文章目录
卷积可分为:
- 一维卷积
Conv1D - 二维卷积
Conv2D
一维卷积主要用于时间卷积,而二维卷积可运用于图像卷积。从维度上也就很好理解,什么是一维什么是二维卷积了。因为时间是一维的,而图像则是二维的。
一维卷积其实可看作二维卷积的特例,即二维卷积时有一维的卷积核为1,如一个长条形的图像。实际上TensorflowLite也只实现了Conv2D,将Conv1D的运算统统转化为Conv2D。
同时一维卷积还存在二维卷积没有的因果卷积,即padding=causal。
值得注意的是空洞卷积,也叫膨胀卷积、扩张卷积,即dilated Conv,即dialation_rate > 1。一维二维卷积均可进行空洞卷积。
因果卷积和空洞卷积在TCN中运用较多,即temporal convolution network。
1. 二维卷积 Conv2D
二维卷积在之前的博客中讲述过,可参考:https://blog.csdn.net/u010637291/article/details/112320280
1.1 输入参数
- 卷积的输入参数:指需要做卷积的输入图像/音频等,它要求是一个Tensor,具有
[batch, in_height, in_width, in_channels]这样的shape,具体图片的含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32和float64其中之一
主要参数包括:
-
filters:卷积核个数,也是输出通道数。Integer, the dimensionality of the output space (i.e. the number of output filters in the convolution). -
kernel_size: 卷积核大小,指定二维卷积窗口的高和宽,(如果kernel_size只有一个整数,代表宽和高相等):An integer or tuple/list of 2 integers, specifying the height and width of the 2D convolution window. Can be a single integer to specify the same value for all spatial dimensions. -
strides: 卷积步长,指定卷积窗沿高和宽方向的每次移动步长,An integer or tuple/list of 2 integers, (如果strides只有一个整数,代表沿着宽和高方向的步长相等) specifying the strides of the convolution along the height and width. Can be a single integer to specify the same value for all spatial dimensions. Specifying any stride value != 1 is incompatible with specifying anydilation_ratevalue != 1. -
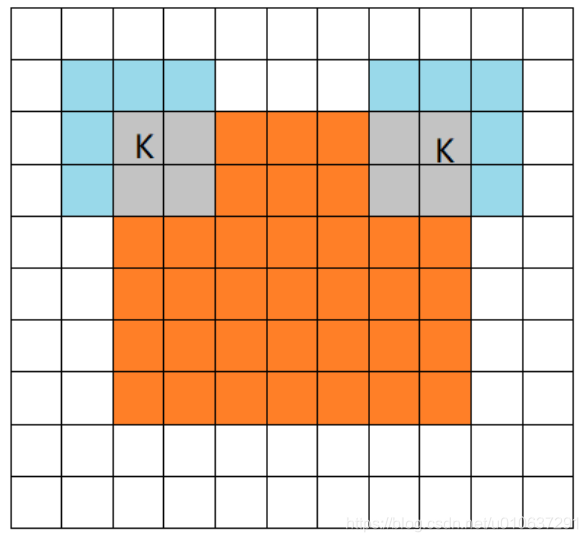
padding: 为valid或same中一种, one of"valid"or"same"(case-insensitive). 两种padding方式的区别如下:-
same mode
当filter的中心(K)与image的边角重合时,开始做卷积运算。注意:这里的same还有一个意思,卷积之后输出的feature map尺寸保持不变(相对于输入图片)。当然,same模式不代表完全输入输出尺寸一样,也跟卷积核的步长有关系。same模式也是最常见的模式,因为这种模式可以在前向传播的过程中让特征图的大小保持不变,调参师不需要精准计算其尺寸变化(因为尺寸根本就没变化)。
-
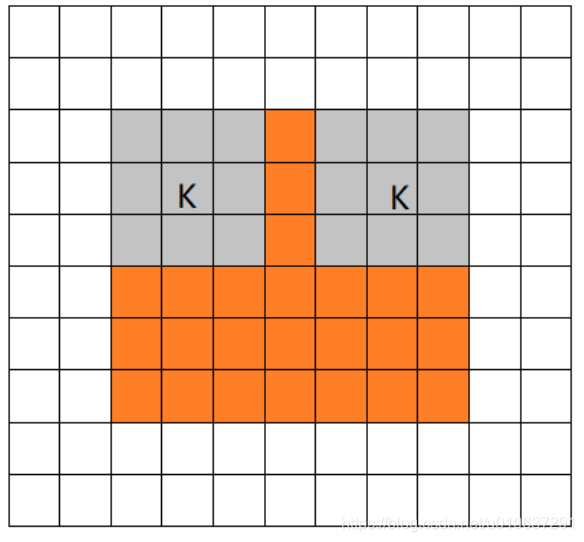
valid mode
即不进行padding:filter全部在image里面进行卷积运算,可见filter的移动范围较same变小了。
-
1.2 输出维数
ref: https://www.cnblogs.com/sddai/p/10512784.html
由上一小节可知,卷积层的padding方式不同,其输出维数也会不同。在此,分为padding=valid和padding=same两种情况进行说明:
1.2.1 padding=valid
给定输入参数:
- inputs=[batch_size, in_height, in_width, in_channels],
- filters,
- kernel_size=[k_h, k_w],
- stride_size=[s_h, s_w]
- padding=‘valid’
则输出参数为:
output = [batch_size, out_height, out_width, out_channels]
# 其中:
out_channels = filters
out_height = ceil((in_height - k_h + 1) / s_h)
out_width = ceil((in_width - k_w + 1) / s_w)
1.2.2 padding=same
给定输入参数:
- inputs=[batch_size, in_height, in_width, in_channels],
- filters,
- kernel_size=[k_h, k_w],
- stride_size=[s_h, s_w]
- padding=‘same’
则输出参数为:
output = [batch_size, out_height, out_width, out_channels]
# 其中:
out_channels = filters
out_height = ceil(in_height / s_h)
out_width = ceil(in_width / s_w)
1.1. 定义
在此附上源码定义
class Conv2D(Conv):
"""2D convolution layer (e.g. spatial convolution over images).
This layer creates a convolution kernel that is convolved
with the layer input to produce a tensor of
outputs. If `use_bias` is True,
a bias vector is created and added to the outputs. Finally, if
`activation` is not `None`, it is applied to the outputs as well.
When using this layer as the first layer in a model,
