数据集
官方代码使用的Omniglot,但是Omniglot是 105 × 105 105 ×105 105×105大小的,官方给的omniglot_28x28.zip解压出来图片是resize过的,大小为 28 ∗ 28 28*28 28∗28。
网络
论文中的Relation Network包括两个部分embedding module和relation module。
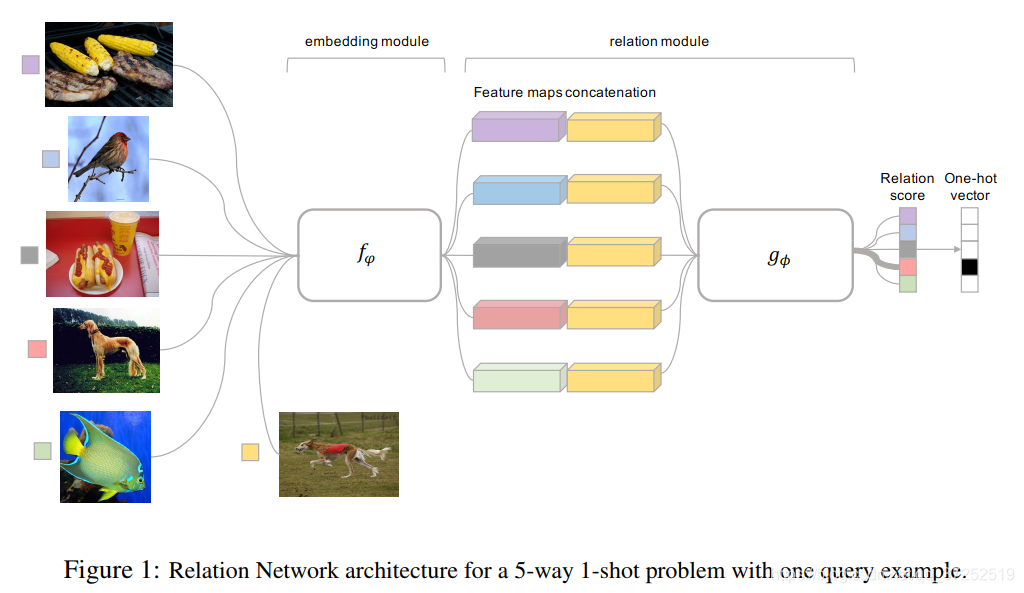
embedding module用于提取模型特征,官方代码中实现如下:
class CNNEncoder(nn.Module):
"""docstring for ClassName"""
def __init__(self):
super(CNNEncoder, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=3, padding=0),
nn.BatchNorm2d(64, momentum=1, affine=True),
nn.ReLU(),
nn.MaxPool2d(2))
self.layer2 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=0),
nn.BatchNorm2d(64, momentum=1, affine=True),
nn.ReLU(),
nn.MaxPool2d(2))
self.layer3 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64, momentum=1, affine=True),
nn.ReLU())
self.layer4 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64, momentum=1, affine=True),
nn.ReLU())
def forward(self, x): # x.shape -> torch.Size([5, 1, 28, 28])
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
# out.shape -> torch.Size([5, 64, 5, 5])
return out # 64
relation module用于计算两个拼接在一起的特征的相关性系数,官方代码中实现如下:
class RelationNetwork(nn.Module):
"""docstring for RelationNetwork"""
def __init__(self, input_size, hidden_size):
super(RelationNetwork, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(128, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64, momentum=1, affine=True),
nn.ReLU(),
nn.MaxPool2d(2))
self.layer2 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64, momentum=1, affine=True),
nn.ReLU(),
nn.MaxPool2d(2))
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, 1)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.size(0), -1)
out = F.relu(self.fc1(out))
out = F.sigmoid(self.fc2(out))
return out
模型每一层的参数初始化
def weights_init(m):
"""
层参数初始化
m -> Conv2d(1, 64, kernel_size=(3, 3), stride=(1, 1))
"""
classname = m.__class__.__name__
if classname.find('Conv') != -1:
# m一共有3*3*64=576个参数
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
# https://zhuanlan.zhihu.com/p/56253634
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif classname.find('BatchNorm') != -1:
m.weight.data.fill_(1)
m.bias.data.zero_()
elif classname.find('Linear') != -1:
n = m.weight.size(1)
m.weight.data.normal_(0, 0.01)
m.bias.data = torch.ones(m.bias.data.size())
运行代码
以omniglot_train_one_shot.py -w 5 -s 1 -b 10为例:就是每个episode是 5 w a y − 1 s h o t 5way-1shot 5way−1shot,每个类有10个测试
划分数据集
首先,将用函数将数据集划分为训练集和测试集,训练集的长度固定为1200,余下部分则为训练集
omniglot_train_one_shot.py line 143 143 143
print("init data folders")
# init character folders for dataset construction
metatrain_character_folders, metatest_character_folders = tg.omniglot_character_folders()
task_generator.py line 34 34 34
def omniglot_character_folders():
"""
数据集划分为训练集和测试集
"""
