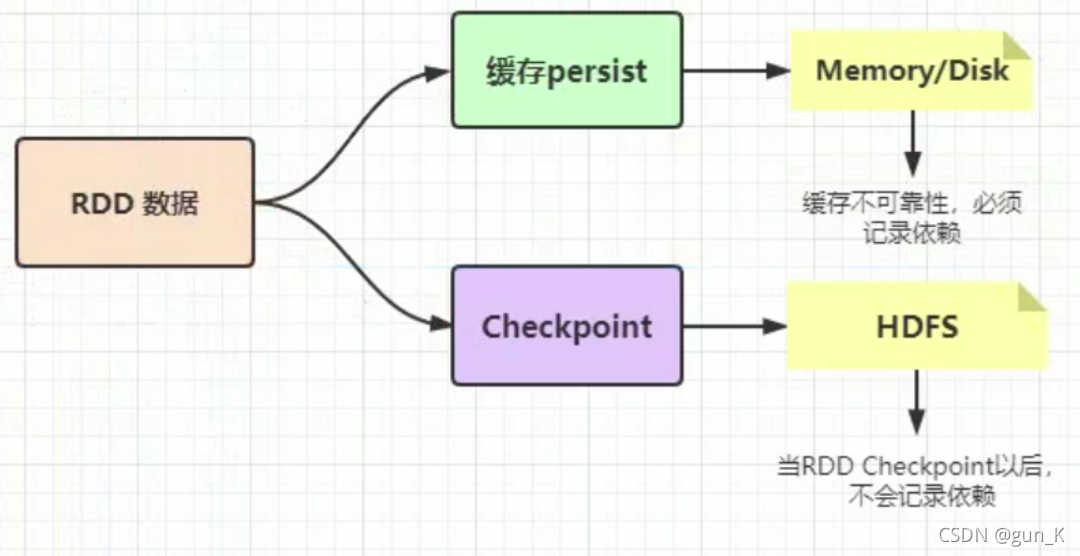
RDD持久化
在实际开发中,某些RDD的计算或转换可能比较耗时间,如果这些RDD后续还会频繁的被使用到,那么可以将这些RDD进行持久化(缓存),这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率。
1. 缓存函数
可以将RDD数据直接缓存到内存当中,函数申明如下:
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
def cache(): this.type = persist()
但是实际项目中,不会直接使用上述的缓存函数,RDD数据量往往很多,内存放不下的。在实际的项目中缓存RDD数据时,往往使用如下函数,依据具体的业务和数据量,指定缓存的级别:
def persist(newLevel: StorageLevel): this.type
2. 缓存级别
在 Spark 框架中对数据缓存可以指定不同的级别,对于开发来说至关重要,如下所示:
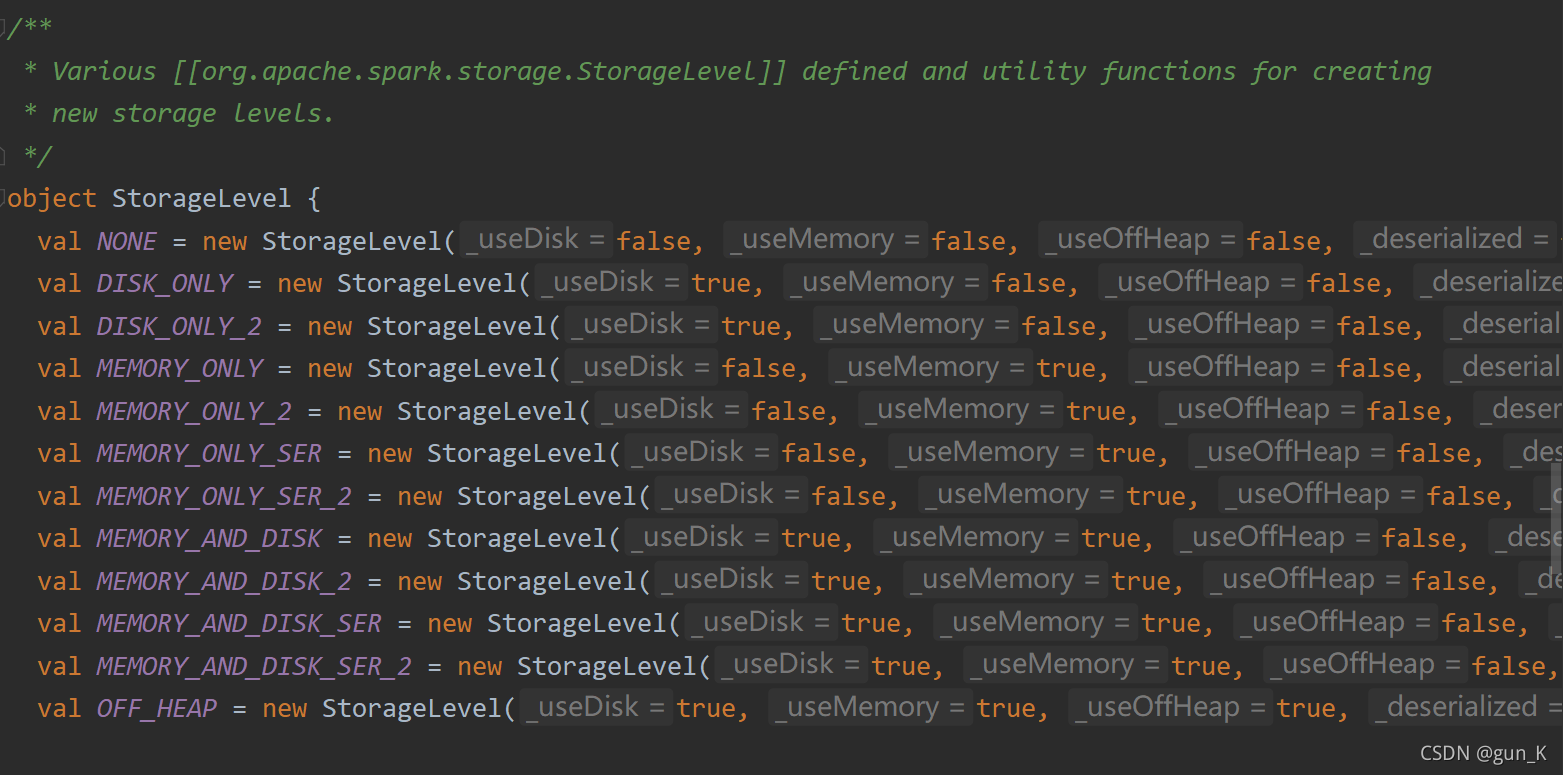
代码意思如下:
// 表示不缓存
val NONE = new StorageLevel(false, false, false, false)
// 表示缓存数据到磁盘中
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2) //副本2份
// 表示缓存数据到内存中(Executor中内存)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false) //是否序列化
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
// 表示缓存数据到内存(Executor中内存),如果内存不足缓存到磁盘(此种方式应该是最多)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
// 表示缓存数据到内存当中
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
在实际项目中缓存数据时,往往选择如下俩种级别:
- MEMORY_AND_DISK
- MEMORY_AND_DISK_2
缓存函数与Transformation函数一样,都是Lazy操作,需要Action函数触发,通常使用count函数触发。
3. 释放缓存
当缓存的RDD数据,不在被使用时,考虑释放资源,使用函数如下:
def unpersist(blocking: Boolean = true): this.type
此函数属于eager,立即执行。
4. 何时缓存数据
在实际项目开发中,什么时候缓存RDD数据,最好呢???
- 1.当某个RDD被使用多次时,建议缓存此RDD数据。
- 比如,从HDFS上读取网站行为日志数据时,进行多维度的分析,最好缓存数据。
val logsRDD = sc.textFile("...)
// 将RDD数据进行缓存
logsRDD.cache()
// pv
val pvRDD = logsRDD.xxx
// uv
val uvRDD = logsRDD.yyyy
// ip
val ipRDD = logsRDD.zzzz
// ....
