- 基础课中
蒙德里安的梦想属于 棋盘式状态压缩dp,最短Hamilton路径属于 集合状态压缩dp
1064. 小国王(棋盘式/基于连通性)

- 这种棋盘放置类问题,在没有事先知道一些特定 性质 的情况下来做,都会想到 爆搜,本题的数据规模,也是向着 爆搜 去设置的,如果我们直接 爆搜,则 时间复杂度 为 O ( 2 n 2 ) O(2^{n^2}) O(2n2)是会超时的,因此会想到用 记忆化搜索 来进行优化
- 发现对于当前行,只与上一行有关,与上上行无关
- f [ i , s ] f[i,s] f[i,s]表示前i行已经做完了,最后一行的状态是s的总共的方案数
- 这里还有对放的棋子个数的限制,所以还要加一维表示当前已经放了多少个棋子, f [ i , j , s ] f[i,j,s] f[i,j,s]
状态表示-集合: f [ i , j , s ] f[i,j,s] f[i,j,s]表示所有只摆在前i行,已经摆了j个国王,并且第i行摆放的状态是s的所有方案的集合状态表示-属性:count(数量)状态计算(集合划分的过程):
1.去看最后一步不同来划分,可知第i-1行最多有 2 n 2^n 2n种摆放方式,也就是指数级
2.有两个需要满足的条件:1.第i-1行内部不能有两个1相邻;2.第i行和第i-1行的国王之间不能相互攻击到
3.用代码翻译就是,假设分别的二进制状态是a和b。那么,因为a和b不能同时是1,所以(a & b) == 0;(a | b)表示综合看两行的话哪些列是有国王的,那么(a | b)中不能有两个相邻的1就使得综合两行没有两个国王所在列相邻;满足以上两个条件就是满足2中的第二个性质;只要满足了性质,直接加上这一类中的元素数量,现在的状况是“已经摆完了前排,并且第i排的状态是a,第i-1排状态是b的所有方案,已经摆了j个国王“,去掉最后一排,“已经摆完第i-1排,并且第i-1排的状态是b,已经摆了j-count(a)个国王的所有方案“- 时间复杂度 :状态数量 * 状态计算的计算量,就是10 * 100 * S * Sh,最坏的情况下S有1000,每个状态又有1000次状态转移,所以10 * 100 * 1000 * 1000,即1^9,那么为什么可以做呢,我们可以通过预处理所有的 合法状态,以及合法的 相邻转移状态,以及 合法状态 摆放的国王数量,因为虽然状态很多,但是 合法状态 并不多, 合法的转移状态 更不多;状态压缩dp的特点 :用最暴力的方式算时间复杂度,都会超过时间上限
- 最后输出答案时还有一个偷懒小技巧,从 f [ n ] [ m ] . . . f[n][m]... f[n][m]...这种需要循环一次的换成 f [ n + 1 ] [ m ] [ 0 ] f[n+1][m][0] f[n+1][m][0]直接输出即可,对应的在前面状态转移的循环中多循环一次,然后就是N也要开成12
- 还有一个小技巧,这里head(由这个状态可以转移到哪些状态)里存的是state中的下标,而不是具体状态,状态表示中也是下标而不是具体二进制值
- 注意不要写成
(a & b == 0),是(a & b) == 0

#include <iostream>
#include <algorithm>
#include <cstring>
#include <queue>
#include <vector>
#define debug(a) cout << #a << " = " << a << endl;
//#define x first
//#define y second
#define LD long double
using namespace std;
typedef long long ll;
const int N = 12, M = 1 << N, K = 110;
int n, m;
vector<int> state;
vector<int> head[M];
int cnt[M];
ll f[N][K][M];
bool check(int state)
{
for (int i = 0; i < n; i ++ )
if ((state >> i & 1) && (state >> (i + 1) & 1)) return false;
return true;
}
int count(int state)
{
int cnt = 0;