provide the keyword argument `input_shape`
(tuple of integers, does not include the sample axis),
e.g. `input_shape=(128, 128, 3)` for 128x128 RGB pictures
in `data_format="channels_last"`.
Arguments:
filters: Integer, the dimensionality of the output space (i.e. the number of
output filters in the convolution).
kernel_size: An integer or tuple/list of 2 integers, specifying the height
and width of the 2D convolution window. Can be a single integer to specify
the same value for all spatial dimensions.
strides: An integer or tuple/list of 2 integers, specifying the strides of
the convolution along the height and width. Can be a single integer to
specify the same value for all spatial dimensions. Specifying any stride
value != 1 is incompatible with specifying any `dilation_rate` value != 1.
padding: one of `"valid"` or `"same"` (case-insensitive).
`"valid"` means no padding. `"same"` results in padding evenly to
the left/right or up/down of the input such that output has the same
height/width dimension as the input.
data_format: A string, one of `channels_last` (default) or `channels_first`.
The ordering of the dimensions in the inputs. `channels_last` corresponds
to inputs with shape `(batch_size, height, width, channels)` while
`channels_first` corresponds to inputs with shape `(batch_size, channels,
height, width)`. It defaults to the `image_data_format` value found in
your Keras config file at `~/.keras/keras.json`. If you never set it, then
it will be `channels_last`.
dilation_rate: an integer or tuple/list of 2 integers, specifying the
dilation rate to use for dilated convolution. Can be a single integer to
specify the same value for all spatial dimensions. Currently, specifying
any `dilation_rate` value != 1 is incompatible with specifying any stride
value != 1.
groups: A positive integer specifying the number of groups in which the
input is split along the channel axis. Each group is convolved separately
with `filters / groups` filters. The output is the concatenation of all
the `groups` results along the channel axis. Input channels and `filters`
must both be divisible by `groups`.
activation: Activation function to use. If you don't specify anything, no
activation is applied (see `keras.activations`).
use_bias: Boolean, whether the layer uses a bias vector.
kernel_initializer: Initializer for the `kernel` weights matrix (see
`keras.initializers`).
bias_initializer: Initializer for the bias vector (see
`keras.initializers`).
kernel_regularizer: Regularizer function applied to the `kernel` weights
matrix (see `keras.regularizers`).
bias_regularizer: Regularizer function applied to the bias vector (see
`keras.regularizers`).
activity_regularizer: Regularizer function applied to the output of the
layer (its "activation") (see `keras.regularizers`).
kernel_constraint: Constraint function applied to the kernel matrix (see
`keras.constraints`).
bias_constraint: Constraint function applied to the bias vector (see
`keras.constraints`).