logsRDD.unpersist()
- 2.当某个RDD来之不易,并且使用不止一次,建议缓存。
- 比如,从Hbase表中读取历史订单数据,与从MySQL表中商品和用户维度信息数据,进行关联join等聚合操作,获取RDD:etlRDD,后续的报表分析使用此RDD,此时建议缓存RDD数据。
- 案例:etlRDD.persist(StoageLevel.MEMORY_ANDDISK_2)
代码演示:
import org.apache.spark.{
SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
object SparkCacheTest {
def main(args: Array[String]): Unit = {
// 构建Spark Application应用层入口实例对象
val sc: SparkContext = {
// a. 创建SparkConf对象,设置应用信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// b. 传递SparkConf对象,创建实例
SparkContext.getOrCreate(sparkConf)
}
// 1. 读取数据,封装为RDD
val inputRDD: RDD[String] = sc.textFile("datas/wordcount.data")
// TODO: 将RDD数据进行缓存
inputRDD.persist(StorageLevel.MEMORY_AND_DISK)
inputRDD.count() // 触发缓存执行
inputRDD.foreach(println)
// TODO: 当某个缓存RDD不在被使用时,是否资源
//inputRDD.unpersist()
// 应用结束,关闭资源
Thread.sleep(1000000)
sc.stop()
}
}
运行结果如下图:
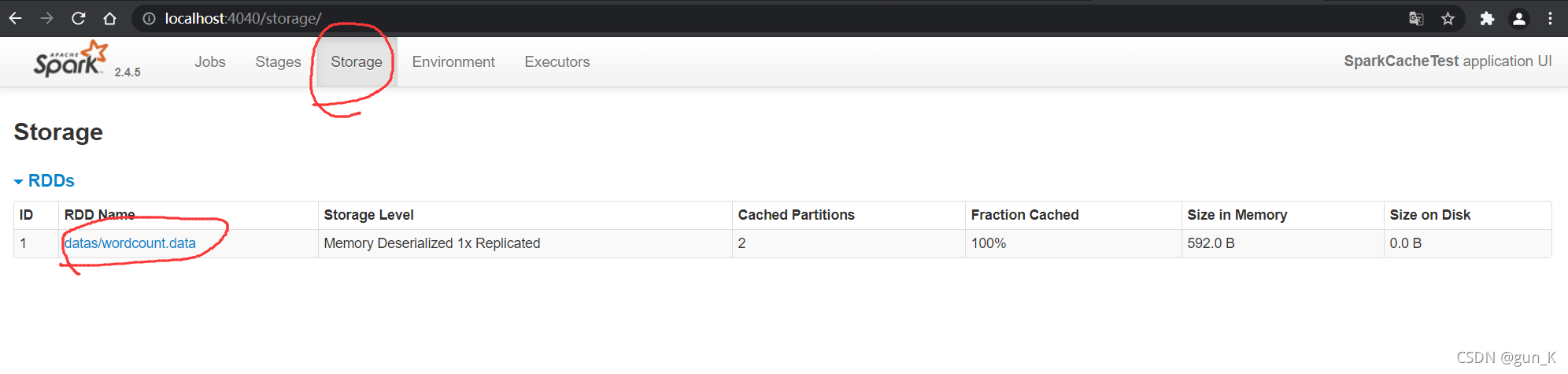
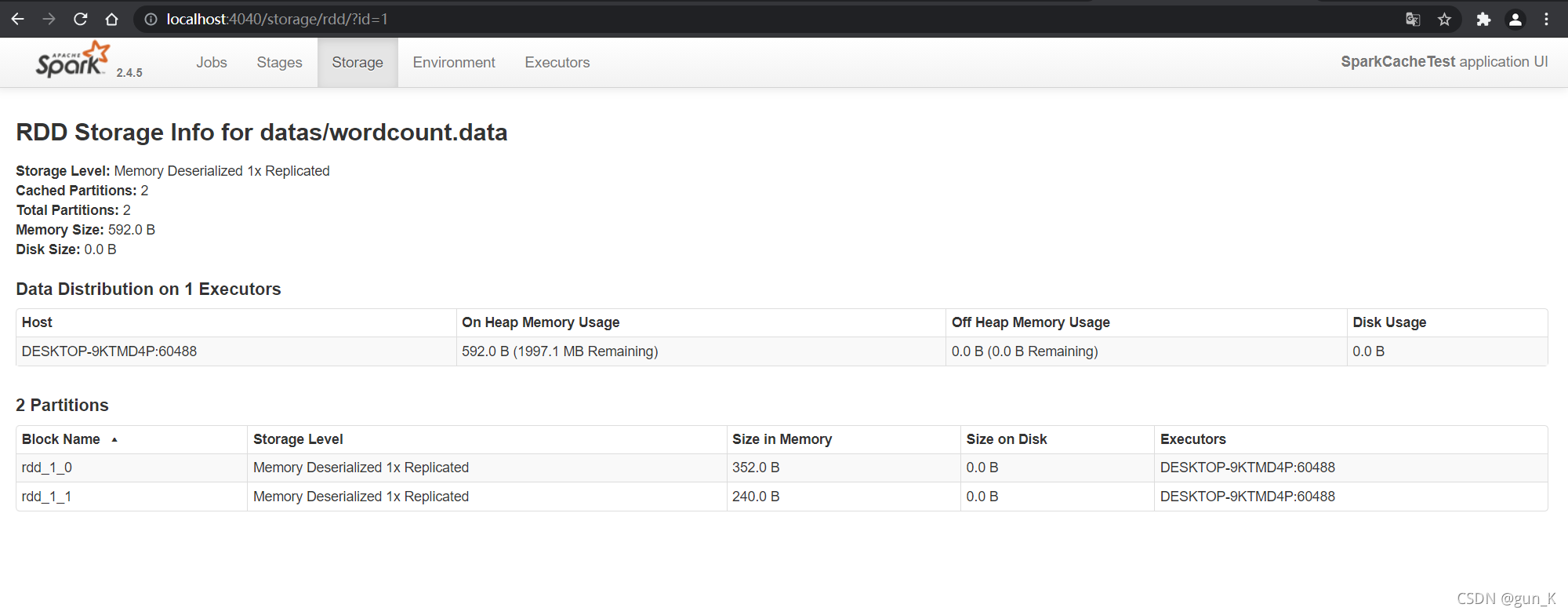
RDD Checkpoint
RDD 数据可以持久化,但是持久化(缓存)可以把数据放在内存中,虽然是快速的,但是也是最不可靠的,也可以把数据放在磁盘上,也是完全不可靠的!例如磁盘会损坏等。
Checkpoint 的产生就是为了更加可靠的数据持久化,在 Cheakpoint 的时候一般把数据放在 HDFS 上,这就天然的借助了 HDFS 天生的高容错、高可靠来实现数据最大程度上的安全,实现了 RDD 的容错和高可用。
在 Spark Core 中对RDD做 checkpoint,可以切断做 checkpoint RDD 的依赖关系,将 RDD数据保存到可靠存储(如HDFS)以便恢复数据。
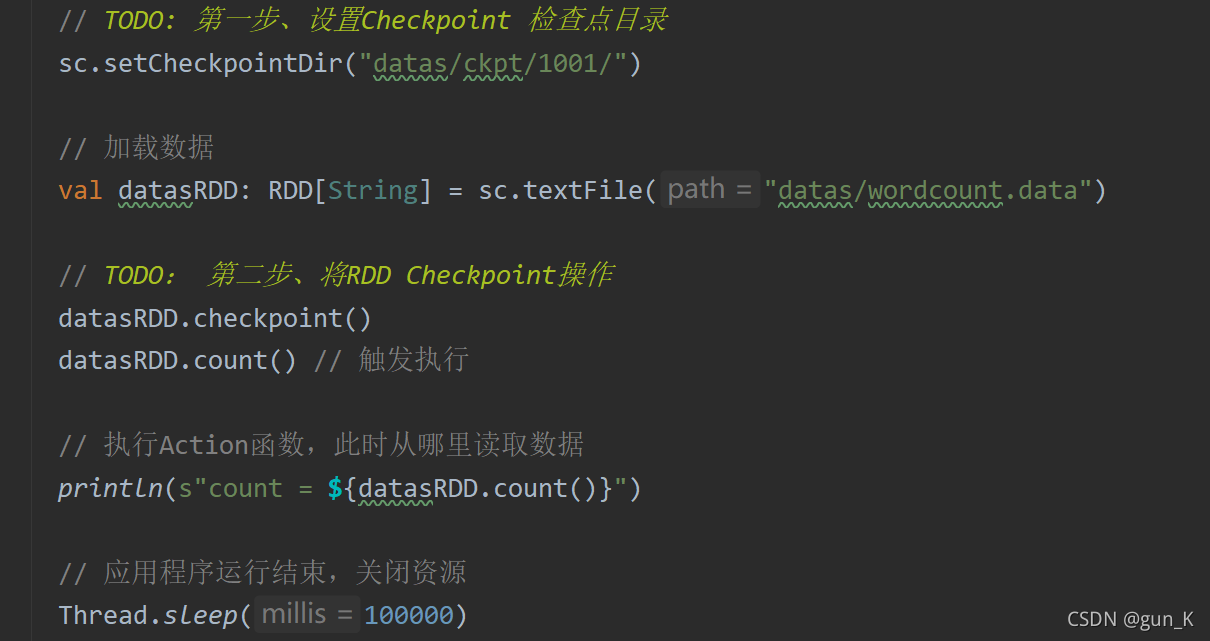
案例演示
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/**
* RDD数据Checkpoint设置,案例演示
*/
object SparkCkptTest {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
// TODO: 第一步、设置Checkpoint 检查点目录