for (int i = 0; i < n; i ++ )
cnt += (state >> i & 1);
return cnt;
}
int main()
{
cin >> n >> m;
for (int i = 0; i < (1 << n); i ++ )
if (check(i))
{
state.push_back(i);
cnt[i] = count(i);
}
for (int i = 0; i < state.size(); i ++ )
for (int j = 0; j < state.size(); j ++ )
{
int a = state[i], b = state[j];
if ((a & b) == 0 && check(a | b)) // 不要写成
head[i].push_back(j);
}
f[0][0][0] = 1;
for (int i = 1; i <= n + 1; i ++ )
for (int j = 0; j <= m; j ++ )
for (int a = 0; a < state.size(); a ++ )
for (int b : head[a])
{
int c = cnt[state[a]];
if (j >= c)
f[i][j][a] += f[i - 1][j - c][b];
}
cout << f[n + 1][m][0] << endl;
return 0;
}
327. 玉米田

- 上一题是井字型不能种,这题是十字型
- 同样,这里一行只与上一行有关,与上上行无关,所以只要用二进制表示上一行的摆放情况即可
状态表示-集合: f [ i , s ] f[i, s] f[i,s]表示 所有已经摆完前i行,且第i行的状态是s的所有摆放方案的 集合状态表示-属性:count状态计算:满足两个性质 :1.a,b的二进制表示中不包含两个连续的1;2.(a&b)==0- 时间复杂度 : n ∗ 2 n ∗ 2 n n*2^n*2^n n∗2n∗2n,即 12 ∗ 2 24 12*2^{24} 12∗224,但,所以过
- 这题还有一个特殊之处,有些田是不能种的,这个可以通过定义一个数组g[N],g[i]表示第i行能否种田的二进制表示,1表示不能种(我们要舍弃的是田不能种且同时state在这个田种了的情况(1),容易想到&的性质,所以将田不能种定义为1),然后在状态计算时
g[i] & state[a]如果不为0,说明有同时为1的一位,则这个状态不合法,continue,否则就一定合法 - 状态计算时不需要判断f[i-1][b]是否合法,因为如果不合法,在i-1的时候就已经被continue了
#include <iostream>
#include <algorithm>
#include <cstring>
#include <queue>
#include <vector>
#define debug(a) cout << #a << " = " << a << endl;
//#define x first
//#define y second
#define LD long double
using namespace std;
typedef long long ll;
const int N = 14, M = 1 << 12, mod = 1e8;
int n, m;
int g[N];
vector<int> state;
vector<int> head[M];
int f[N][M];
bool check(int state)
{
for (int i = 0; i < m; i ++ )
if ((state >> i & 1) && (state >> i + 1 & 1)) return false;
return true;
}
int main()
{
cin >> n >> m;
for (int i = 1; i <= n; i ++ )
for (int j = 0; j < m; j ++ )
{
int t;
cin >> t;
// g[i] += !t << j;
g[i] += !t * (1 << j);
}
for (int i = 0; i < 1 << m; i ++ ) // 注意m列,不是n列
if (check(i))
state.push_back(i);
for (int i = 0; i < state.size(); i ++ )
