文章目录
Background
应用于验证各种智能故障诊断方法有效性的数据集满足以下两个条件:1)有带有故障信息的标记数据;2)训练和测试数据来自相同的概率分布。但是,对于某些机器,由于存在以下问题,很难满足这两种条件。
1)标记的故障数据很难从某些机器中获得。具体来说,导致缺乏标记的故障数据主要有两个原因。首先,机器可能不允许运行到故障,因为意外故障通常会导致机器故障,甚至灾难性事故。在这种情况下,不可能获得故障数据。其次,机器通常会经历一个从健康状态到故障的长期退化过程。这意味着获取机器的故障数据非常耗时且昂贵。
2)用从一台机器获得的标记数据训练的智能故障诊断方法可能无法对从另一台机器获得的未标记数据进行分类。虽然有些机器很难获得大量的标记数据,但它们仍然可以从不同但相关的机器中获得。
迁移学习的目的在于从源域到目标域的应用,其数据概率分布应该是不同但相似的,但两者涉及的类别是相同的。(说人话就是:训练集中有几个类别,测试集里面的类别只有少没有多)未知故障的区别在于其测试集中包含一类新故障。
主要贡献:
1)新方法:深度卷积迁移学习网络(DCTLN)具体后面介绍
2)探讨了对具有未标记数据的机器的智能故障诊断。一般来说,训练和测试数据集应该从一台机器上获得的智能故障诊断方法。在本文中,我们探索了一种新的智能故障诊断场景,其中训练和测试数据集从不同的机器获取,从监测机器的数据未标记。该探索将促进智能故障诊断的实际应用。
Transfer Learning Problem
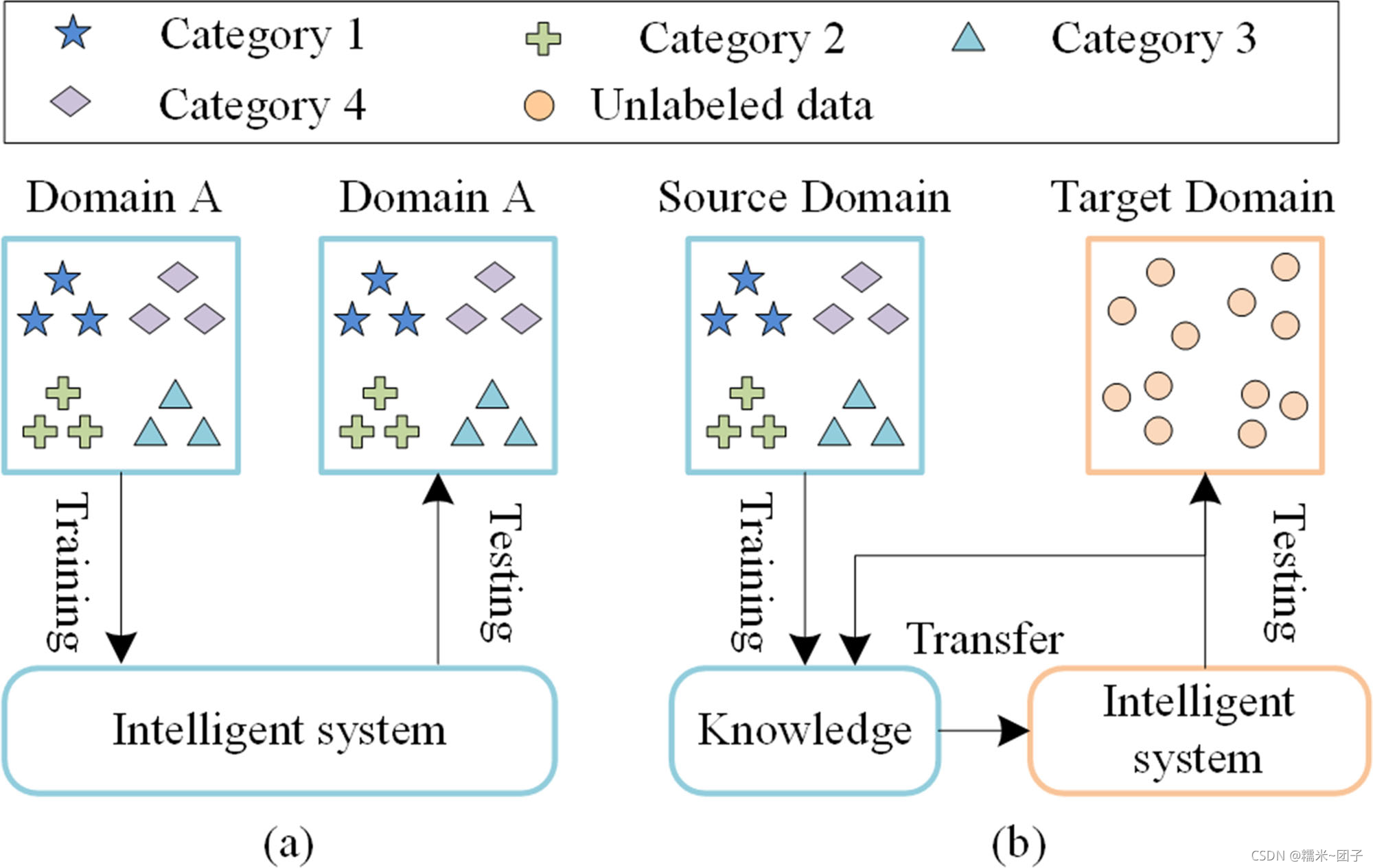
关键点在于:学习域不变特征
Proposed method
DCTLN
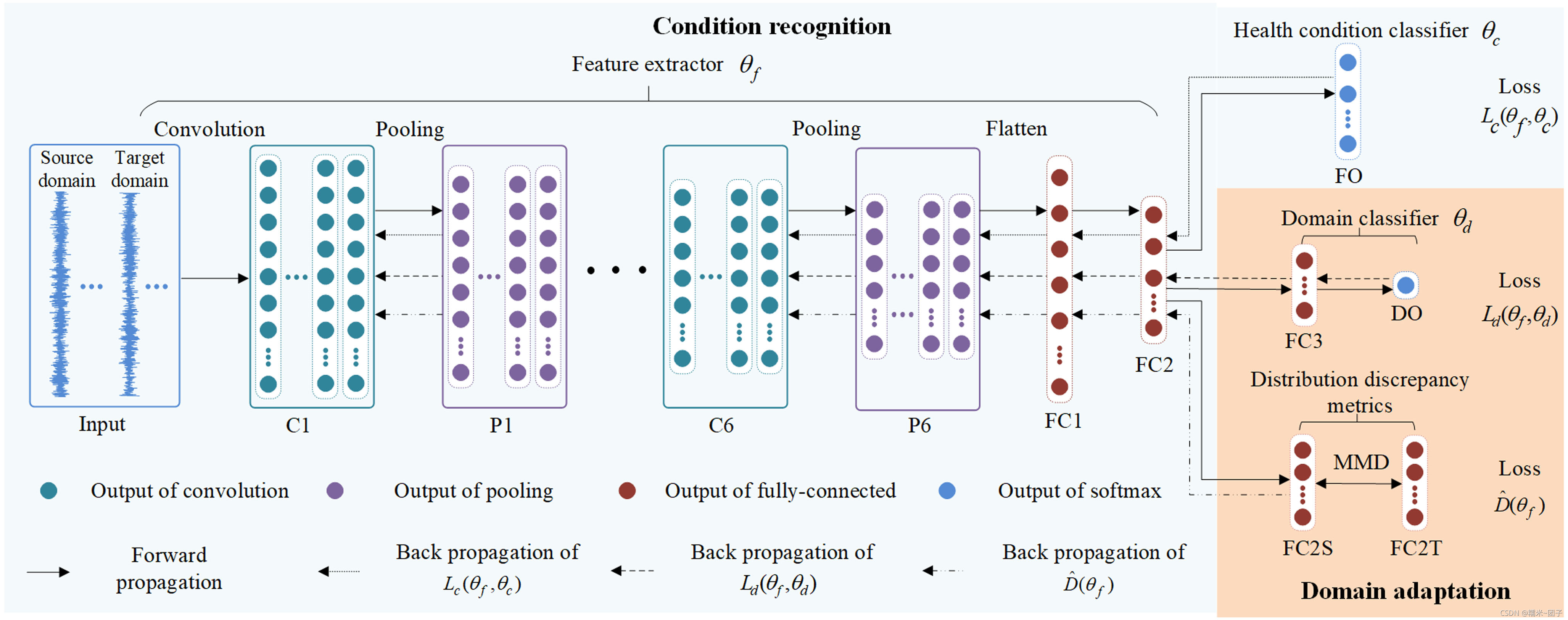
两部分:条件识别和域自适应
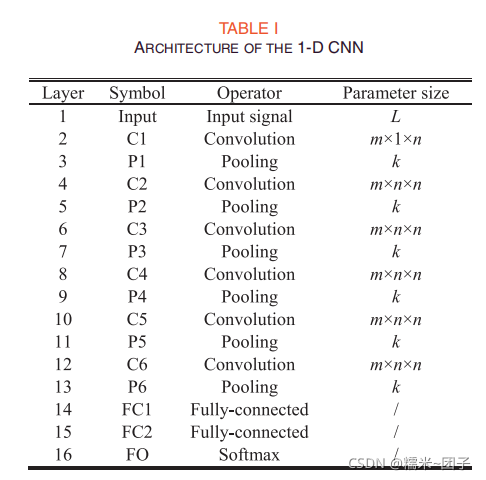
条件识别:普通卷积神经网络,第一次注意到池化层的平移不变性
域自适应:包括一个域分类器和一个域分布差异度量
域分类器:FC+DO
DO:logistic 回归的二进制分类器
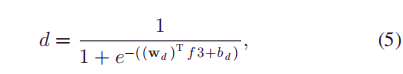
域分布差异度量:
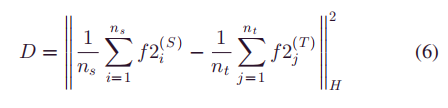
n s n_s ns n t n_t nt分别是训练集中源域和目标域的样本个数, ∣ ∣ . ∣ ∣ H 2 ||.||_H^2 ∣∣.∣∣H2表示一个可复制的核Hilbert空间, f 2 i ( S ) f2_i^{(S)} f2i(S) f 2 i ( T ) f2_i^{(T)} f2i(T)分别表示F2层输出的源域和目标域的对应的特征。
Optimization
1)源域数据分类误差最小化
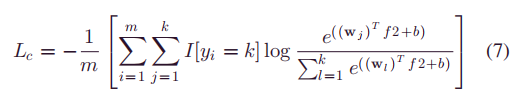
2)源域和目标域间分类器误差最大化(就是公式5)
解释一下:域分类器无法区分源域和目标域数据的时候说明提取到的特征是域不变的
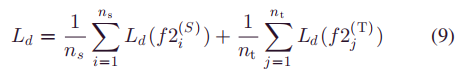
3)MMD最小化
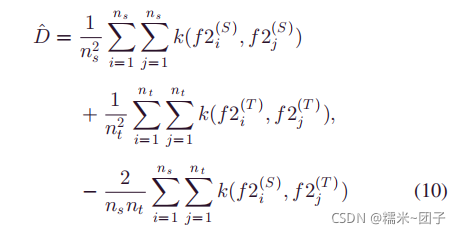
