数论最经典的当然是素数的判定等等吧!
素数:
埃筛--------------埃拉托斯特尼筛法,或者叫埃氏筛法
原理:如果找到一个质数,那么这个质数的倍数都不是质数
#include<cstdio>
const int N = 100000 + 5;
bool prime[N];
void init(){
for(int i = 2; i < N; i ++) prime[i] = true;
for(int i = 2; i*i < N; i ++){//判断改成i*i<N
if(prime[i]){
for(int j = i*i; j < N; j += i){//从i*i开始就可以了
prime[j] = false;
}
}
}
}
int main(){
init();
}线筛
#include<cstdio>
const int N = 100000 + 5;
bool prime[N];//prime[i]表示i是不是质数
int p[N], tot;//p[N]用来存质数
void init(){
for(int i = 2; i < N; i ++) prime[i] = true;//初始化为质数
for(int i = 2; i < N; i++){
if(prime[i]) p[tot ++] = i;//把质数存起来
for(int j = 0; j < tot && i * p[j] < N; j++){
prime[i * p[j]] = false;
if(i % p[j] == 0) break;//保证每个合数被它最小的质因数筛去
}
}
}
int main(){
init();
}基于埃筛的原理,我们可以用它干很多事
比如预处理每个数的所有质因数!
#include<cstdio>
#include<vector>
using namespace std;
const int N = 100000 + 5;
vector<int > prime_factor[N];
void init(){
for(int i = 2; i < N; i ++){
if(prime_factor[i].size() == 0){//如果i是质数
for(int j = i; j < N; j += i){
prime_factor[j].push_back(i);
}
}
}
}
int main(){
init();
}比如预处理每个数的所有因数
#include<cstdio>
#include<vector>
using namespace std;
const int N = 100000 + 5;
vector<int > factor[N];
void init(){
for(int i = 2; i < N; i ++){
for(int j = i; j < N; j += i){
factor[j].push_back(i);
}
}
}
int main(){
init();
}比如预处理每个数的质因数分解
#include<cstdio>
#include<vector>
using namespace std;
const int N = 100000 + 5;
vector<int > prime_factor[N];
void init(){
int temp;
for(int i = 2; i < N; i ++){
if(prime_factor[i].size() == 0){
for(int j = i; j < N; j += i){
temp = j;
while(temp % i == 0){
prime_factor[j].push_back(i);
temp /= i;
}
}
}
}
}
int main(){
init();
}定理:
数论四大定理:
1.威尔逊定理
2.欧拉定理
3.孙子定理(中国剩余定理)
4.费马小定理
1.威尔逊定理:(PS:威尔逊是个厉害人)
当且仅当p为素数时:( p -1 )! ≡ -1 ( mod p )
或者这么写( p -1 )! ≡ p-1 ( mod p )
或者说
若p为质数,则p能被(p-1)!+1整除
2.欧拉定理:(PS:欧拉是个厉害人)
欧拉定理,也称费马-欧拉定理
若n,a为正整数,且n,a互质,即gcd(a,n) = 1,则
a^φ(n) ≡ 1 (mod n)
φ(n) 是欧拉函数
欧拉函数是求小于等于n的数中与n互质的数的数目
(o>▽<)太长看不懂?我来帮你断句
欧拉函数是求 (小于n的数 )中 (与n互质的数 )的数目
或者说
欧拉函数是求 1到n-1 中 与n互质的数 的数目
如果n是质数
那么1到n-1所有数都是与n互质的,
所以φ(n) = n-1
如果n是合数。。。自己算吧
例如φ(8)=4,因为1,3,5,7均和8互质
顺便一提,这是欧拉定理
φ(n)是欧拉函数
还有一个欧拉公式
eix = cosx + isinx
把x用π带进去,变成
eiπ= -1
大部分人写成 eiπ + 1 = 0
这是一个令万人膜拜的伟大公式
引用一个名人的话(我忘了是谁( ̄▽ ̄lll)):
"它把自然对数e,虚数i,无理数π,自然界中的有和无(1和0)巧妙的结合了起来,上帝如果不存在,怎么会有这么优美的公式。
如何见到它第一眼的人没有看到它的魅力,那它一定成不了数学家"
一定要分清 欧拉定理,欧拉函数和欧拉公式这3个东西,要不然你就百度不到你想要的东西了(其实我在说我自己 ̄ε  ̄)
3.孙子定理(中国剩余定理):(PS:孙子是个厉害人。。。这话怎么在哪里听过( ・◇・)?好耳熟)
孙子定理,又称中国剩余定理。
公元前后的《孙子算经》中有“物不知数”问题:“今有物不知其数,三三数之余二 ,五五数之余三 ,七七数之余二,问物几何?”答为“23”。
就是说,有一个东西不知道有多少个,但是它求余3等于2,求余5等于3,求余7等于2,问这个东西有多少个?”答为“23”。
用现代数学的语言来说明的话,中国剩余定理给出了以下的一元线性同余方程组:
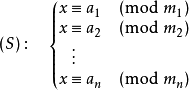
中国剩余定理说明:假设整数m1,m2, ... ,mn两两互质,则对任意的整数:a1,a2, ... ,an,方程组 (S)有解
4.费马小定理:(PS:费马是个厉害人。。。好了最后一遍,不玩了)
假如p是质数,若p不能整除a,则 a^(p-1) ≡1(mod p),若p能整除a,则a^(p-1) ≡0(mod p)。
或者说,若p是质数,且a,p互质,那么 a的(p-1)次方除以p的余数恒等于1。
你看你看你看o(*≧▽≦)ツ,是不是和欧拉定理很像
因为欧拉定理是费马小定理的推广,所以欧拉定理也叫费马-欧拉定理(费马:欧拉是坏人(/TДT)/,盗取我的成果,然后加以利用)
顺便一提,费马大定理
费马大定理,又被称为“费马最后的定理”,由法国数学家费马提出。