for (int j = 0; j < state.size(); j ++ )
if (!(state[i] & state[j]))
head[i].push_back(j);
f[0][0] = 1;
for (int i = 1; i <= n + 1; i ++ ) // 到n + 1
for (int j = 0; j < state.size(); j ++ )
if (!(g[i] & state[j]))
{
for (int k : head[j])
f[i][j] = (f[i][j] + f[i - 1][k]) % mod;
}
cout << f[n + 1][0] << endl;
return 0;
}
292. 炮兵阵地

- 与上一题区别 :1.射程变化了,从一格变成两格了;2.求的从方案数变成了最多摆放的数量。大同小异
- 本题不同于 小国王 和 玉米田,这两题中棋子的 攻击距离 只有1,因此在这两题里,我们只需压缩存储 当前层的状态 ,然后枚举 合法的上个阶段 的状态进行 转移 即可,但是本题的棋子攻击范围是 2,我们只压缩当前层一层状态后进行转移,是不能保证该次转移是 合法的,即不能排除第 i−2 层摆放的棋子可以攻击到第 i 层棋子的 不合法 情况,而解决该问题的手段就是:压缩存储两层的信息,然后枚举合法的第 i−2 层状态进行转移即可
- 考虑当前一行摆放的状态时,不仅和上一行有关,还与上上行有关,因此,只要在状态里再加一维即可
状态表示-集合: f [ i , j , k ] f[i,j,k] f[i,j,k]表示 所有已经摆放完前i行,且第i-1行摆放的状态是j,第i行摆放的状态是k的所有摆放方案的最大值状态表示-属性:max状态计算:
1.在分析f[i,j,k]划分子集时,已经确定第i-1行是j,第i行是k了
2.第i-1行是a,第i行是b,第i-2行是c
3.需要满足的条件是 :1.abc两两之间不会相互攻击到,也就是两两之间不能有同一列上都有炮,也就是a&b==0&&a&c==0&&b&c==0,即((a & b) | (a & c) | (b & c)) == 0;2.炮不能放山地上,即g[i-1]&a==0&&g[i]&b==0,即(g[i - 1] & a | g[i] & b) == 0- 时间复杂度 : n ∗ 2 m ∗ 2 m ∗ 2 m n*2^{m}*2^{m}*2^{m} n∗2m∗2m∗2m,即 100 ∗ 2 30 100*2^{30} 100∗230,是 1 0 11 10^{11} 1011,非常恐怖,但这里所有相邻两个1之间至少隔两个0,而前面只是至少隔1个0,有效状态数更少,合法的状态和合法的转移都很少
- 这题还有一个问题,空间限制比较小,所以要用滚动数组,先当成不滚动来写,然后把所有第一维与上1,就可以变成滚动数组了。
滚动数组就是i和i-1一定是一个奇数一个偶数,&上1后肯定是0和1交替的。关于滚动数组,这题中状态表示属性是max,所以不需要清空,像前面两题求方案数,每次都枚举完状态的每一维开始状态转移前都要进行清空(判断前) - 易错点,输入地图的时候用char读入,而不是int
- 注意到前面两题由于只与上一行有关,所以在有效状态的预处理后还有一个表示从这个状态可以合法状态转移到的状态的预处理,而这里由于与前两行都有关,就没有这个预处理了,而是在状态转移计算的时候判断是否合法
#include <iostream>
#include <algorithm>
#include <cstring>
#include <queue>
#include <vector>
#define debug(a) cout << #a << " = " << a << endl;
//#define x first
//#define y second
#define LD long double
using namespace std;
typedef long long ll;
const int N = 11, M = 1 << 10;
int n, m;
int g[110];
int f[2][M][M]; // 滚动数组
int cnt[M];
vector<int> state;
bool check(int state)
{
for (int i = 0; i < m; i ++ )