sc.setCheckpointDir("datas/ckpt/1001/")
// 加载数据
val datasRDD: RDD[String] = sc.textFile("datas/wordcount.data")
// TODO: 第二步、将RDD Checkpoint操作
datasRDD.checkpoint()
datasRDD.count() // 触发执行
// 执行Action函数,此时从哪里读取数据
println(s"count = ${datasRDD.count()}")
// 应用程序运行结束,关闭资源
Thread.sleep(100000)
sc.stop()
}
}
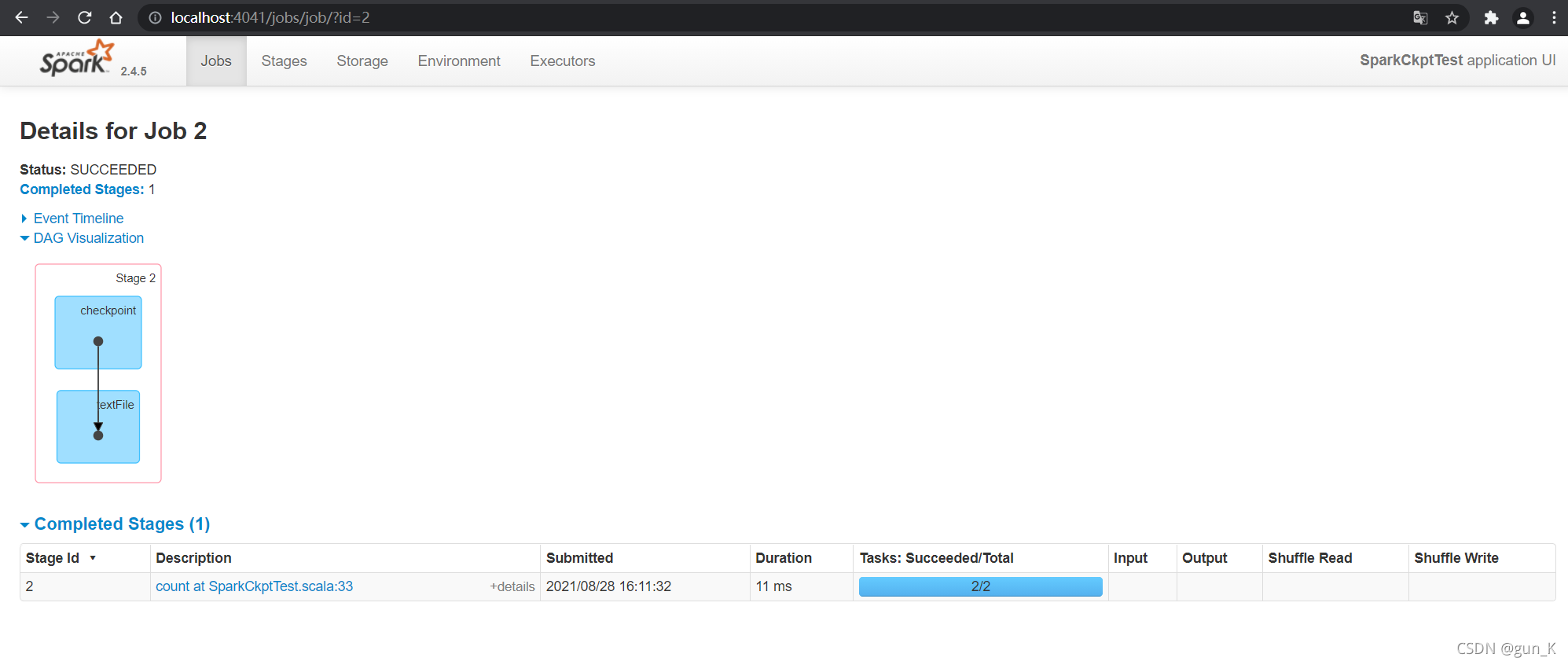
运行结果:
持久化和Checkpoint的区别
- 1、存储位置
- Persist 和 Cache 只能保存在本地的磁盘和内存中(或者堆外内存);
- Checkpoint 可以保存数据到 HDFS 这类可靠的存储上;
- 2、生命周期
- Cache和Persist的RDD会在程序结束后会被清除或者手动调用unpersist方法;
- Checkpoint的RDD在程序结束后依然存在,不会被删除;
- 3、Lineage(血统、依赖链、依赖关系)
- Persist和Cache,不会丢掉RDD间的依赖链/依赖关系,因为这种缓存是不可靠的,如果出现了一些错误(例如 Executor 宕机),需要通过回溯依赖链重新计算出来;
- Checkpoint会斩断依赖链,因为Checkpoint会把结果保存在HDFS这类存储中,更加的安全可靠,一般不需要回溯依赖链;