它断言当整数n >2时,关于x, y, z的方程 x^n + y^n = z^n 没有正整数解。
被提出后,经历多人猜想辩证,历经三百多年的历史,最终在1995年被英国数学家安德鲁·怀尔斯证明。
费马平方和定理:
一个非负整数 c如果能够表示为两个整数的平方和,当且仅当 c 的所有形如 4k + 3 的质因子的幂均为偶数。
赛瓦维斯特定理 :
已知 a,b为大于1的正整数,gcd(a,b)=1,则使不定方程 ax+by=C无负数解的最大整数C=ab-a-b。
gcd定理:
贝祖定理:即如果a、b是整数,那么一定存在整数x、y使得ax+by=gcd(a,b)。
换句话说,如果ax+by=m有解,那么m一定是gcd(a,b)的若干倍。(可以来判断一个这样的式子有没有解)
有一个直接的应用就是 如果ax+by=1有解,那么gcd(a,b)=1
int exgcd(int a,int b,int &x,int &y)//扩展欧几里得算法
{
if(!b)
{
x=1;y=0;
return a; //到达递归边界开始向上一层返回
}
int r=exgcd(b,a%b,x,y);
int temp=y; //把x y变成上一层的
y=x-(a/b)*y;
x=temp;
return r; //得到a b的最大公因数
}
欧拉函数
欧拉函数,用φ(n)表示
欧拉函数是求小于等于n的数中与n互质的数的数目
φ(30)的计算方法就是先找30的质因数
分别是2,3,5
然后用30* 1/2 * 2/3 * 4/5就搞定了
//欧拉函数
int phi(int x){
int ans = x;
for(int i = 2; i*i <= x; i++){
if(x % i == 0){
ans = ans / i * (i-1);
while(x % i == 0) x /= i;
}
}
if(x > 1) ans = ans / x * (x-1);
return ans;
}复杂度是O(√n),如果要你求n个数的欧拉函数,复杂度是O(n√n),这也太慢了!
有更快的方法
跟埃筛素数差不多!
#include<cstdio>
const int N = 100000 + 5;
int phi[N];
void Euler(){
phi[1] = 1;
for(int i = 2; i < N; i ++){
if(!phi[i]){
for(int j = i; j < N; j += i){
if(!phi[j]) phi[j] = j;
phi[j] = phi[j] / i * (i-1);
}
}
}
}
int main(){
Euler();
}扩展欧几里德算法
ax+by = gcd(a, b) 这个公式肯定有解 (( •̀∀•́ )她说根据数论中的相关定理可以证明,反正我信了)
所以 ax+by = gcd(a, b) * k 也肯定有解 (废话,把x和y乘k倍就好了)
所以,这个公式我们写作ax+by = d,(gcd(a, b) | d)
gcd(a, b) | d,表示d能整除gcd,这个符号在数学上经常见!
那么已知 a,b 求 一组解 x,y 满足 ax+by = gcd(a, b) 这个公式!
#include<cstdio>
typedef long long LL;
void extend_Eulid(LL a, LL b, LL &x, LL &y, LL &d){
if (!b) {d = a, x = 1, y = 0;}
else{
extend_Eulid(b, a % b, y, x, d);
y -= x * (a / b);
}
}
int main(){
LL a, b, d, x, y;
while(~scanf("%lld%lld", &a, &b)){
extend_Eulid(a, b, x, y, d);
printf("%lld*a + %lld*b = %lld\n", x, y, d);
}
}逆元
数论倒数,又称逆元(因为我说习惯逆元了,下面我都说逆元)
数论中的倒数是有特别的意义滴
你以为a的倒数在数论中还是1/a吗
先来引入求余概念
(a + b) % p = (a%p + b%p) %p (对)
(a - b) % p = (a%p - b%p) %p (对)
(a * b) % p = (a%p * b%p) %p (对)
(a / b) % p = (a%p / b%p) %p (错)
为什么除法错的
证明是对的难,证明错的只要举一个反例
(100/50)%20 = 2 ≠ (100%20) / (50%20) %20 = 0
对于一些题目,我们必须在中间过程中进行求余,否则数字太大,电脑存不下,那如果这个算式中出现除法,我们是不是对这个算式就无法计算了呢?
答案当然是 NO (>o<)
这时就需要逆元了
我们知道
如果
a*x = 1
那么x是a的倒数,x = 1/a
但是a如果不是1,那么x就是小数
那数论中,大部分情况都有求余,所以现在问题变了
a*x = 1 (mod p)
那么x一定等于1/a吗
不一定
所以这时候,我们就把x看成a的倒数,只不过加了一个求余条件,所以x叫做 a关于p的逆元
比如2 * 3 % 5 = 1,那么3就是2关于5的逆元,或者说2和3关于5互为逆元
这里3的效果是不是跟1/2的效果一样,所以才叫数论倒数
a的逆元,我们用inv(a)来表示
那么(a / b) % p = (a * inv(b) ) % p = (a % p * inv(b) % p) % p
这样就把除法,完全转换为乘法了 (。・ω・),乘法超容易
逆元怎么求
(忘了说,a和p互质,a才有关于p的逆元)
方法一:
费马曾经说过:不想当数学家的数学家不是好数学家(( ̄▽ ̄)~*我随便说的,别当真)
费马小定理
a^(p-1) ≡1 (mod p)
两边同除以a
a^(p-2) ≡1/a (mod p)
什么(,,• ₃ •,,),这可是数论,还敢写1/a
应该写a^(p-2) ≡ inv(a) (mod p)
所以inv(a) = a^(p-2) (mod p)
这个用快速幂求一下,复杂度O(logn)(ง •̀_•́)ง
LL pow_mod(LL a, LL b, LL p){//a的b次方求余p
LL ret = 1;
while(b){
if(b & 1) ret = (ret * a) % p;
a = (a * a) % p;
b >>= 1;
}
return ret;
}
LL Fermat(LL a, LL p){//费马求a关于b的逆元
return pow_mod(a, p-2, p);
}方法二:
要用扩展欧几里德算法
还记得扩展欧几里德吗?(不记得的话,欧几里得会伤心的(╭ ̄3 ̄)╭♡)
a*x + b*y = 1
如果ab互质,有解
这个解的x就是a关于b的逆元
y就是b关于a的逆元
为什么呢?