if ((state >> i & 1) && ((state >> i + 1 & 1) || (state >> i + 2 & 1)))
return false;
return true;
}
int count(int state)
{
int cnt = 0;
for (int i = 0; i < m; i ++ )
cnt += state >> i & 1;
return cnt;
}
int main()
{
cin >> n >> m;
for (int i = 1; i <= n; i ++ )
for (int j = 0; j < m; j ++ )
{
char c;
cin >> c;
g[i] += (c == 'H') * (1 << j);
}
for (int i = 0; i < (1 << m); i ++ )
if (check(i))
{
state.push_back(i);
cnt[i] = count(i);
}
for (int i = 1; i <= n + 2; i ++ ) // 特殊技巧
for (int j = 0; j < state.size(); j ++ )
for (int k = 0; k < state.size(); k ++ )
for (int u = 0; u < state.size(); u ++ )
{
int a = state[j], b = state[k], c = state[u];
if (g[i - 1] & a | g[i] & b) continue;
if (a & b | a & c | b & c) continue;
f[i & 1][j][k] = max(f[i & 1][j][k], f[i - 1 & 1][u][j] + cnt[b]); // 注意最后加上的是cnt[b]而不是cnt[k]
}
// 不使用特殊技巧的情况
// int res = 0;
// for (int i = 0; i < state.size(); i ++ )
// for (int j = 0; j < state.size(); j ++ )
// res = max(res, f[n & 1][i][j]);
cout << f[n + 2 & 1][0][0] << endl; // 特殊技巧
return 0;
}
524. 愤怒的小鸟(集合,重复覆盖问题)


-
抛物线 y = a x 2 + b x + c y=ax^2+bx+c y=ax2+bx+c,且根据题意满足两个条件:1.a<0;2.过原点,c=0 -> 即只需两个点(且这两个点不在一条竖线上 x 1 ! = x 2 x_1 != x_2 x1!=x2),即可确定此抛物线
-
一共有n个点,因此最多有 n 2 n^2 n2条抛物线,先预处理所有抛物线,还要预处理这些抛物线能够覆盖的点有哪些。这个问题转化为给定若干条抛物线,问最少选择多少条抛物线可以覆盖所有点,这是一个经典的重复覆盖问题,这里用集合类型的状态压缩dp去优化爆搜
-
如果用爆搜怎么做呢?爆搜的核心是顺序(下图中图一的爆搜方案被pass了)


-
怎么考虑优化呢 ?上述dfs中state与返回的res肯定是一一对应的,所以用 f [ s t a t e ] f[state] f[state]存储res,避免重复计算,即记忆化搜索
-
根据两个点如何推抛物线公式 :
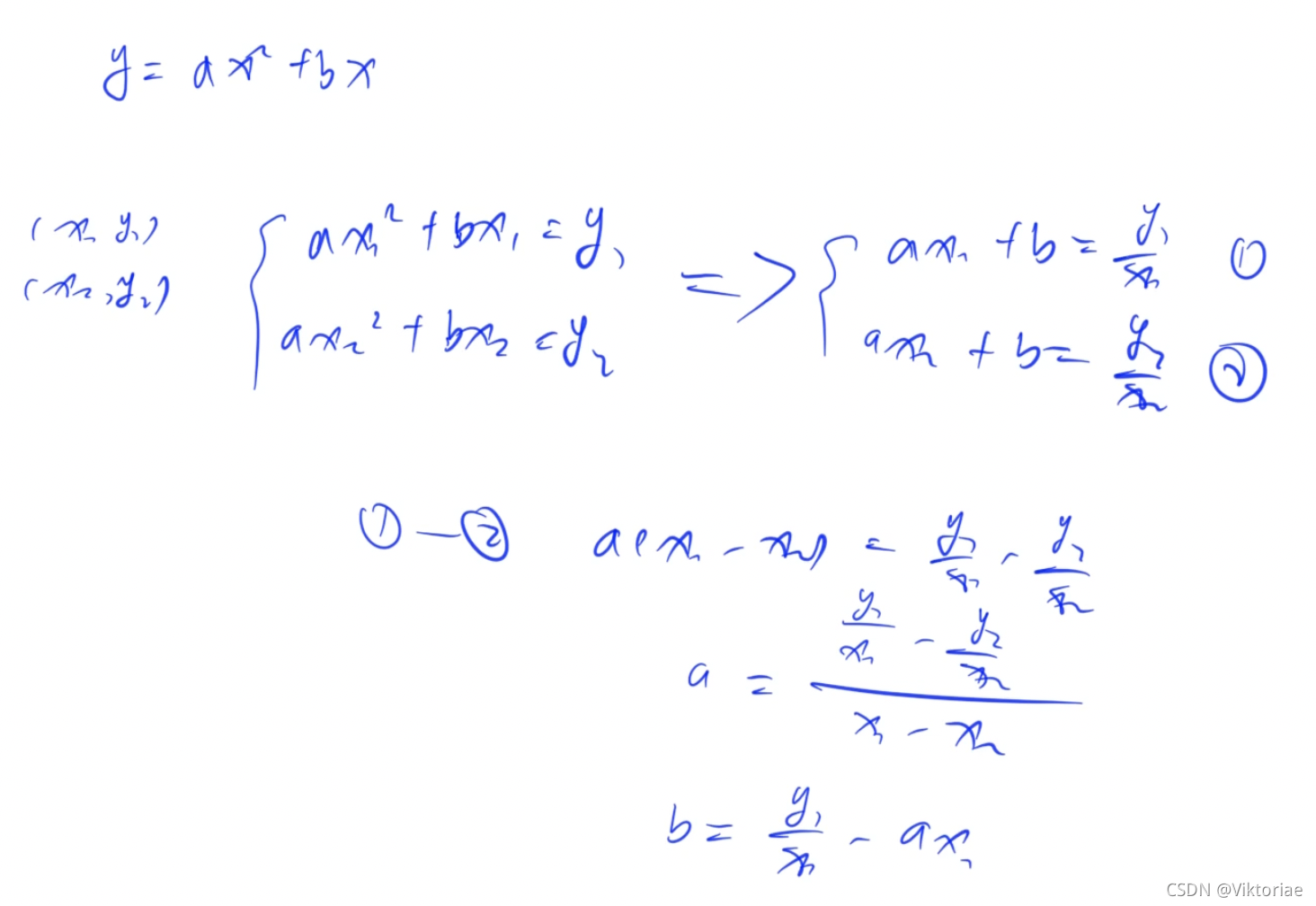 扫描二维码关注公众号,回复: 13263124 查看本文章
扫描二维码关注公众号,回复: 13263124 查看本文章
-
存二维坐标的常用技巧:typedef pair和x替代first
-
有些点可能无法与其它任何点共用一条抛物线的(因为要满足a<0),所以要先
path[i][i] = 1 << j -
一个易错点 :比较两个浮点数,由于浮点数是存在误差的,所以比较两个浮点数时需要考虑误差,可能两个浮点数相等,但存的时候由于一些计算导致它们值相差了一个很少的数,所以要加上一个误差的容忍度
-
f[0] = 0,0这个位置不需要任何抛物线,就比如dfs时调用的也是dfs(0, 0) -
所有能覆盖x的抛物线就是
path[x][j] -
fabs在头文件cmath中 -
状态转移时枚举状态是到
(1 << n) - 1 -
