu.net;
access_log /var/log/nginx/www.log json;
location / {
root /code;
index index.html;
}
}
2.配置filebeat
[root@web01 filebeat]# cat filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths: /var/log/nginx/access.log
json.keys_under_root: true
json.overwrite_keys: true
tags: ["access"]
- type: log
enabled: true
paths: /var/log/nginx/error.log
tags: ["error"]
- type: log
enabled: true
paths: /var/log/nginx/www.log
json.keys_under_root: true
json.overwrite_keys: true
tags: ["nginx-www"]
- type: log
enabled: true
paths: /var/log/nginx/blog.log
json.keys_under_root: true
json.overwrite_keys: true
tags: ["nginx-blog"]
output.elasticsearch:
hosts: ["172.16.1.161:9200","172.16.1.162:9200","172.16.1.163:9200"]
indices:
- index: "nginx-access-%{[agent.version]}-%{+yyyy.MM.dd}" #自定义索引名称
when.contains:
tags: "access"
- index: "nginx-error-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
tags: "error"
- index: "nginx-www-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
tags: "nginx-www"
- index: "nginx-blog-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
tags: "nginx-blog"
setup.ilm.enabled: false
setup.template.name: "nginx" #定义模板名称
setup.template.pattern: "nginx-*" #定义模板的匹配索引名称
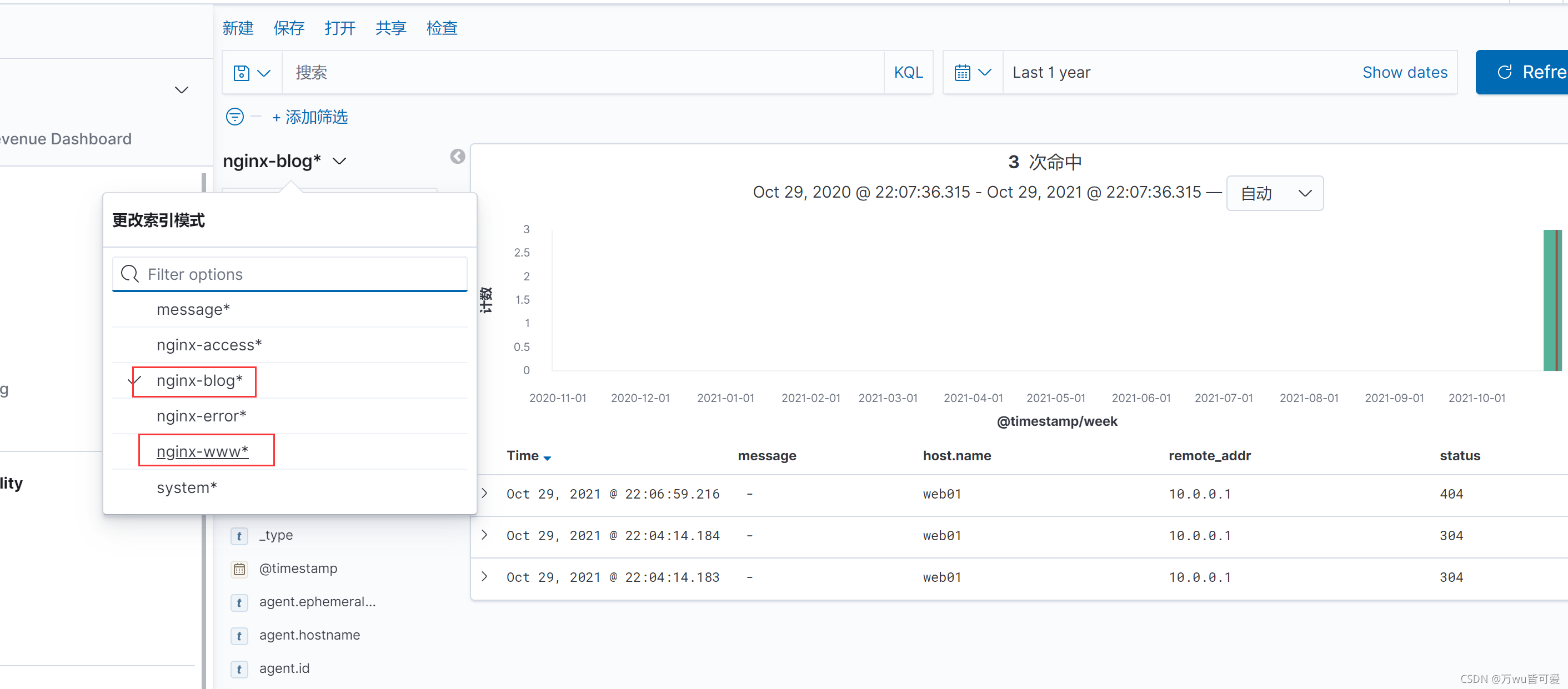
3.kibana查看
四、Filebeat收集Tomcat日志
我们只需要安装好tomcat,然后将 tomcat 修改为 json 格式日志,在使用 filebeat 进行收集即可;
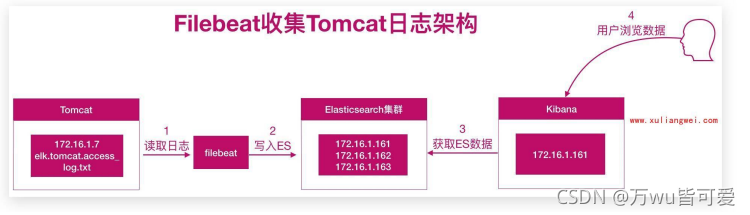
4.1 Tomcat日志收集架构图
tomcat+filebeat --> elasticsearch <–kibana
4.2 Tomcat访问日志收集
1.安装tomcat并设置访问站点
[root@web01 ~]# mkdir -p /soft/ && cd /soft
[root@web01 soft]# wget http://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat-9/v9.0.26/bin/apache-tomcat9.0.26.tar.gz
[root@web01 soft]# tar xf apache-tomcat-9.0.26.tar.gz
[root@web01 soft]# ln -s /soft/apache-tomcat-9.0.26 /soft/tomcat
2.修改tomcat server.xml文件,修改日志格式
<Host name="elk.bertwu.net" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="json_elk_log" suffix=".txt"
pattern="
{
"clientip":"%h","
ClientUser":"%l","
authenticated":"%u","
AccessTime":"%t","
method":"%r","
status":"%s","
SendBytes":"%b","
Query?string":"%q","
partner":"%{
Referer}i","
AgentVersion":"%{
User-Agent}i"}" />
</Host>
3.重启tomcat