你看,两边同时求余b
a*x % b + b*y % b = 1 % b
a*x % b = 1 % b
a*x = 1 (mod b)
你看你看,出现了!!!(/≥▽≤/)
所以x是a关于b的逆元
反之可证明y
附上代码:
#include<cstdio>
typedef long long LL;
void ex_gcd(LL a, LL b, LL &x, LL &y, LL &d){
if (!b) {d = a, x = 1, y = 0;}
else{
ex_gcd(b, a % b, y, x, d);
y -= x * (a / b);
}
}
LL inv(LL t, LL p){//如果不存在,返回-1
LL d, x, y;
ex_gcd(t, p, x, y, d);
return d == 1 ? (x % p + p) % p : -1;
}
int main(){
LL a, p;
while(~scanf("%lld%lld", &a, &p)){
printf("%lld\n", inv(a, p));
}
}方法三:
当p是个质数的时候有
inv(a) = (p - p / a) * inv(p % a) % p
这为啥是对的咩?
证明不想看的孩子可以跳过。。。( ̄0  ̄)
证明:
设x = p % a,y = p / a
于是有 x + y * a = p
(x + y * a) % p = 0
移项得 x % p = (-y) * a % p
x * inv(a) % p = (-y) % p
inv(a) = (p - y) * inv(x) % p
于是 inv(a) = (p - p / a) * inv(p % a) % p
然后一直递归到1为止,因为1的逆元就是1
#include<cstdio>
const int N = 200000 + 5;
const int MOD = (int)1e9 + 7;
int inv[N];
int init(){
inv[1] = 1;
for(int i = 2; i < N; i ++){
inv[i] = (MOD - MOD / i) * 1ll * inv[MOD % i] % MOD;
}
}
int main(){
init();
}代码:
#include<cstdio>
typedef long long LL;
LL inv(LL t, LL p) {//求t关于p的逆元,注意:t要小于p,最好传参前先把t%p一下
return t == 1 ? 1 : (p - p / t) * inv(p % t, p) % p;
}
int main(){
LL a, p;
while(~scanf("%lld%lld", &a, &p)){
printf("%lld\n", inv(a%p, p));
}
}这个方法不限于求单个逆元,比前两个好,它可以在O(n)的复杂度内算出n个数的逆元
递归就是上面的写法,加一个记忆性递归,就可以了
递推这么写
组合数
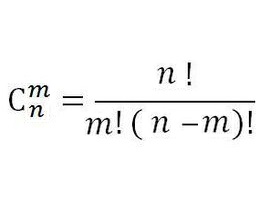
我们都学过组合数
会求组合数吗
一般我们用杨辉三角性质
杨辉三角上的每一个数字都等于它的左上方和右上方的和(除了边界)

第n行,第m个就是,就是C(n, m) (从0开始)
电脑上我们就开一个数组保存,像这样
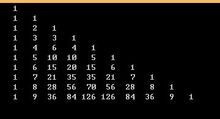
用递推求
#include<cstdio>
const int N = 2000 + 5;
const int MOD = (int)1e9 + 7;
int comb[N][N];//comb[n][m]就是C(n,m)
void init(){
for(int i = 0; i < N; i ++){
comb[i][0] = comb[i][i] = 1;
for(int j = 1; j < i; j ++){
comb[i][j] = comb[i-1][j] + comb[i-1][j-1];
comb[i][j] %= MOD;
}
}
}
int main(){
init();
}PS:大部分题目都要求求余,而且大部分都是对1e9+7这个数求余)
这种方法的复杂度是O(n^2),有没有O(n)的做法,当然有(´・ω・`)
因为大部分题都有求余,所以我们大可利用逆元的原理(没求余的题目,其实你也可以把MOD自己开的大一点,这样一样可以用逆元做)
根据这个公式
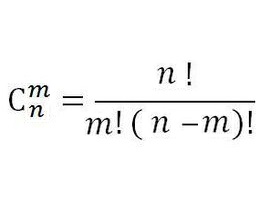
我们需要求阶乘和逆元阶乘
我们就用1e9+7来求余吧
代码如下
#include<cstdio>
const int N = 200000 + 5;
const int MOD = (int)1e9 + 7;
int F[N], Finv[N], inv[N];//F是阶乘,Finv是逆元的阶乘
void init(){
inv[1] = 1;
for(int i = 2; i < N; i ++){
inv[i] = (MOD - MOD / i) * 1ll * inv[MOD % i] % MOD;
}
F[0] = Finv[0] = 1;
for(int i = 1; i < N; i ++){
F[i] = F[i-1] * 1ll * i % MOD;
Finv[i] = Finv[i-1] * 1ll * inv[i] % MOD;
}
}
int comb(int n, int m){//comb(n, m)就是C(n, m)
if(m < 0 || m > n) return 0;
return F[n] * 1ll * Finv[n - m] % MOD * Finv[m] % MOD;
}
int main(){
init();
}中国剩余定理
中国剩余定理,又名孙子定理o(*≧▽≦)ツ
能求解什么问题呢?