k ( x , y ) k(x,y) k(x,y)表示核函数,这里用一个高斯径向基函数(RBF) k ( x , y ) = e x p ( ∣ ∣ x − y ∣ ∣ 2 / 2 σ 2 ) k(x,y)=exp(||x-y||^2/2\sigma^2) k(x,y)=exp(∣∣x−y∣∣2/2σ2)
综合优化函数:
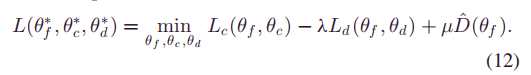
随机梯度下降优化参数:
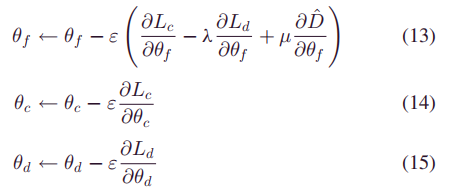
ε \varepsilon ε是学习率
测试集这里只包含无标签的目标域样本,通过条件识别来判断类型
Experiment
Dataset
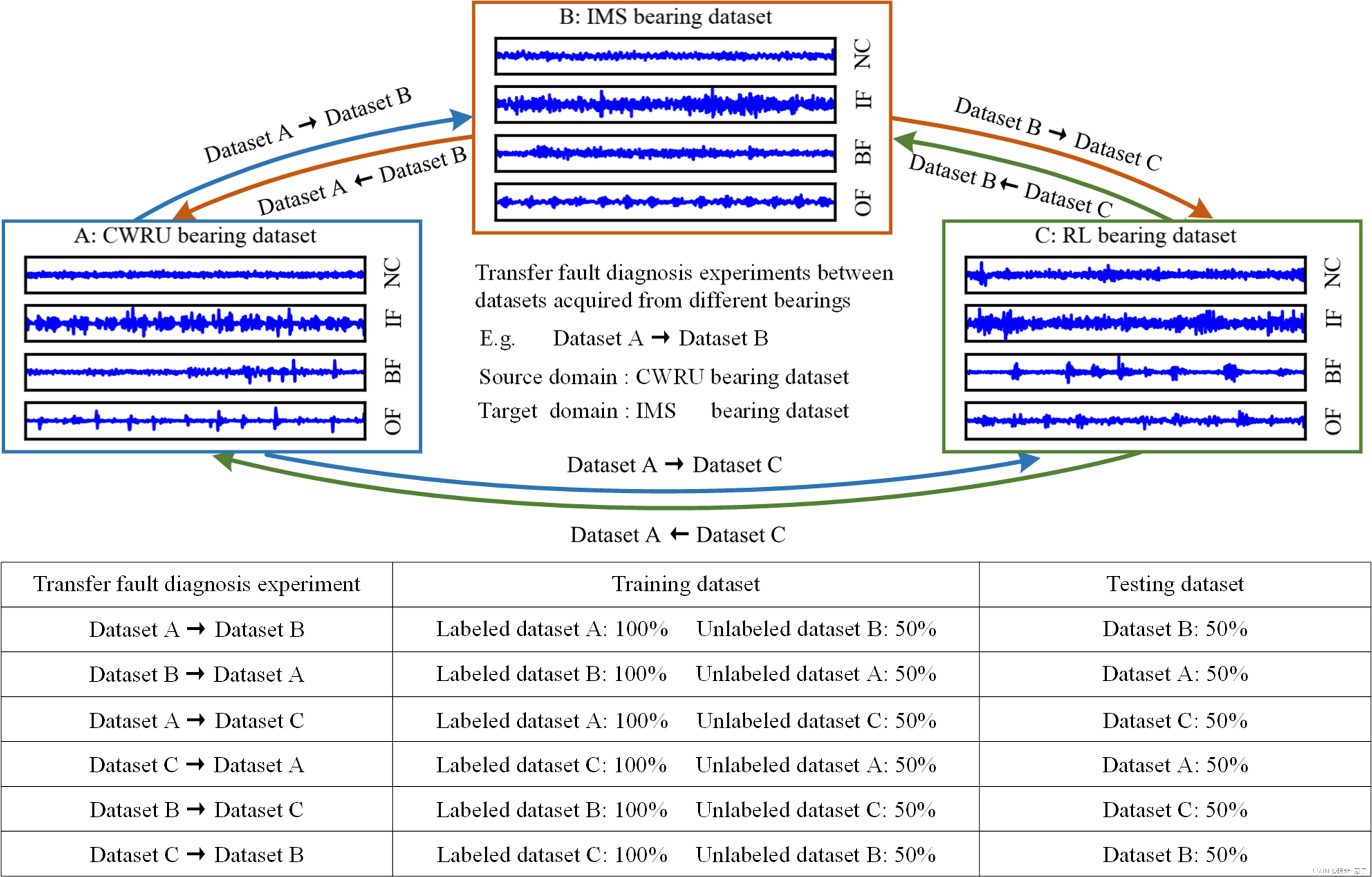
三种轴承数据,每个都包含:正常(NC)、内圈故障(IF)、外圈故障(OF)和滚珠故障(BF)
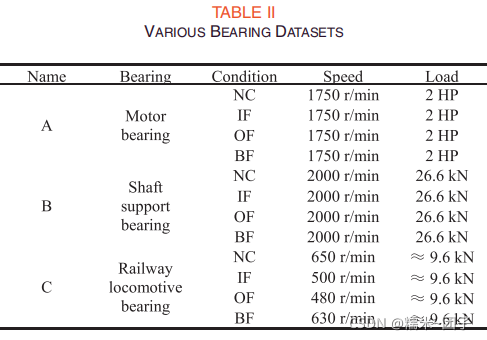
Experiment on DCTLN
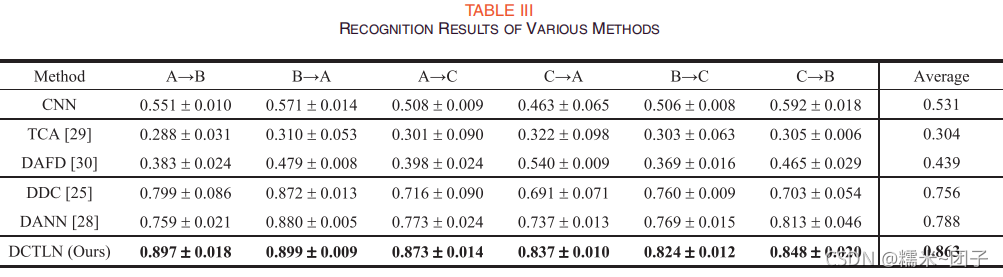
三种轴承数据六组迁移实验
论文