Input shape:
4+D tensor with shape: `batch_shape + (channels, rows, cols)` if
`data_format='channels_first'`
or 4+D tensor with shape: `batch_shape + (rows, cols, channels)` if
`data_format='channels_last'`.
Output shape:
4+D tensor with shape: `batch_shape + (filters, new_rows, new_cols)` if
`data_format='channels_first'` or 4+D tensor with shape: `batch_shape +
(new_rows, new_cols, filters)` if `data_format='channels_last'`. `rows`
and `cols` values might have changed due to padding.
Returns:
A tensor of rank 4+ representing
`activation(conv2d(inputs, kernel) + bias)`.
Raises:
ValueError: if `padding` is `"causal"`.
ValueError: when both `strides > 1` and `dilation_rate > 1`.
"""
def __init__(self,
filters,
kernel_size,
strides=(1, 1),
padding='valid',
data_format=None,
dilation_rate=(1, 1),
groups=1,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs):
super(Conv2D, self).__init__(
rank=2,
filters=filters,
kernel_size=kernel_size,
strides=strides,
padding=padding,
data_format=data_format,
dilation_rate=dilation_rate,
groups=groups,
activation=activations.get(activation),
use_bias=use_bias,
kernel_initializer=initializers.get(kernel_initializer),
bias_initializer=initializers.get(bias_initializer),
kernel_regularizer=regularizers.get(kernel_regularizer),
bias_regularizer=regularizers.get(bias_regularizer),
activity_regularizer=regularizers.get(activity_regularizer),
kernel_constraint=constraints.get(kernel_constraint),
bias_constraint=constraints.get(bias_constraint),
**kwargs)
1.2 使用示例
## tensorflow2.x
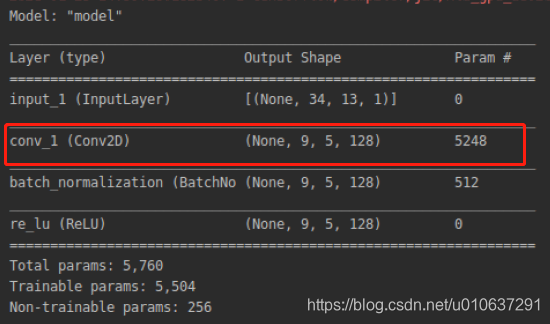
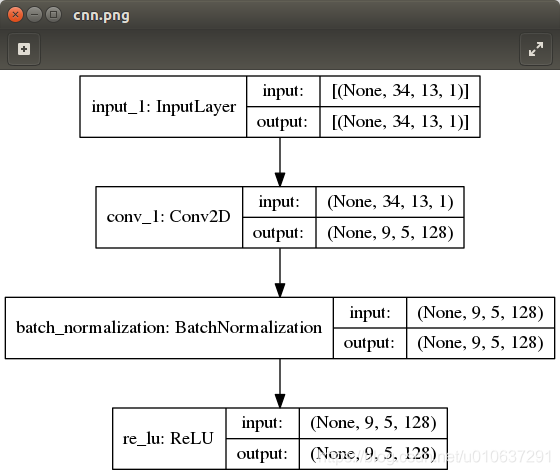
def cnn_model():
from tensorflow import keras
inputs = keras.Input(shape=(34, 13, 1))
net = keras.layers.Conv2D(filters=128, kernel_size=(10, 4), strides=(3, 2), padding='VALID', name='conv_1')(inputs)
net = keras.layers.BatchNormalization()(net)
outputs = keras.layers.ReLU()(net)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy']
)
model.summary()
keras.utils.plot_model(model, 'cnn.png', show_shapes=True)
return model
2. 一维卷积Conv1D
2.1 定义
其实和二维卷积变化不大:
- 输入变为三维变量
padding此时包括:same,valid和causal。
其输入输出的维度计算与二维卷积相同。
@keras_export('keras.layers.Conv1D', 'keras.layers.Convolution1D')
class Conv1D(Conv):
"""1D convolution layer (e.g. temporal convolution).