问题:
一堆物品
3个3个分剩2个
5个5个分剩3个
7个7个分剩2个
问这个物品有多少个
解这题,我们需要构造一个答案
我们需要构造这个答案
5*7*inv(5*7, 3) % 3 = 1
3*7*inv(3*7, 5) % 5 = 1
3*5*inv(3*5, 7) % 7 = 1
这3个式子对不对,别告诉我逆元你忘了(*´∇`*),忘了的人请翻阅前几章复习
然后两边同乘你需要的数
2 * 5*7*inv(5*7, 3) % 3 = 2
3 * 3*7*inv(3*7, 5) % 5 = 3
2 * 3*5*inv(3*5, 7) % 7 = 2
令
a = 2 * 5*7*inv(5*7, 3)
b = 3 * 3*7*inv(3*7, 5)
c = 2 * 3*5*inv(3*5, 7)
那么
a % 3 = 2
b % 5 = 3
c % 7 = 2
其实答案就是a+b+c
因为
a%5 = a%7 = 0 因为a是5的倍数,也是7的倍数
b%3 = b%7 = 0 因为b是3的倍数,也是7的倍数
c%3 = c%5 = 0 因为c是3的倍数,也是5的倍数
所以
(a + b + c) % 3 = (a % 3) + (b % 3) + (c % 3) = 2 + 0 + 0 = 2
(a + b + c) % 5 = (a % 5) + (b % 5) + (c % 5) = 0 + 3 + 0 = 3
(a + b + c) % 7 = (a % 7) + (b % 7) + (c % 7) = 0 + 0 + 2 = 2
你看你看,答案是不是a+b+c(。・ω・)ノ゙,完全满足题意
但是答案,不只一个,有无穷个,每105个就是一个答案(105 = 3 * 5 * 7)
根据计算,答案等于233,233%105 = 23
如果题目问你最小的那个答案,那就是23了
以下抄自百度百科
中国剩余定理给出了以下的一元线性同余方程组:
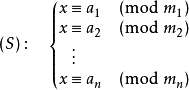
中国剩余定理说明:假设整数m1,m2, ... ,mn两两互质,则对任意的整数:a1,a2, ... ,an,
方程组(S)
有解,并且通解可以用如下方式构造得到:
设
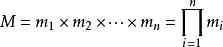
是整数m1,m2, ... ,mn的乘积,并设
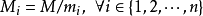
是除了mi以外的n- 1个整数的乘积。
设
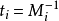
这个就是逆元了
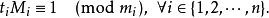
通解形式为
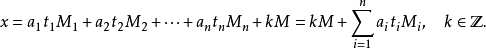
在模M的意义下,方程组(S)只有一个解:
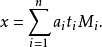
//n个方程:x=a[i](mod m[i]) (0<=i<n)
LL china(int n, LL *a, LL *m){
LL M = 1, ret = 0;
for(int i = 0; i < n; i ++) M *= m[i];
for(int i = 0; i < n; i ++){
LL w = M / m[i];
ret = (ret + w * inv(w, m[i]) * a[i]) % M;
}
return (ret + M) % M;
}卢卡斯定理
记得前几章的组合数吧

我们学了O(n^2)的做法,加上逆元,我们又会了O(n)的做法
现在来了新问题,如果n和m很大呢,
比如求C(n, m) % p , n<=1e18,m<=1e18,p<=1e5
看到没有,n和m这么大,但是p却很小,我们要利用这个p
(数论就是这么无聊的东西,我要是让n=1e100,m=1e100,p=1e100你有本事给我算啊(°□°),还不是一样算不出来)
然后,我们著名的卢卡斯(Lucas)在人群中站了出来(`・д・´)说:“让老子来教你这题”
卢卡斯说:
C(n, m) % p = C(n / p, m / p) * C(n%p, m%p) % p
对于C(n / p, m / p),如果n / p 还是很大,可以递归下去,一直到世界的尽头
众人闻此言,无不惊叹,妙哉!妙哉!
(笑死我了o(*≧▽≦)ツ┏━┓拍桌狂笑)
(不要问我证明过程,我不费(´・ω・`))
LL Lucas(LL n, LL m, int p){
return m ? Lucas(n/p, m/p, p) * comb(n%p, m%p, p) % p : 1;
}实战一下吧
hdu 5446
http://acm.hdu.edu.cn/showproblem.php?pid=5446
题意:
给你三个数n, m, k
第二行是k个数,p1,p2,p3...pk
所有p的值不相同且p都是质数
求C(n, m) % (p1*p2*p3*...*pk)的值
范围:1≤m≤n≤1e18,1≤k≤10,pi≤1e5,保证p1*p2*p3*...*pk≤1e18
#include<cstdio>
typedef long long LL;
const int N = 100000 + 5;
LL mul(LL a, LL b, LL p){//快速乘,计算a*b%p
LL ret = 0;
while(b){
if(b & 1) ret = (ret + a) % p;
a = (a + a) % p;
b >>= 1;
}
return ret;
}
LL fact(int n, LL p){//n的阶乘求余p
LL ret = 1;
for (int i = 1; i <= n ; i ++) ret = ret * i % p ;
return ret ;
}
void ex_gcd(LL a, LL b, LL &x, LL &y, LL &d){
if (!b) {d = a, x = 1, y = 0;}
else{
ex_gcd(b, a % b, y, x, d);
y -= x * (a / b);
}
}
LL inv(LL t, LL p){//如果不存在,返回-1
LL d, x, y;
ex_gcd(t, p, x, y, d);
return d == 1 ? (x % p + p) % p : -1;
}
LL comb(int n, int m, LL p){//C(n, m) % p
if (m < 0 || m > n) return 0;
return fact(n, p) * inv(fact(m, p), p) % p * inv(fact(n-m, p), p) % p;
}
LL Lucas(LL n, LL m, int p){
return m ? Lucas(n/p, m/p, p) * comb(n%p, m%p, p) % p : 1;
}
LL china(int n, LL *a, LL *m){//中国剩余定理
LL M = 1, ret = 0;
for(int i = 0; i < n; i ++) M *= m[i];
for(int i = 0; i < n; i ++){
LL w = M / m[i];
//ret = (ret + w * inv(w, m[i]) * a[i]) % M;//这句写了会WA,用下面那句
ret = (ret + mul(w * inv(w, m[i]), a[i], M)) % M;
//因为这里直接乘会爆long long ,所以我用快速乘(unsigned long long也是爆掉,除非用高精度)
}
return (ret + M) % M;
}
int main(){
int T, k;
LL n, m, p[15], r[15];
scanf("%d", &T);
while(T--){
scanf("%I64d%I64d%d", &n, &m, &k);
for(int i = 0; i < k; i ++){
scanf("%I64d", &p[i]);
r[i] = Lucas(n, m, p[i]);
}
printf("%I64d\n", china(k, r, p));
}
}我们知道题目要求C(n, m) % (p1*p2*p3*...*pk)的值
其实这个就是中国剩余定理最后算出结果后的最后一步求余
那C(n, m)相当于以前我们需要用中国剩余定理求的值
然而C(n, m)太大,我们只好先算出
C(n, m) % p1 = r1
C(n, m) % p2 = r2
C(n, m) % p3 = r3
.