状态转移时每次只找一个最低位未被覆盖的点
#include <iostream>
#include <cstring>
#include <cmath>
#define x first
#define y second
using namespace std;
typedef pair<double, double> PDD;
const int N = 18, M = 1 << 18;
const double eps = 1e-8;
int n, m;
PDD q[N];
int path[N][N];
int f[M];
int cmp(double x, double y) // int 不是bool
{
if (fabs(x - y) < eps) return 0;
if (x < y) return -1;
return 1;
}
int main()
{
int _;
cin >> _;
while (_ -- )
{
cin >> n >> m;
for (int i = 0; i < n; i ++ ) cin >> q[i].x >> q[i].y;
memset(path, 0, sizeof path);
for (int i = 0; i < n; i ++ )
{
path[i][i] = 1 << i; // 应对特殊点
for (int j = 0; j < n; j ++ )
{
double x1 = q[i].x, y1 = q[i].y;
double x2 = q[j].x, y2 = q[j].y;
if (!cmp(x1, x2)) continue; // x1 == x2 continue
double a = (y1 / x1 - y2 / x2) / (x1 - x2);
double b = y1 / x1 - a * x1;
if (cmp(a, 0) >= 0) continue; // a >=0 continue
int state = 0;
for (int k = 0; k < n; k ++ )
{
double x = q[k].x, y = q[k].y;
if (!cmp(a * x * x + b * x, y))
state += 1 << k;
}
path[i][j] = state;
}
}
memset(f, 0x3f, sizeof f); // 求min
f[0] = 0;
for (int i = 0; i + 1 < 1 << n; i ++ ) // 求到(1 << n) - 2即可得到最后的(1 << n) - 1
{
int x = 0;
for (int j = 0; j < n; j ++ )
if (!(i >> j & 1))
{
x = j;
break;
}
for (int j = 0; j < n; j ++ )
f[i | path[x][j]] = min(f[i | path[x][j]], f[i] + 1);
}
cout << f[(1 << n) - 1] << endl;
}
return 0;
}
529. 宝藏


题意 :
- 给定一个n个点,m条边且连通的 无向图
- 初始时,无向图中没有边,每个 点 都是 互不连通 的
- 我们初始可以选择任意一个点作为 起点,且该选择 起点 的操作 费用 是0
- 然后开始维护这个包含起点的 连通快
- 每次我们选择一个与 连通快内的点 相连的一条边,使得该边的另一个点(本不在连通快内的点)加入连通快
- 该次选边操作的费用是: 边 权 ∗ 该 点 到 起 点 的 简 单 路 径 中 经 过 的 点 数 边权*该点到起点的简单路径中经过的点数 边权∗该点到起点的简单路径中经过的点数
- 最终我们的目标是,使得 所有点都加入当前的连通快内
- 求解一个 方案,在达成目标的情况下,费用最小,输出方案的费用
思路 :
- 题目要求已经连通的两点之间不需要连接额外的边(其实可以直接被推出),即我们只需要选择n - 1条边即可
- 因此,我们的目标是 找出图中的 最小生成树,但本题的最小生成树 和广义的最小生成树不一样,因为在本题中,加入连通快的费用是随当前点到起点的路径线性变化的(设经过的点数为k,则费用为 x ∗ k x*k x∗k)
- 计算该次加边的费用是用到了如下两个参数:
1.起点
