
【本文为个人原创解读,转载请注明出处,非常感谢】
本文由NVIDA出品,《T-AutoML: Automated Machine Learning for Lesion Segmentation using
Transformers in 3D Medical Imaging》
个人感觉实验或者复现的意义不大(成本很高),把握和体会最终结果并直接用于个人项目即可。
【当然了,本人眼界与水平有限,以下分析与评论均为个人看法,欢迎各位批评指正。】
**中心思想:**将3D医学影像分割中的所有部件(网络结构、损失函数、超参数、数据增强)编码成1-d向量,并通过Transformer结构训练预测器,以预测两个向量所代表的网络性能高低,进而搜索到最优的的网络组成。
一、搜索空间的确定:
首先明确本文中的搜索空间,由于是对整个网络组件的搜索和优化,因此网络的搜索空间中包括**网络结构(卷积层的类型、数量、空间尺度、连接方式)、数据增强方式、训练超参数、损失函数。**下文将对各个部分进行具体解释:
1、网络结构:
传统的医学影响分割领域被以Unet为代表的编码器-解码器(Encoder-Decoder)+ 跨层连接(Skip-connections)结构所统治,虽然效果极佳,但是没有实际理论证明该结构就是最优的,所以在网络结构的搜索上,本文没有严格采用Encoder-Decoder的结构。
网络结构部件由三种基本块Residual Block,Bottleneck Block,Axial-attention Block组成。
假设有 N N N个块依次排列,第 c i c_i ci个块( i > = 3 i>=3 i>=3)会接收之前两个块 c j c_j cj和 c k c_k ck的特征,并将其组合同时为保证特征图空间尺寸的统一,在不同层之间会进行必要的上采样与下采样。在第 N N N层后接softmax层作为输出。为减少GPU负担,在网络开始和结束都会使用卷积降低、恢复网络输入分辨率。
【简单来说就是从第三个块开始,每个块都随机和之前的两个块相连。第二个块仅和第一个块相连,并且 i , j , k i,j,k i,j,k并不一定相邻。】
其中 N N N取值为5到12,空间尺度(可简单理解为下采样次数) l l l取值范围为2到5,对于每个空间尺度特征图大小变为 1 / 2 ( l − 1 ) 1/2^{(l-1)} 1/2(l−1),通道数为 2 ( l − 1 ) ∗ c 1 2^{(l-1)*c_1} 2(l−1)∗c1。其中 c 1 c_1 c1设置为16。
【其实就和平常使用的时候一样,每次下采样特征图减小一倍,通道数就翻倍】
2、数据增强(保证准确,不做翻译):
每种数据增强的概率为0.15
- Random Flipping (along X , Y, Z axes respectively)
- Random Rotation (90 degrees) in X -Y planes
- Random Zooming,
- Random Gaussian Noise
- Random Intensity Shift
- Random Intensity Scale Shift
3、学习率:
[ 0.01 , 0.005 , 0.001 , 0.0005 , 0.0001 ] [0.01, 0.005, 0.001, 0.0005, 0.0001] [0.01,0.005,0.001,0.0005,0.0001]
4、损失函数:
- Dice loss with or without squared prediction
- Cross entropy loss
- Cross entropy loss + Dice loss
- Dice loss + Focal loss
二、网络配置编码
确定了搜索空间之后,就是将网络的这些候选配置进行编码,本文将所有的网络配置编码为一个一维向量 V V V,而 V V V中包括网络结构编码 A A A,数据增强编码 f f f,超参数编码 h h h。
1、网络结构编码
网络结构将被编码为一个动态长度的一维向量 A A A,对于每个块,可以使用5个整数进行表示,前三个数代表当前块的ID,块的类型,空间尺度,另外两个数表示与当前块相连的另外两个块的ID。其中第一个块(-1,-1),第二个块(0,-1)。
2、其他编码
本文按顺序应用 n = 5 n=5 n=5种增强方式,对于 m m m个增强候选,有n个占位符,使用索引( 0 到 m − 1 0到m-1 0到m−1)表示增强方式的选择,因此数据增强编码 f f f长度为 n n n
对于其他的超参数,文章也都将其编码为连续或离散值,最后将所有的编码组合连接为一个大的一维向量。
三、Transformer预测器

本文的核心与亮点之一,其实原理非常朴素和简单,如下图,输入为上文提到的两条网络配置编码,输出为这两条配置编码所对应的网络配置在验证集上的性能高低,假设在验证集上的精度分别为 a i a_i ai, a j a_j aj,则网络训练时的GT为
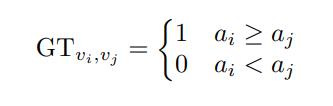
【在训练和测试的过程中,不同网络配置在验证集上得具体准确率并不重要,尤其是当图像数据不同的时候,所以该网络仅预测不同网络配置准确率之间的高低关系,这样也简化了网络训练的难度。】
四、训练过程
本文在LiTS-2017以及MSD数据集上进行实验。首先在搜索空间中随机选取100种网络配置,其中75种作为训练,25作为验证,然后对于每种网络配置训练迭代10000,则实际的训练数据量为75×75=5625【每两条向量作为一对进行输入】
五、实验结果
首先可以看一下搜索出来后最优的网络结构,如下图最右侧所示:

【实话实话,从结果来看这个网络结构比较”独特“,是否能够用在实际的工作中仍旧存疑】
其他的搜索结果:

这一部分可能对于各位同学实际工作的意义更大,具有一定的参考意义,实际使用的时候可以直接作为初始的设定,进行快速的模型训练。
实际的网络训练结果如下表所示:


不出意外的SOTA的结果,但是实际看上去和nnU-net的结果极为接近,文章在后面也做了和nn-Unet的对比,感兴趣的同学可以去看一下。