.
.
C(n, m) % pk = rk
用Lucas,这些r1,r2,r3...rk可以算出来
然后又是用中国剩余定理求答案
全都是套路。。。
指数和对数:
c/c++语言中,关于指数,对数的函数我也就知道那么多
exp(),pow(),sqrt(),log(),log10(),
exp(x)就是计算e的x次方,sqrt(x)就是对x开根号
pow()函数可是十分强大的( ̄ε ̄)
pow(a, b)可以算a的b次方,但是b不限于整数,小数也可以
所以pow(x, 0.5)相当于sqrt(x)
pow(M_E, x)相当于exp(x) (M_E就是e)
poj 2109
http://poj.org/problem?id=2109
题目大意: K ^ N = P, 给N 和 P, 求K。数据规模 :1<=n<= 200, 1<=p<10101 而且保证存在 k, 1<=k<=109 。
正常不就是 二分+高精度算法 吗?
#include<cstdio>
#include<cmath>
double n, p;
int main(){
while(scanf("%lf%lf", &n, &p) != EOF){
printf("%.0f\n", pow(p, 1/n));
}
}哇哈哈,看到没有,看到没有,这就是技巧(*゚▽゚*)
double虽然精度只有16位左右,但是我们只要知道前16位就够了,后面任凭他用科学计数法去表示吧,反正我们不需要。
因为当n错一位,K的值前16位都会变化很大,所以这样计算出来的K肯定是唯一的
下面来说说对数:
C语言中,有两个log函数,分别为log和log10函数
log()是以e为底数的,数学上我们是写作ln(x)的
log10()是以10为底数的
那如果我想以2作为底数怎么办
这么写 log(x) / log(2) 数学公式,还记得吗<( ̄︶ ̄)>

定义类型:double log(double x);
double log10(double x);
当然我们一般用double的,它不只能接受double
double log (double x);
float log (float x);
long double log (long double x);
double log (T x); // additional overloads for integral types
最后一句模板T类型只有c++11支持,基本你不会自己去重载所以用不上
然后,从c++98开始,就支持 <complex> and <valarray>两个类型了
待会我会讲讲<complex>头文件,这是复数类
在比较a^b和c^d次方,如果b和d非常大怎么办
比如这题:hdu 5170
http://acm.hdu.edu.cn/showproblem.php?pid=5170
告诉你a,b,c,d,要你比较a^b和c^d,输出"<",">"或"="
1≤a,b,c,d≤1000
所以直接用log的性质
log(a^b) = b * log(a)
如果两边同时log一下再比较,那就方便多了(注意log有精度误差)
完整性质:
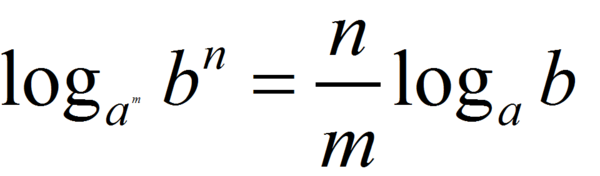
#include<cstdio>
#include<cmath>
int main(){
int a, b, c, d;
double l, r;
while(~scanf("%d%d%d%d", &a, &b, &c, &d)){
l = b * log(a);
r = d * log(c);
if(fabs(l - r) < 1e-6){//精度误差,一般小于0.000001可以认为相等
puts("=");
}else if(l < r){
puts("<");
}else{
puts(">");
}
}
}
//关于1e-6,有人写1e-7,1e-8,连1e-10都有,看喜好咯有没有想过遇到x^y^z怎么办
cf 621D
http://codeforces.com/problemset/problem/621/D
给你三个数x,y,z,比较这12个式子,问你哪个式子最大
0.1 ≤ x, y, z ≤ 200.0
x^(y^z)
这个式子log一下
变成
原式 = y^z*log(x)
再log一下变成
= log(y^z*log(x))
= log(y^z) + log(log(x))
= z * log(y) + log(log(x))
本来这样就可以比较了
可是题目的范围是0.1
log()小数会产生负数
log负数就没意义了
所以对于log(log(x))这么写不行
那怎么办
哼哼,技巧
double范围 -1.7*10(-308)~1.7*10(308)
long double范围 128 18-19 -1.2*10(-4932)~1.2*10(4932)
虽然他们两精度都是16位,但是200的200次方long double竟然存的下
所以只要一次log就好了
然后愉快的写代码吧
AC代码:
#include<cstdio>
#include<cmath>
#include<iostream>
using namespace std;
char str[12][10] = {
"x^y^z",
"x^z^y",
"(x^y)^z",
"(x^z)^y",
"y^x^z",
"y^z^x",
"(y^x)^z",
"(y^z)^x",
"z^x^y",
"z^y^x",
"(z^x)^y",
"(z^y)^x",
};
long double x, y, z;
long double mx, t;
int pos;
void judge(int x){
//printf("t = %llf\n", t);
if(fabs(mx - t) <= 1e-6) return ;
else if(mx < t){
pos = x;
mx = t;
}
}
int main(){
cin >> x >> y >> z;
pos = 0;
mx = pow(y, z)*log(x);
t = pow(z, y)*log(x);
judge(1);
t = z*log(pow(x, y));
judge(2);
t = y*log(pow(x, z));
judge(3);