This layer creates a convolution kernel that is convolved
with the layer input over a single spatial (or temporal) dimension
to produce a tensor of outputs.
If `use_bias` is True, a bias vector is created and added to the outputs.
Finally, if `activation` is not `None`,
it is applied to the outputs as well.
When using this layer as the first layer in a model,
provide an `input_shape` argument
(tuple of integers or `None`, e.g.
`(10, 128)` for sequences of 10 vectors of 128-dimensional vectors,
or `(None, 128)` for variable-length sequences of 128-dimensional vectors.
Arguments:
filters: Integer, the dimensionality of the output space
(i.e. the number of output filters in the convolution).
kernel_size: An integer or tuple/list of a single integer,
specifying the length of the 1D convolution window.
strides: An integer or tuple/list of a single integer,
specifying the stride length of the convolution.
Specifying any stride value != 1 is incompatible with specifying
any `dilation_rate` value != 1.
padding: One of `"valid"`, `"same"` or `"causal"` (case-insensitive).
`"valid"` means no padding. `"same"` results in padding evenly to
the left/right or up/down of the input such that output has the same
height/width dimension as the input.
`"causal"` results in causal (dilated) convolutions, e.g. `output[t]`
does not depend on `input[t+1:]`. Useful when modeling temporal data
where the model should not violate the temporal order.
See [WaveNet: A Generative Model for Raw Audio, section
2.1](https://arxiv.org/abs/1609.03499).
data_format: A string,
one of `channels_last` (default) or `channels_first`.
dilation_rate: an integer or tuple/list of a single integer, specifying
the dilation rate to use for dilated convolution.
Currently, specifying any `dilation_rate` value != 1 is
incompatible with specifying any `strides` value != 1.
groups: A positive integer specifying the number of groups in which the
input is split along the channel axis. Each group is convolved
separately with `filters / groups` filters. The output is the
concatenation of all the `groups` results along the channel axis.
Input channels and `filters` must both be divisible by `groups`.
activation: Activation function to use.
If you don't specify anything, no activation is applied (
see `keras.activations`).
use_bias: Boolean, whether the layer uses a bias vector.
kernel_initializer: Initializer for the `kernel` weights matrix (
see `keras.initializers`).
bias_initializer: Initializer for the bias vector (
see `keras.initializers`).
kernel_regularizer: Regularizer function applied to
the `kernel` weights matrix (see `keras.regularizers`).
bias_regularizer: Regularizer function applied to the bias vector (
see `keras.regularizers`).
activity_regularizer: Regularizer function applied to
the output of the layer (its "activation") (
see `keras.regularizers`).
kernel_constraint: Constraint function applied to the kernel matrix (
see `keras.constraints`).
bias_constraint: Constraint function applied to the bias vector (
see `keras.constraints`).
Input shape:
3+D tensor with shape: `batch_shape + (steps, input_dim)`
Output shape:
3+D tensor with shape: `batch_shape + (new_steps, filters)`
`steps` value might have changed due to padding or strides.
Returns:
A tensor of rank 3 representing
`activation(conv1d(inputs, kernel) + bias)`.
Raises:
ValueError: when both `strides > 1` and `dilation_rate > 1`.