data_folder = '../datas/omniglot_resized/'
character_folders = [os.path.join(data_folder, family, character) \
for family in os.listdir(data_folder) \
if os.path.isdir(os.path.join(data_folder, family)) \
for character in os.listdir(os.path.join(data_folder, family))]
random.seed(1)
random.shuffle(character_folders)
num_train = 1200
# 训练集
metatrain_character_folders = character_folders[:num_train]
# 验证集
metaval_character_folders = character_folders[num_train:]
return metatrain_character_folders, metaval_character_folders
模型
omniglot_train_one_shot.py line 148 148 148
feature_encoder = CNNEncoder()
relation_network = RelationNetwork(FEATURE_DIM, RELATION_DIM)
模型的每一层都调用weights_init进行参数初始化
omniglot_train_one_shot.py line 152 152 152
feature_encoder.apply(weights_init)
relation_network.apply(weights_init)
如果有GPU可以使用
omniglot_train_one_shot.py line 156 156 156
feature_encoder.cuda(GPU)
relation_network.cuda(GPU)
设置模型的优化器,还有降低学习率
omniglot_train_one_shot.py line 159 159 159
feature_encoder_optim = torch.optim.Adam(feature_encoder.parameters(), lr=LEARNING_RATE) # 优化器
feature_encoder_scheduler = StepLR(feature_encoder_optim, step_size=100000, gamma=0.5) # 减小学习率
relation_network_optim = torch.optim.Adam(relation_network.parameters(), lr=LEARNING_RATE)
relation_network_scheduler = StepLR(relation_network_optim, step_size=100000, gamma=0.5)
加载之前训练好的模型
omniglot_train_one_shot.py line 170 170 170
if os.path.exists(str("./models/omniglot_feature_encoder_" + str(CLASS_NUM) + "way_" + str(SAMPLE_NUM_PER_CLASS) + "shot.pkl")):
feature_encoder.load_state_dict(torch.load(str("./models/omniglot_feature_encoder_" + str(CLASS_NUM) + "way_" + str(SAMPLE_NUM_PER_CLASS) + "shot.pkl"),map_location='cuda:0'))
print("load feature encoder success")
if os.path.exists(str("./models/omniglot_relation_network_" + str(CLASS_NUM) + "way_" + str(SAMPLE_NUM_PER_CLASS) + "shot.pkl")):
relation_network.load_state_dict(torch.load(str("./models/omniglot_relation_network_" + str(CLASS_NUM) + "way_" + str(SAMPLE_NUM_PER_CLASS) + "shot.pkl"),map_location='cuda:0'))
print("load relation network success")
开始训练
定义了一个last_accuracy用来保存模型最好的精度,如果后来的模型精度大于这个值就保存模型。详见
click on this link
omniglot_train_one_shot.py line 180 180 180
last_accuracy = 0.0
训练EPISODE个episode,默认值为1000000:
调整学习率
omniglot_train_one_shot.py line 184 184 184
feature_encoder_scheduler.step(episode)
relation_network_scheduler.step(episode)
随机选择一个角度,用于增强数据,对图片进行旋转
omniglot_train_one_shot.py line 190 190 190
degrees = random.choice([0, 90, 180, 270]) # 从四个数里随机选择一个
创建OmniglotTask对象 line 191 191 191
task = tg.OmniglotTask(metatrain_character_folders, CLASS_NUM, SAMPLE_NUM_PER_CLASS, BATCH_NUM_PER_CLASS)
OmniglotTask类的源代码如下:
task_generator.py line 56 56 56
class OmniglotTask(object):
""生成episode""