t = pow(x, z)*log(y);
judge(4);
t = pow(z, x)*log(y);
judge(5);
t = z*log(pow(y, x));
judge(6);
t = x*log(pow(y, z));
judge(7);
t = pow(x, y)*log(z);
judge(8);
t = pow(y, x)*log(z);
judge(9);
t = y*log(pow(z, x));
judge(10);
t = x*log(pow(z, y));
judge(11);
printf("%s\n", str[pos]);
}其实log()一个负数是可以解的
还记得当年大明湖畔的欧拉公式吗
eiπ = -1
因为e的i∏次方等于-1
所以log(-1) = i∏
所以负数迎刃而解
log(-2) = log(-1 * 2) = log(-1) + log(2)
那log(i)呢
根号-1等于i
所以log(i) = log( -1^(1/2) ) = 1/2 * log(-1) = 1/2 * i∏
那log(a + bi)
欧拉原公式写作
eix = cosx + isinx
那么
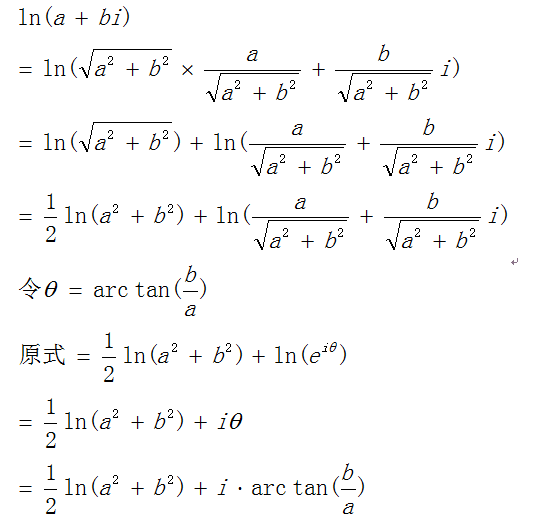
所以说嘛,年轻人就应该拿一本复变函数去看去(,,• ₃ •,,)
附上刚刚那题用复数计算的AC代码
#include <iostream>
#include <complex>
#include <string>
using namespace std;
bool bigger (complex<long double> a, complex<long double> b) {
if (imag(a) == 0 && imag(b) == 0) {//没有虚部
return real(a) > real(b);//比较实部
} else if (imag(a) == 0 && imag(b) != 0) { //有虚部的肯定小
return true;
} else if (imag(a) != 0 && imag(b) == 0) {
return false;
} else if (imag(a) != 0 && imag(b) != 0) {//都有虚部,按实部反过来比
return real(a) < real(b);
}
}
int main () {
long double ax, ay, az;
cin >> ax >> ay >> az;
complex<long double> x (ax, 0.0L);
complex<long double> y (ay, 0.0L);
complex<long double> z (az, 0.0L);
complex<long double> cmaz (3, 3);
string ans = "xd";
if (bigger(z * log(y) + log(log(x)), cmaz)) {
cmaz = z * log(y) + log(log(x));
ans = "x^y^z";
}
if (bigger(y * log(z) + log(log(x)), cmaz)) {
cmaz = y * log(z) + log(log(x));
ans = "x^z^y";
}
if (bigger(log(y * z) + log(log(x)), cmaz)) {
cmaz = log(y * z) + log(log(x));
ans = "(x^y)^z";
}
if (bigger(z * log(x) + log(log(y)), cmaz)) {
cmaz = z * log(x) + log(log(y));
ans = "y^x^z";
}
if (bigger(x * log(z) + log(log(y)), cmaz)) {
cmaz = x * log(z) + log(log(y));
ans = "y^z^x";
}
if (bigger(log(x * z) + log(log(y)), cmaz)) {
cmaz = log(x * z) + log(log(y));
ans = "(y^x)^z";
}
if (bigger(y * log(x) + log(log(z)), cmaz)) {
cmaz = y * log(x) + log(log(z));
ans = "z^x^y";
}
if (bigger(x * log(y) + log(log(z)), cmaz)) {
cmaz = x * log(y) + log(log(z));
ans = "z^y^x";
}
if (bigger(log(x * y) + log(log(z)), cmaz)) {
cmaz = log(x * y) + log(log(z));
ans = "(z^x)^y";
}
cout << ans << endl;
}康托展开:
在我们做题中,搜索也好,动态规划也好,我们往往有时候需要用一个数字表示一种状态
比如有8个灯泡排成一排,如果你用0和1表示灯泡的发光情况
那么一排灯泡就可以转换为一个二进制数字了
比如
01100110 = 102
11110000 = 240
10101010 = 170
通过这些十进制数,只要把他们展开,我们就知道灯泡的状态了
如果这题是一个动态规划题
然后我们就拿这些数字做一些转移了,
比如dp[102],dp[240],dp[170]等等
这对题目很有帮助
上面讲的那些就是所谓的状态压缩了,须知详细的状态压缩可以去百度
或者有机会我自己去写一篇博客(这是flag(/TДT)/)
那对于有些题,我们即使状态压缩后,数字太大,数组都开不下,麻烦的题目(/TДT)/
这些题目也要看情况,比如我接下来要讲的康托展开
康托展开经典题:hdu 1430
http://acm.hdu.edu.cn/showproblem.php?pid=1430
在魔方风靡全球之后不久,Rubik先生发明了它的简化版——魔板。魔板由8个同样大小的方块组成,每个方块颜色均不相同,可用数字1-8分别表示。任一时刻魔板的状态可用方块的颜色序列表示:从魔板的左上角开始,按顺时针方向依次写下各方块的颜色代号,所得到的数字序列即可表示此时魔板的状态。例如,序列(1,2,3,4,5,6,7,8)表示魔板状态为:
1 2 3 4
8 7 6 5
对于魔板,可施加三种不同的操作,具体操作方法如下:
A: 上下两行互换,如上图可变换为状态87654321
B: 每行同时循环右移一格,如上图可变换为41236785
C: 中间4个方块顺时针旋转一格,如上图可变换为17245368
给你魔板的初始状态与目标状态,请给出由初态到目态变换数最少的变换步骤,若有多种变换方案则取字典序最小的那种。
Input
每组测试数据包括两行,分别代表魔板的初态与目态。
Output
对每组测试数据输出满足题意的变换步骤。
Sample Input
12345678
17245368
12345678
82754631
Sample Output
C
AC
我们看这题,总共有8个数字,1~8,假如我们把他们看成0~7
那么每个数字可以转换为一个3位二进制
0:000
1:001
2:010
3:011
4:100
5:101
6:110
7:111
然后12345678这个状态我们可以表示为二进制000001010011100101110111,总共3*8=24位,
2^24 = 16777216,数组根本开不下啊
这时,我们发现了,有一些状态,根本没有用到,因为这题已经规定了有8个数字,每个数字只出现一次
比如000000000000000000000000这个状态,你说可能出现吗?(o ° ω ° O )
这个时候,康托就对这种题目做了研究(o ° ω ° O )
这种每个数字只出现一次的问题的所以情况,总共才n!个情况(这个问题叫做全排列)
康托的一套算法可以正好产生n!个数字
比如:
123 -> 0
132 -> 1
213 -> 2
231 -> 3
312 -> 4
321 -> 5
这是如何做到的(/≥▽≤/)
在峰神的博客里面有很好的解释(对不起了峰神≖‿≖✧,拿过来抄一下)


void cantor(int s[], LL num, int k){//康托展开,把一个数字num展开成一个数组s,k是数组长度
int t;
bool h[k];//0到k-1,表示是否出现过
memset(h, 0, sizeof(h));
for(int i = 0; i < k; i ++){
t = num / fac[k-i-1];
num = num % fac[k-i-1];
for(int j = 0, pos = 0; ; j ++, pos ++){
if(h[pos]) j --;
if(j == t){
h[pos] = true;
s[i] = pos + 1;
break;
}
}
}
}
void inv_cantor(int s[], LL &num, int k){//康托逆展开,把一个数组s换算成一个数字num
int cnt;
num = 0;
for(int i = 0; i < k; i ++){
cnt = 0;
for(int j = i + 1; j < k; j ++){
if(s[i] > s[j]) cnt ++;//判断几个数小于它
}
num += fac[k-i-1] * cnt;
}
}#include<cstdio>
#include<cstring>
#include<iostream>
#include<string>
#include<algorithm>
#include<queue>
using namespace std;
typedef long long LL;
const int N = 8;
queue <LL> que;
string ans[50000];
char str1[10], str2[10];
bool vis[50000];
int map[10];//映射
int num[10];
LL fac[N];//阶乘
void change(int s[], int o){//o分别是0,1,2,表示ABC三种变化
switch(o){
case 0:
for(int i = 0; i < 4; i ++) swap(s[i], s[8-i-1]);
break;
case 1:
for(int i = 3; i >= 1; i --) swap(s[i], s[i-1]);
for(int i = 4; i < 7; i ++) swap(s[i], s[i+1]);
break;
case 2:
swap(s[1], s[6]);
swap(s[6], s[5]);
swap(s[5], s[2]);
break;
}
}
void cantor(int s[], LL num, int k){//康托展开,把一个数字num展开成一个数组s,k是数组长度
int t;
bool h[k];//0到k-1,表示是否出现过
memset(h, 0, sizeof(h));
for(int i = 0; i < k; i ++){
t = num / fac[k-i-1];
num = num % fac[k-i-1];
for(int j = 0, pos = 0; ; j ++, pos ++){
if(h[pos]) j --;
if(j == t){
h[pos] = true;
s[i] = pos + 1;
break;
}
}
}
}
void inv_cantor(int s[], LL &num, int k){//康托逆展开,把一个数组s换算成一个数字num
int cnt;
num = 0;
for(int i = 0; i < k; i ++){
cnt = 0;
for(int j = i + 1; j < k; j ++){
if(s[i] > s[j]) cnt ++;//判断几个数小于它
}
num += fac[k-i-1] * cnt;
}
}
void init(){
fac[0] = 1;
for(int i = 1; i < N; i ++) fac[i] = fac[i-1] * i;
int a[8], b[8];
LL temp, temp2;
que.push(0);
vis[0] = true;
while(!que.empty()){
LL temp = que.front(); que.pop();