"""
def __init__(self,
filters,
kernel_size,
strides=1,
padding='valid',
data_format='channels_last',
dilation_rate=1,
groups=1,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs):
super(Conv1D, self).__init__(
rank=1,
filters=filters,
kernel_size=kernel_size,
strides=strides,
padding=padding,
data_format=data_format,
dilation_rate=dilation_rate,
groups=groups,
activation=activations.get(activation),
use_bias=use_bias,
kernel_initializer=initializers.get(kernel_initializer),
bias_initializer=initializers.get(bias_initializer),
kernel_regularizer=regularizers.get(kernel_regularizer),
bias_regularizer=regularizers.get(bias_regularizer),
activity_regularizer=regularizers.get(activity_regularizer),
kernel_constraint=constraints.get(kernel_constraint),
bias_constraint=constraints.get(bias_constraint),
**kwargs)
2.2 使用示例
输入为三维变量,padding=valid(不进行padding):
def cnn_model():
from tensorflow import keras
inputs = keras.Input(shape=(34, 1))
net = keras.layers.Conv1D(filters=128, kernel_size=(10), strides=(3), padding='VALID', name='conv_1')(inputs)
net = keras.layers.BatchNormalization()(net)
outputs = keras.layers.ReLU()(net)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy']
)
model.summary()
keras.utils.plot_model(model, 'cnn.png', show_shapes=True)
return model
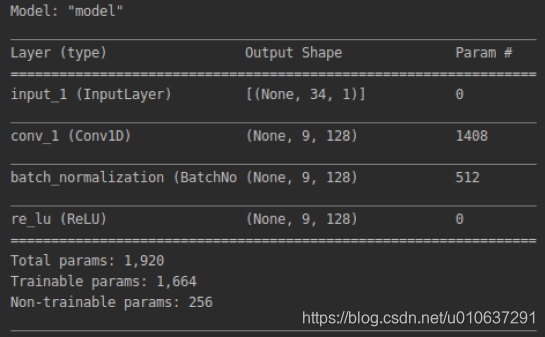
其实,输入为四维变量,也能进行一维卷积:
def cnn_model():
from tensorflow import keras
inputs = keras.Input(shape=(34, 13, 1))
net = keras.layers.Conv1D(filters=128, kernel_size=(10), strides=(3), padding='VALID', name='conv_1')(inputs)
net = keras.layers.BatchNormalization()(net)
outputs = keras.layers.ReLU()(net)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy']
)
model.summary()
keras.utils.plot_model(model, 'cnn.png', show_shapes=True)
return model

3. 一维因果卷积 Conv1D padding=causal
因为要处理序列问题(即要考虑时间问题)就不能使用普通的CNN卷积,必须使用新的CNN模型,这个就是因果卷积的作用,
对序列问题(sequence modeling),主要抽象为,根据x1…xt和y1…yt-1去预测yt,使得yt接近于实际值
