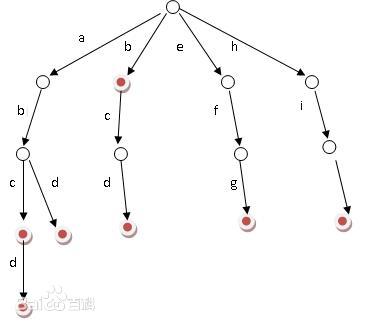
字典树的结构是多叉树,每个节点有n个出度,每个出度表示一个字符。字典树的节点分为普通节点和终止节点,如图,红色的节点即为终止节点,往字典树中插入一个单词,这个单词的最后一个字符就是终止节点。如图,字典树中包含的单词有:"abcd","abd","b","bcd","efg","hi "。
在输入框自动联想、单词出现频率统计的场景上都应用到了字典树。在有巨量相同前缀的单词中,字典树的效率高于哈希表,时间复杂度固定为O(len(str)),但是字典树的构建会消耗大量空间。字典树的特点就是尽量避免相同前缀的单词重复查找。
字典树的实现:构建、插入、查找。
public class TireTree {
// 字典树根节点
private TireNode root = new TireNode();
// 把一个单词插入字典树
public void insert(String word) {
if (word == null || word.length() == 0) return;
TireNode cur = root;
char[] chars = word.toCharArray();
for (char c : chars) {
TireNode target = cur.son.get(c);
// 如果子节点中找不到目标字符,则添加目标子节点
if (target == null) {
target = new TireNode();
target.val = c;
target.end = true;
cur.son.put(c, target);
}
target.num++; // 节点使用数 +1
cur = target;
}
cur.end = true; // 最后的字符节点为终止节点
}
// 判断单词是否存在于字典树
public boolean isExist(String word) {
if (word == null || word.length() == 0) return false;
TireNode cur = root;
char[] chars = word.toCharArray();
for (char c : chars) {
TireNode target = cur.son.get(c);
if (target == null) return false;
cur = target;
}
return cur.end; // 单词最后的字符是终止节点
}
// 指定前缀在字典树中出现的次数
public int count(String word) {
if (word == null || word.length() == 0) return 0;
TireNode cur = root;
char[] chars = word.toCharArray();
for (char c : chars) {
TireNode target = cur.son.get(c);
if (target == null) {
return 0;
}
cur = target;
}
return cur.num; // 单词最后的字符被使用次数
}
// 字典树节点
private class TireNode {
Map<Character, TireNode> son; // 通过字符快速确定是否存在子节点
char val;
int num; // 记录有多少个字符串使用了该节点
boolean end; // 记录节点是否为终结点
TireNode(){
son = new HashMap<>();
val = ' ';
num = 0;
end = false;
}
}
}