# This class is for task generation for both meta training and meta testing.
# For meta training, we use all 20 samples without valid set (empty here).
# For meta testing, we use 1 or 5 shot samples for training, while using the same number of samples for validation.
# If set num_samples = 20 and chracter_folders = metatrain_character_folders, we generate tasks for meta training
# If set num_samples = 1 or 5 and chracter_folders = metatest_chracter_folders, we generate tasks for meta testing
def __init__(self, character_folders, num_classes, train_num, test_num):
"""
character_folders : ['../datas/omniglot_resized/Gujarati\\character19',...,'../datas/omniglot_resized/Greek\\character20']
num_classes : 5 每个情境num_classes个类
train_num :1 每类train_num张训练图
test_num : 10 每类test_num个查询图
"""
self.character_folders = character_folders
self.num_classes = num_classes
self.train_num = train_num
self.test_num = test_num
# character_folders 训练文件夹的list;
class_folders = random.sample(self.character_folders, self.num_classes) # 随机抽取5个文件夹
labels = np.array(range(len(class_folders))) # 生成标签
labels = dict(zip(class_folders, labels)) # 文件夹和标签对应起来
samples = dict() # 文件夹路径 对应 包含文件夹路径下所有路径的列表
self.train_roots = [] # 每个情境用于训练的图的路径 num_classes * train_num
self.test_roots = [] # 每个情境用于测试的图的路径 num_classes * test_num
for c in class_folders:
temp = [os.path.join(c, x) for x in os.listdir(c)]
samples[c] = random.sample(temp, len(temp))
self.train_roots += samples[c][:train_num]
self.test_roots += samples[c][train_num:train_num + test_num]
# print(self.train_roots.__len__())
# print(self.test_roots.__len__())
self.train_labels = [labels[self.get_class(x)] for x in self.train_roots]
self.test_labels = [labels[self.get_class(x)] for x in self.test_roots]# self.get_class(self.test_roots[0])
def get_class(self, sample):
# 原代码
# return os.path.join(*sample.split('/')[:-1])
# 改成了这个版本
# print(sample.split('/')[-1])
# print(sample.split('/')[-1].split("\\")[0])
return os.path.join(sample.split('\\')[0],sample.split('\\')[1])
通过调试可以看到task的内容:
train_roots:support 5个不同类 每个类有1个路径train_label:support 的标签test_root:query 和support相同的5个类 每个类有10个路径 ,这10个路径和train_roots不重复test_label:query 的标签

调用函数get_data_loader获得数据加载器
omniglot_train_one_shot.py line 193 193 193
# support
sample_dataloader = tg.get_data_loader(task, num_per_class=SAMPLE_NUM_PER_CLASS, split="train", shuffle=False,rotation=degrees)
# query
batch_dataloader = tg.get_data_loader(task, num_per_class=BATCH_NUM_PER_CLASS, split="test", shuffle=True,rotation=degrees)
函数get_data_loader定义在task_generator.py line 169 169 169
def get_data_loader(task, num_per_class=1, split='train', shuffle=True, rotation=0):
"""
num_per_class=1 每个类几张图
split='train' 训练还是测试
shuffle=True
rotation=0 旋转的角度
"""
# NOTE: batch size here is # instances PER CLASS
# normalize = transforms.Normalize(mean=[0.92206, 0.92206, 0.92206], std=[0.08426, 0.08426, 0.08426]) #每个通道的均值和标准差
normalize = transforms.Normalize(mean=[0.92206], std=[0.08426]) #每个通道的均值和标准差,图片只有一个通道所以,把上一行代码注释了 改成了这一行
dataset = Omniglot(task, split=split,transform=transforms.Compose([Rotate(rotation), transforms.ToTensor(), normalize]))
if split == 'train':
sampler = ClassBalancedSampler(num_per_class, task.num_classes, task.train_num, shuffle=shuffle)
else:
sampler = ClassBalancedSampler(num_per_class, task.num_classes, task.test_num, shuffle=shuffle)
loader = DataLoader(dataset, batch_size=num_per_class * task.num_classes, sampler=sampler)
return loader
上面代码使用了Omniglot类,定义在omniglot_train_one_shot.py line 122 122 122
class Omniglot(FewShotDataset):
def __init__(self, *args, **kwargs):
super(Omniglot, self).__init__(*args, **kwargs)
def __getitem__(self, idx):
image_root = self.image_roots[idx]
image = Image.open(image_root)
image = image.convert('L')
image = image.resize((28, 28), resample=Image.LANCZOS) # per Chelsea's implementation
# image = np.array(image, dtype=np.float32)
if self.transform is not None:
image = self.transform(image)
label = self.labels[idx]
if self.target_transform is not None:
label = self.target_transform(label)
return image, label
Omniglot类继承自FewShotDataset类,FewShotDataset类定义在omniglot_train_one_shot.py line 105 105 105
class FewShotDataset(Dataset):
def __init__(self, task, split='train', transform=None, target_transform=None):
self.transform = transform # Torch operations on the input image
self.target_transform = target_transform
self.task = task
self.split = split
self.image_roots = self.task.train_roots if self.split == 'train' else self.task.test_roots
self.labels = self.task.train_labels if self.split == 'train' else self.task.test_labels
def __len__(self):
return len(self.image_roots)
def __getitem__(self, idx):
raise NotImplementedError("This is an abstract class. Subclass this class for your particular dataset.")
