1.CheckPoint原理
Flink 中基于异步轻量级的分布式快照技术提供了 Checkpoints 容错机制,分布式快照 可以将同一时间点 Task/Operator 的状态数据全局统一快照处理,包括前面提到的 Keyed State 和 Operator State。Flink 会在输入的数据集上间隔性地生成 checkpoint barrier, 通过栅栏(barrier)将间隔时间段内的数据划分到相应的 checkpoint 中。如下图:
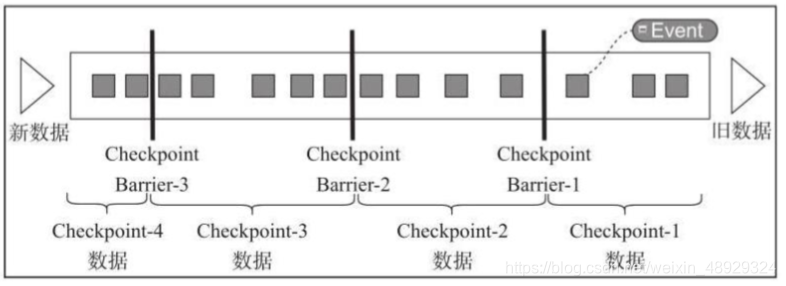
解释:每隔一段时间生成一个栅栏,两个栅栏之间的数据形成一个CheckPoint
2.CheckPoint参数和设置
默认情况下Flink是不开启检查点的,用户需要在程序中通过调用方法配置和开启检查点,另外还可以调整其他相关参数
1.Checkpoint开启和时间间隔指定:
开启检查点并且指定检查点的时间间隔为1000ms
streamEnv.enableCheckpointing(1000)
2.exactly-once和at-least-once语义的选择
1.exactly-once
保证整个应用内端到端的数据一致性,适用于对数据要求比较高,不允许出现丢失数据或者数据重复,同时Flink的性能也会相对较弱
streamEnv.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
2.at-least-once
适用于时延和吞吐量要求非常高但是对数据的一致性要求不高的场景
streamEnv.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.AT_LE AST_ONCE)
3.Checkpoint超时时间
超时时间指定了每次Checkpoint执行过程中的上限时间范围,一旦Checkpoint执行时间超过了该阈值,flink将会中断Checkpoint过程,并按照超时处理。(默认为10分钟)
streamEnv.getCheckpointConfig.setCheckpointTimeout(50000)
4.检查点之间的最小时间间隔
目的:防止出现例如状态数据过大而导致Checkpoint执行时间过长,从而导致Checkpoint积压过多,最终flink应用密集触发Checkpoint操作,占用大量的资源影响到整个应用的性能。
streamEnv.getCheckpointConfig.setMinPauseBetweenCheckpoints(600)
5.最大并行执行的检查点数量
默认情况下只有一个检查点可以运行,根据用户指定的数量可以同时出发多个Checkpoint,进而提升Checkpoint整体的效率。
streamEnv.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
6.是否删除Checkpoint中保存的数据
1.设置为 RETAIN_ON_CANCELLATION:
表示一旦 Flink 处理程序被 cancel 后,会保留 CheckPoint 数据,以便根据实际需要恢复到指定的 CheckPoint。
streamEnv.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckp ointCleanup.RETAIN_ON_CANCELLATION)
2.设置为 DELETE_ON_CANCELLATION:
表示一旦 Flink 处理程序被 cancel 后,会删除 CheckPoint 数据,只有 Job 执行失败的时候才会保存 CheckPoint
streamEnv.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckp ointCleanup.DELETE_ON_CANCELLATION)
7.TolerableCheckpointFailureNumber
设置可以容忍的检查失败数,超过这个数量则系统自动关闭和停止任务
streamEnv.getCheckpointConfig.setTolerableCheckpointFailureNumber(1)