2.当前点在当前生成树上到起点的简单路径上经过的点数 - 如果恰好是只有其中一项限制,我们都可以直接套最小生成树的模版改一改即可 :
1.只有起点限制,我们可以暴力枚举起点然后套Prim即可 O ( n 3 ) O(n^3) O(n3)
2.只有当前生成树的状态限制,我们可以额外开一个数组,记录加入生成树的点到起点经过的点数,然后dfs O ( 2 2 n ) O(2^{2n}) O(22n) - 然而本题这两个参数都要考虑,就不能直接套模版来改了(不优化的话,时间复杂度要到 O ( n 2 2 n ) O(n2^{2n}) O(n22n)
- 因此我们不妨采用 爆搜优化 -> 记忆化搜索 -> 动态规划 来解决该问题
- 我们把当前 生成树 的状态作为 DP 的阶段,那么需要额外记录的参数就是树的 深度,记录深度之后,可以保证我们枚举下一个阶段的状态时,能够轻易的计算他到起点的路径经过的点数,即我们把起点作为树的 root 然后一层一层构造 生成树

- 时间复杂度 :
1.预处理 O ( n 2 ∗ 2 n ) O(n^2*2n) O(n2∗2n)
2.动态规划 O ( n 2 ∗ 3 n ) O(n^2*3^n) O(n2∗3n),见如下分析

#include <iostream>
#include <cstring>
using namespace std;
const int N = 15, M = 1 << N, K = 1010;
const int INF = 0x3f3f3f3f;
int n, m;
int g[N][N];
int f[M][K];
int ne[M];
void init()
{
cin >> n >> m;
// 图的初始化
memset(g, 0x3f, sizeof g);
for (int i = 0; i < n; ++ i) g[i][i] = 0;
while (m -- )
{
int a, b, c;
cin >> a >> b >> c;
a -- , b -- ; // 状态压缩dp,所以编号从0开始
g[a][b] = g[b][a] = min(g[a][b], c);
}
for (int st = 1; st < 1 << n; ++ st) // 预处理所有状态能够扩展一层后得到的最大的下一层状态
for (int i = 0; i < n; ++ i)
if (st >> i & 1)
for (int j = 0; j < n; ++ j)
if (g[i][j] != INF)
ne[st] |= 1 << j;
}
int get_cost(int cur, int pre)
{
if ((ne[pre] & cur) != cur) return -1; // 如果pre延伸不到cur直接剪枝
int remain = pre ^ cur; // 待更新的方案
int cost = 0; // 记录边权总和
for (int i = 0; i < n; ++ i)
if (remain >> i & 1)
{
int t = INF;
for (int j = 0; j < n; ++ j)
if (pre >> j & 1)
t = min(t, g[i][j]);
cost += t;
}
return cost; // 返回该次扩展的费用
}
int dp()
{
memset(f, 0x3f, sizeof f);
for (int i = 0; i < n; ++ i) f[1 << i][0] = 0; // 开局免费选一个起点(初始状态)
for (int cur = 1, cost; cur < 1 << n; ++ cur)
for (int pre = cur & cur - 1; pre; pre = pre - 1 & cur)
if (~(cost = get_cost(cur, pre)))
for (int k = 0; k < n; ++ k)
f[cur][k] = min(f[cur][k], f[pre][k - 1] + cost * k);
int res = INF;
for (int k = 0; k < n; ++ k) res = min(res, f[(1 << n) - 1][k]);
return res;
}
int main()
{
init();
cout << dp() << endl;
return 0;
}