函数get_data_loader还用到了ClassBalancedSampler类,定义在task_generator.py line 141 141 141
class ClassBalancedSampler(Sampler):
''' Samples 'num_inst' examples each from 'num_cl' pools
of examples of size 'num_per_class' '''
def __init__(self, num_per_class, num_cl, num_inst, shuffle=True):
self.num_per_class = num_per_class
self.num_cl = num_cl
self.num_inst = num_inst
self.shuffle = shuffle
def __iter__(self):
# return a single list of indices, assuming that items will be grouped by class
if self.shuffle:
batch = [[i + j * self.num_inst for i in torch.randperm(self.num_inst)[:self.num_per_class]] for j in
range(self.num_cl)]
else:
batch = [[i + j * self.num_inst for i in range(self.num_inst)[:self.num_per_class]] for j in
range(self.num_cl)]
batch = [item for sublist in batch for item in sublist] # [[0],[1]...[4]] -> [0, 1, 2, 3, 4]
if self.shuffle:
random.shuffle(batch)
return iter(batch)
def __len__(self):
return 1
通过调试可以看到sample_dataloader和batch_dataloader的内容
sample_dataloader包括了 s u p p o r t support support中的 5 × 1 = 5 5×1=5 5×1=5个图片地址和标签batch_dataloader包括了 q u e r y query query中的 5 × 10 = 50 5×10=50 5×10=50个图片地址和标签
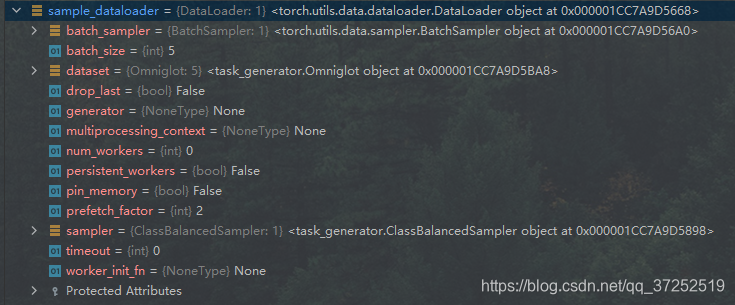
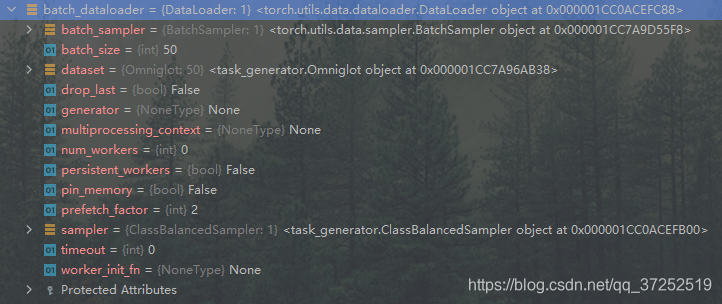
获取数据
omniglot_train_one_shot.py line 199 199 199
samples, sample_labels = sample_dataloader.__iter__().next()
# support samples.shape -> torch.Size([5, 1, 28, 28])
batches, batch_labels = batch_dataloader.__iter__().next()
# query batches.shape -> torch.Size([50, 1, 28, 28])
提取特征
使用embedding module提取 s u p p o r t support support和 q u e r y query query的特征
omniglot_train_one_shot.py line 203 203 203
sample_features = feature_encoder(Variable(samples).cuda(GPU))
# sample_features.shape -> torch.Size([5, 64, 5, 5])
batch_features = feature_encoder(Variable(batches).cuda(GPU))
# batch_features.shape -> torch.Size([50, 64, 5, 5])
拼接特征

根据论文所述,需要按着通道拼接特征。但是sample_features.shape -> torch.Size([5, 64, 5, 5])和batch_features.shape -> torch.Size([50, 64, 5, 5])的shape不同,不能直接拼接。
官方代码中先对tensor进行升维,然后通过repeat填充数据
sample_features.shape #torch.Size([5, 64, 5, 5])
sample_features.unsqueeze(0).shape #torch.Size([1, 5, 64, 5, 5])
sample_features.unsqueeze(0).repeat(BATCH_NUM_PER_CLASS * CLASS_NUM, 1, 1, 1, 1).shape #torch.Size([50, 5, 64, 5, 5])
sample_features_ext = sample_features.unsqueeze(0).repeat(BATCH_NUM_PER_CLASS * CLASS_NUM, 1, 1, 1, 1)
同理
batch_features_ext = batch_features.unsqueeze(0).repeat(SAMPLE_NUM_PER_CLASS * CLASS_NUM, 1, 1, 1, 1) # torch.Size([5, 50, 64, 5, 5])