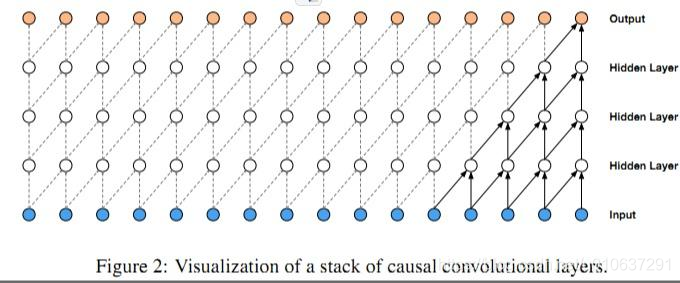
但是存在问题是,如果考虑很久之前的变量x,那么卷积层数就必须增加(自行体会)。。。
卷积层数的增加就带来:梯度消失,训练复杂,拟合效果不好的问题,为了决绝这个问题,出现了扩展卷积(dilated)
3.1 使用示例
使用因果卷积时,即设置padding=causal。注意因果卷积只适用于Conv1D和SeperableConv1D。
def cnn_model():
from tensorflow import keras
inputs = keras.Input(shape=(34, 1))
net = keras.layers.Conv1D(filters=128, kernel_size=(10), strides=(3), padding='causal', name='conv_1')(inputs)
net = keras.layers.BatchNormalization()(net)
outputs = keras.layers.ReLU()(net)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy']
)
model.summary()
keras.utils.plot_model(model, 'cnn.png', show_shapes=True)
return model
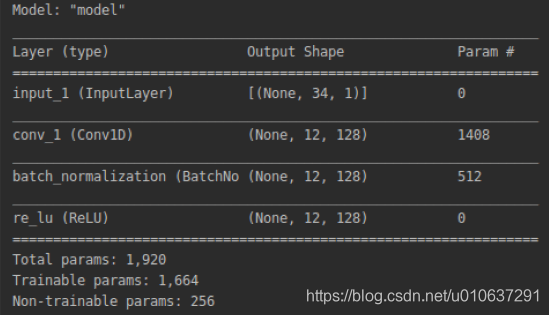
TODO:至于怎么算出输出为12维,我也不知道
4. 空洞卷积
ref: https://www.zhihu.com/question/54149221
Dilated Conv, 也叫扩展卷积、膨胀卷积、空洞卷积。
对于因果卷积,存在的一个问题是需要很多层或者很大的filter来增加卷积的感受野。
空洞卷积(dilated convolution)是通过跳过部分输入来使filter可以应用于大于filter本身长度的区域。等同于通过增加零来从原始filter中生成更大的filter。
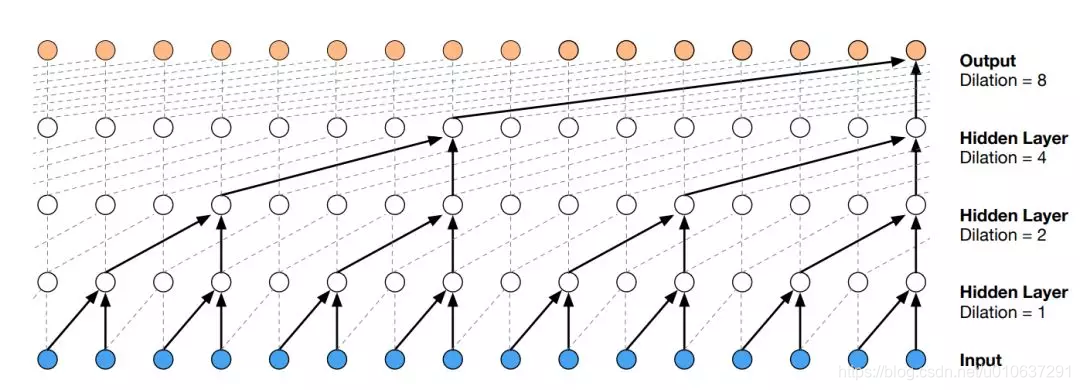
dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。在图像需要全局信息或者语音文本需要较长的sequence信息依赖的问题中,都能很好的应用dilated conv,比如图像分割、语音合成WaveNet、机器翻译ByteNet中.
4.1 空洞因果卷积 Dilated causal Conv
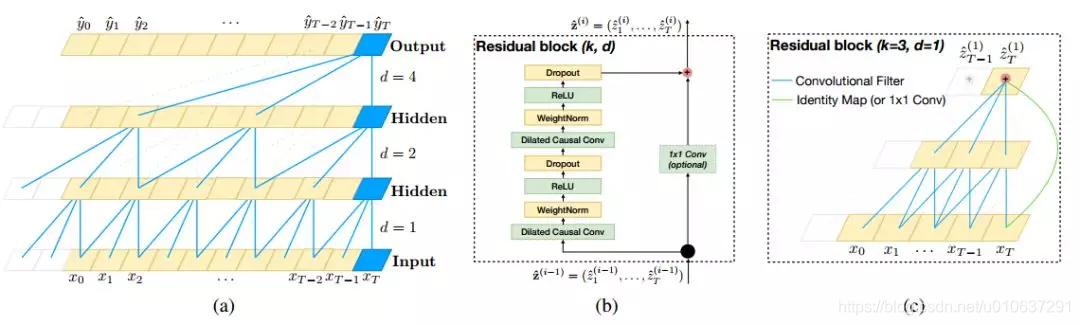
使用因果空洞卷积时,即设置padding=causal, dilated_rate > 1。注意因果卷积只适用于Conv1D和SeperableConv1D,所以Dilated causal conv也只适用于这两个,无法适用二维卷积。
4.2 使用示例
def cnn_model():
from tensorflow import keras
inputs = keras.Input(shape=(34, 1))
net = keras.layers.Conv1D(filters=128, kernel_size=(10), strides=(1), padding='causal', dilation_rate=3, name='conv_1')(inputs)
net = keras.layers.BatchNormalization()(net)
outputs = keras.layers.ReLU()(net)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy']
)
model.summary()
keras.utils.plot_model(model, 'cnn.png', show_shapes=True)
return model
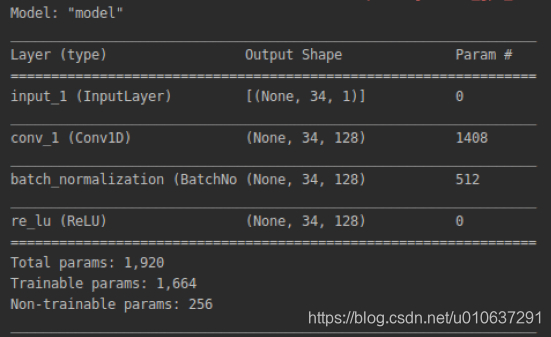
注意,当dilated_rate > 1时,strides需等于1,否则会出现错误:
- ValueError: strides > 1 not supported in conjunction with dilation_rate > 1
而不管dilated_value等于何值,输出维度都是34。TODO:具体推理我也不知道