[root@web01 tomcat]# /soft/tomcat/bin/startup.sh
4.检查访问日志是否为json格式
[root@web01 tomcat]# cat /soft/tomcat/logs/json_elk_log.2021-10-30.txt
{
"clientip":"10.0.0.1"," ClientUser":"-"," authenticated":"-"," AccessTime":"[30/Oct/2021:11:08:45 +0800]"," method":"GET / HTTP/1.1"," status":"200"," SendBytes":"200"," Query?string":""," partner":"-"," AgentVersion":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36"}
5.修改filebeat配置
[root@web01 filebeat]# cat filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths: /soft/tomcat/logs/json_elk_log*.txt
json.keys_under_root: true
json.overwrite_keys: true
tags: ["access"]
output.elasticsearch:
hosts: ["172.16.1.161:9200","172.16.1.162:9200","172.16.1.163:9200"]
index: "tomcat-access-%{[agent.version]}-%{+yyyy.MM.dd}"
setup.ilm.enabled: false
setup.template.name: "tomcat" #定义模板名称
setup.template.pattern: "tomcat-*" #定义模板的匹配索引名称
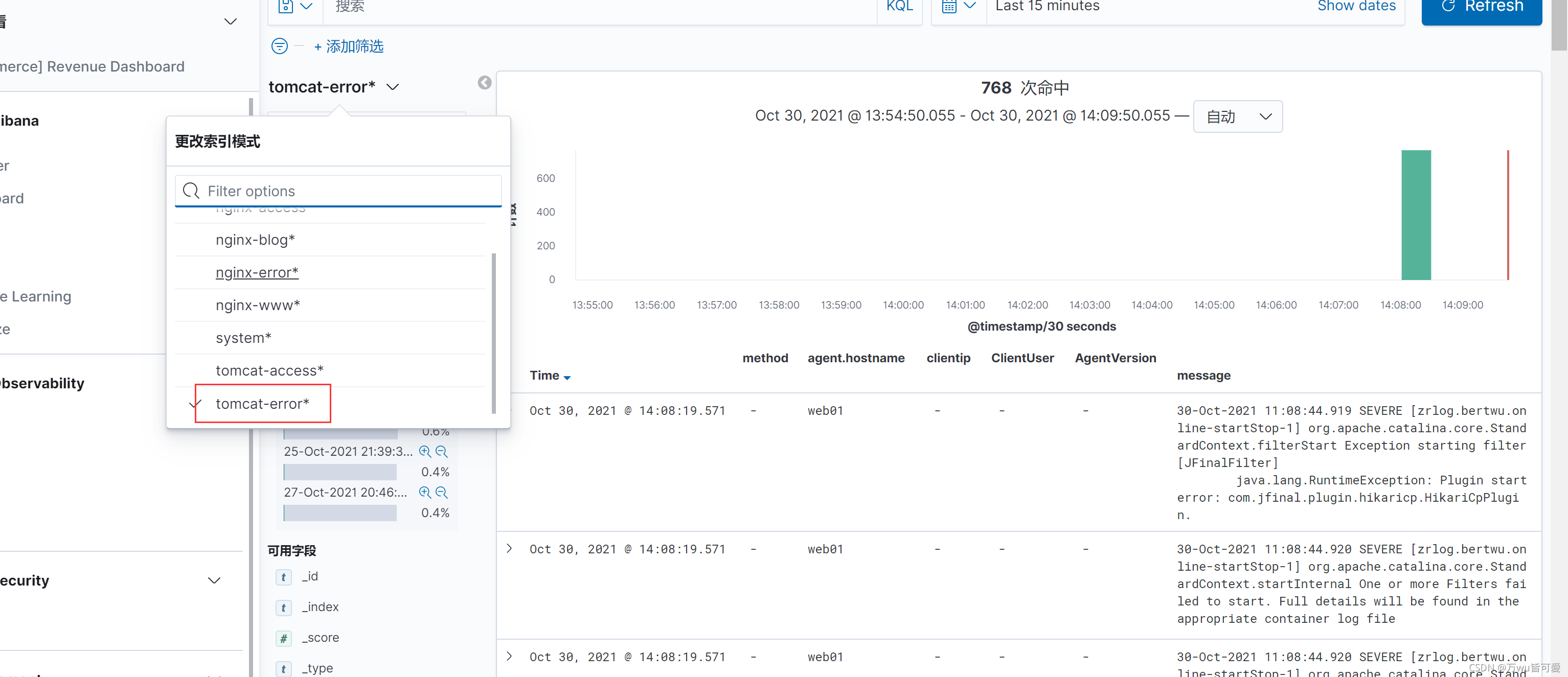
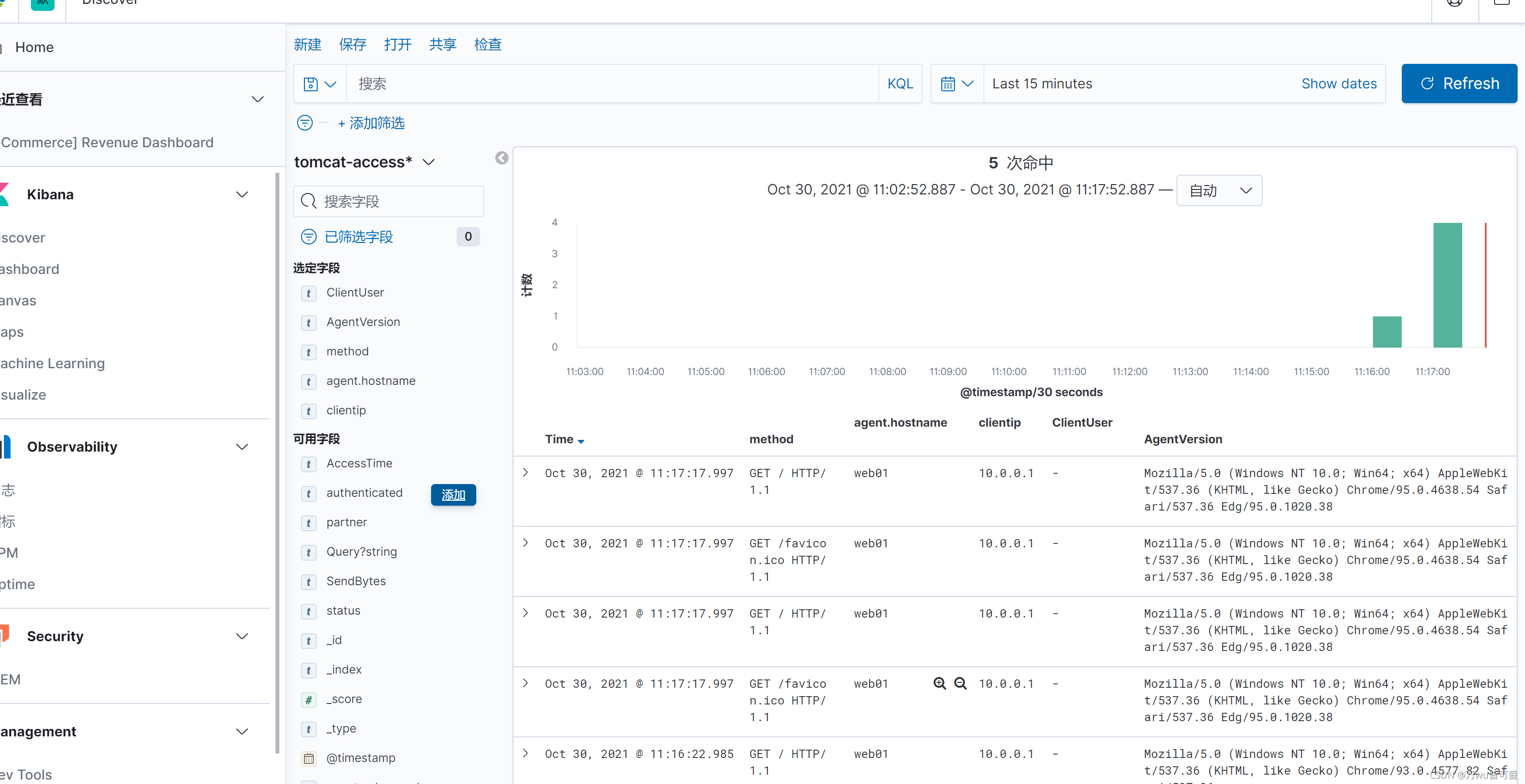
6.kibana中创建tomcat-access索并展示
4.3 Tomcat 错误日志收集
4.3.1 java错误日志特点
1.报错信息比较多。
2.报错信息分很多行。
4.3.2 收集思路