但是batch_features_ext和sample_features_ext前两个维度刚好反过来,所以用torch.transpose交换
batch_features_ext = torch.transpose(batch_features_ext, 0, 1)
# batch_features_ext.shape -> torch.Size([50, 5, 64, 5, 5])
这样batch_features_ext和sample_features_ext的shape都是[50, 5, 64, 5, 5],满足在除了channel的shape上都相同,所以可以拼接。
torch.cat((sample_features_ext, batch_features_ext), 2).shape
#torch.Size([50, 5, 128, 5, 5]),128通道由两个64通道拼接而来
relation_pairs = torch.cat((sample_features_ext, batch_features_ext), 2).view(-1, FEATURE_DIM * 2, 5, 5)
# relation_pairs.shape -> torch.Size([250, 128, 5, 5])
获得relation cslore
将拼接好的特征输入模型,omniglot_train_one_shot.py line 214 214 214
relation_network(relation_pairs).shape
#torch.Size([250, 1])
relations = relation_network(relation_pairs).view(-1, CLASS_NUM)
#torch.Size([50, 5])
计算损失
使用均方差作为我们的损失函数:omniglot_train_one_shot.py line 216 216 216
mse = nn.MSELoss().cuda(GPU)
将query集的标签转换为one-hot标签:omniglot_train_one_shot.py line 217 217 217
one_hot_labels = Variable(torch.zeros(BATCH_NUM_PER_CLASS * CLASS_NUM, CLASS_NUM).scatter_(1, batch_labels.long().view(-1, 1), 1)).cuda(GPU)
计算损失:omniglot_train_one_shot.py line 219 219 219
loss = mse(relations, one_hot_labels)
优化模型
omniglot_train_one_shot.py line 223 223 223
# 梯度清零
feature_encoder.zero_grad()
relation_network.zero_grad()
# 损失函数后向传播
loss.backward()
# 梯度裁剪 https://blog.csdn.net/weixin_42628991/article/details/114845018
torch.nn.utils.clip_grad_norm(feature_encoder.parameters(), 0.5) torch.nn.utils.clip_grad_norm(relation_network.parameters(), 0.5)
# 优化
feature_encoder_optim.step()
relation_network_optim.step()
输出每个 e p i s o d e episode episode的损失:omniglot_train_one_shot.py line 235 235 235
# if (episode + 1) % 100 == 0:
if (episode + 1) % 1 == 0:
# print("episode:", episode + 1, "loss", loss.data[0])
print("episode:", episode + 1, "loss", loss.data.item())
在test数据上评估模型
同上过程,只不过用的test中的数据
保存模型
test_accuracy是在test数据上评估模型得到的准确度,如果test_accuracy大于之前最好模型的精度last_accuracy,就保存
模型omniglot_train_one_shot.py line 282 282 282
if test_accuracy > last_accuracy:
# save networks
torch.save(feature_encoder.state_dict(), str(
"./models/omniglot_feature_encoder_" + str(CLASS_NUM) + "way_" + str(
SAMPLE_NUM_PER_CLASS) + "shot.pkl"))
torch.save(relation_network.state_dict(), str(
"./models/omniglot_relation_network_" + str(CLASS_NUM) + "way_" + str(
SAMPLE_NUM_PER_CLASS) + "shot.pkl"))
print("save networks for episode:", episode)
last_accuracy = test_accuracy
总结
相比于之前的原型代码将函数保存在字典里,这次的官方代码还是十分友好的。通过调试逐步运行代码,可以比较容易地弄清楚。