要点1
目前超分的SOTA算法是基于CNN的,几乎没有用Transformer的研究。所以本文提出了一个超分的baseline:SwinIR,它包含三个部分,浅层特征提取、深层特征提取和高质量图像重建。深度特征提取是由几个残差的Swin Transformer块(RSTB)组成,并且整体有一个残差连接。
要点2
网络结构如下:
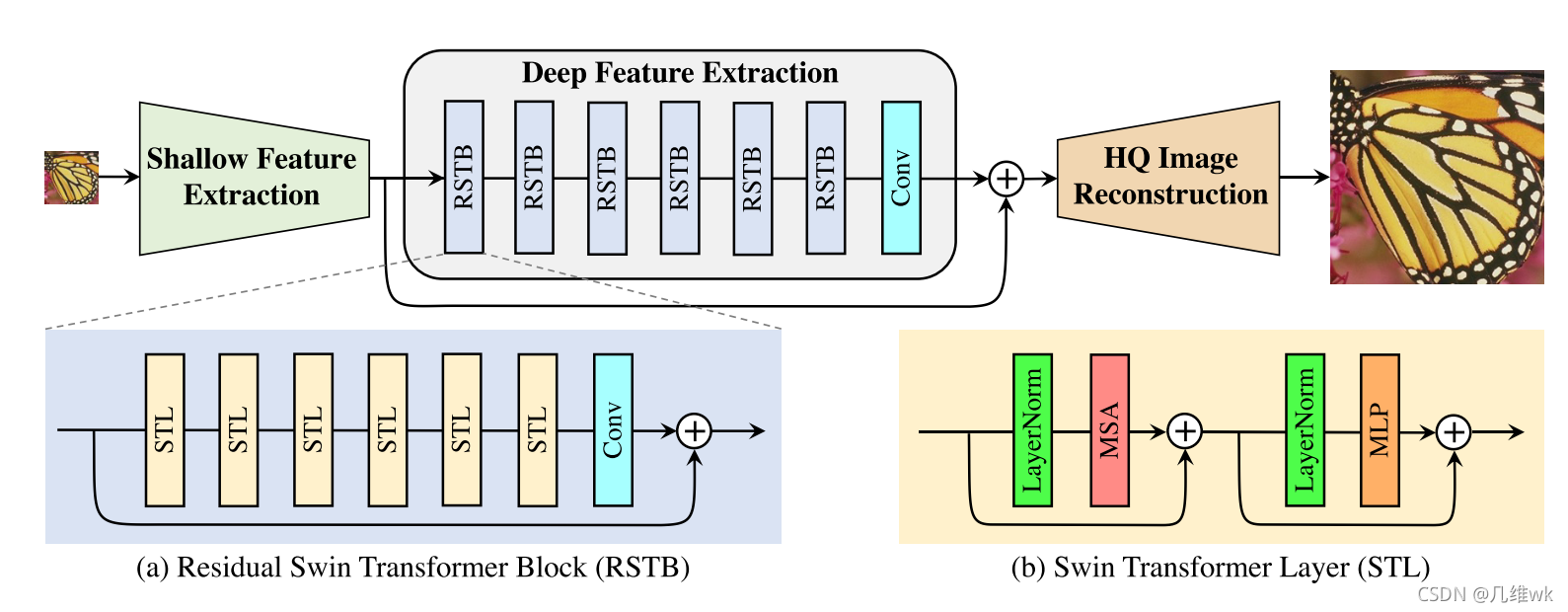
SR任务训练时损失函数采用L1损失,对于图像去噪和JPEG压缩伪影重建任务上,使用Charbonnier loss。
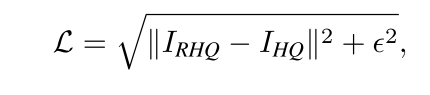
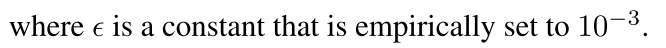
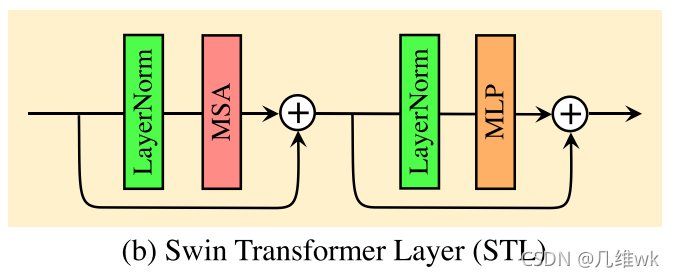
要点3
MLP源码实现:

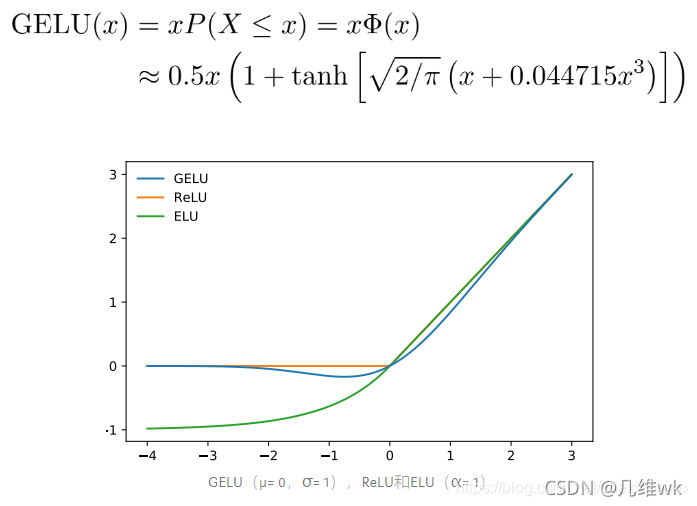
其实就是全连接网络,用了GELU损失函数
GELU的全称是GAUSSIAN ERROR LINEAR UNIT
与Sigmoids相比,像ReLU,ELU和PReLU这样的激活可以使神经网络更快更好地收敛。
此外,Dropout通过将一些激活数乘以0来规范化模型。
以上两种方法共同决定了神经元的输出。但是,两者彼此独立工作。GELU旨在将它们结合起来。
另外,称为Zoneout的新RNN正则化器将输入随机乘以1。
我们希望通过将输入乘以0或1并确定性地获得(激活函数的)输出值来合并所有3个功能,就有了GELU。
MSA其实就是Transformer中的多头注意力机制,他的过程是先把尺寸为HxWXC的特征图给分成多个块(窗口),块的大小为MxMxC,每个块(窗口)进行多头注意力,注意力是如下公式:
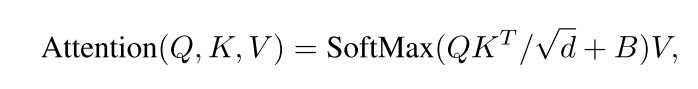
这个公式,可以参看知乎文章超详细图解Self-Attention。