例1: Tomcat正常日志是以 “日期” 开头的。而报错日志中间的错误都不是以 “日期” 开头的。所以我们可以匹配以 “日期” 开头的一直到下一个日期出现则为一个事件日志。
例2: Elasticsearch正常日志是以 [] 开头的。而报错日志中间的错误信息不是以 [] 开头,所以可以匹配以 [开头的行,一直到下一个 [开头的出现则为一个事件日志。官方多行匹配方式
4.3.3 filebeat配置
[root@web01 filebeat]# cat filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths: /soft/tomcat/logs/json_elk_log*.txt
json.keys_under_root: true # 默认为False; 就是将所有的日志记录到Message字段;true不存储至Message字段
json.overwrite_keys: true # 会覆盖掉Message字段的内容,然后使用自行定义的Json格式的Key作为字段,来存储对应的值
tags: ["access"]
- type: log
enabled: true
paths: /soft/tomcat/logs/catalina.out
tags: ["error"]
multiline.pattern: '^\d{2}'
multiline.negate: true
multiline.match: after
multiline.max_lines: 1000 # 最大的合并行数 默认合并的数量是500
output.elasticsearch:
hosts: ["172.16.1.161:9200","172.16.1.162:9200","172.16.1.163:9200"]
indices:
- index: "tomcat-access-%{[agent.version]}-%{+yyyy.MM.dd}" #自定义索引名称
when.contains:
tags: "access"
- index: "tomcat-error-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
tags: "error"
setup.ilm.enabled: false
setup.template.name: "tomcat" #定义模板名称
setup.template.pattern: "tomcat-*" #定义模板的匹配索引名称