cantor(a, temp, 8);
for(int i = 0; i < 3; i ++){
copy(a, a+8, b);
change(b, i);
inv_cantor(b, temp2, 8);
if(!vis[temp2]){
que.push(temp2);
vis[temp2] = true;
ans[temp2] = ans[temp] + (char)('A' + i);
}
}
}
}
int main(){
init();
while(~scanf("%s", str1)){
scanf("%s", str2);
//先把所有初始状态都转换成12345678
//最终状态根据初始状态的转换而转换
//这样只要一次预处理就可以解决问题了
for(int i = 0; i < 8; i ++) map[str1[i] - '0'] = i + 1;
for(int i = 0; i < 8; i ++) num[i] = map[str2[i] - '0'];
LL temp;
inv_cantor(num, temp, 8);
cout << ans[temp] << endl;
}
}容斥原理
百度百科说:
在计数时,必须注意没有重复,没有遗漏。
为了使重叠部分不被重复计算,人们研究出一种新的计数方法。
这种方法的基本思想是:先不考虑重叠的情况,把包含于某内容中的所有对象的数目先计算出来,然后再把计数时重复计算的数目排斥出去,使得计算的结果既无遗漏又无重复。
这种计数的方法称为容斥原理。
好标准的说法(#-.-)
那我举个简单的例子
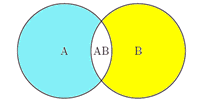
两个集合的容斥原理: 设A, B是两个有限集合
那么
|A + B| = |A| + |B| - |AB|
|A|表示A集合中的元素个数
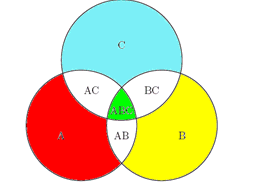
三个集合的容斥原理: 设A, B, C是三个有限集合
那么
|A + B + C| = |A| + |B| + |C| - |AB| - |AC| - |BC| + |ABC|
这就叫容斥原理
接下来直接做例题了
全错排(装错信封问题)
hdu 1465
http://acm.hdu.edu.cn/showproblem.php?pid=1465
n封信对应n个信封
求恰好全部装错了信封的方案数
本来全错排是有自己的一个公式的,叫全错排公式(跟容斥没关系)
那我顺便来讲讲全错排( >ω<)
要装第i封信的时候,先把前i-1个信全装错信封,然后随便选其中一个与第i封信交换,有i-1种选法
那么dp[i] = (i-1) * dp[i-1]
但是还有一种情况
要装第i封信的时候,先从i-1封信中任选i-2个信把他们全装错信封,然后把剩下的那个信与第i个交换,从i-1封信中任选i-2个信有i-1种选法
那么dp[i] = (i-1) * dp[i-2]
两个式子联合起来
就是那么dp[i] = (i-1) * (dp[i-1] + dp[i-2])
这就是全错排公式,递推,递归都可以做
#include<cstdio>
typedef long long LL;
int n;
LL dp[25];
void init(){
dp[1] = 0;
dp[2] = 1;
for(int i = 3; i <= 20; i ++){
dp[i] = (i-1) * (dp[i-1] + dp[i-2]);
}
}
int main(){
init();
while(~scanf("%d", &n)){
printf("%I64d\n", dp[n]);
}
}那么这题容斥怎么做呢?
首先,所有装信的总数是n!
(在n中任选一个信封放进一封信,然后在剩下的n-1中任选一个信封放进一封信,以此类推,所以是n*(n-1)*(n-2)... = n!)
假设
A1表示1封信装对信封,数量是(n-1)! (只有n-1个位置可以乱放)
A2表示2封信装对信封,数量是(n-2)! (只有n-2个位置可以乱放)
...
An表示n封信装对信封,数量是1
那么这题的答案就是
n! - C(n, 1)*|A1| + C(n, 2)*|A2| - C(n, 3)*|A3| + ... + (-1)^n * C(n, n)*|A4|
把C(n, m)用
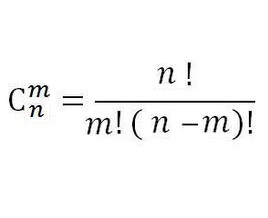
代入式子
化简
n! - n! / 1! + n! / 2! - n! / 3! + ... + (-1)^n * n! / n!
提取n!
n!(1 - 1/1! + 1/2! - 1/3! + ... + (-1)^n * 1/n!)
附上容斥AC代码:
#include<cstdio>
typedef long long LL;
int n, flag;
LL fac[25];
LL ans;
void init(){
fac[0] = 1;
for(int i = 1; i <= 20; i ++) fac[i] = fac[i-1] * i;
}
int main(){
init();
while(~scanf("%d", &n)){
ans = fac[n];
flag = -1;//容斥的符号变化
for(int i = 1; i <= n; i ++){
ans += flag * fac[n] / fac[i];
flag = -flag;
}
printf("%I64d\n", ans);
}
}第二例题:
UVALive 7040
https://icpcarchive.ecs.baylor.edu/index.php?option=com_onlinejudge&Itemid=8&page=show_problem&problem=5052
题意:给n盆花涂色,从m种颜色中选取k种颜色涂,保证正好用上k种颜色,你必须用上这k种颜色去涂满n个相邻的花,并且要求相邻花的颜色不同,求方案数。
(1 ≤ n, m ≤ 1e9 , 1 ≤ k ≤ 1e6 , k ≤ n, m)
首先,用k种颜色涂花,假如不考虑全部用上,那么总的方案数是多少
第一盆花有k种颜色选择,之后的花因为不能跟前一盆花的颜色相同,所以有k-1种选择
于是总方案数为k*(k-1)^(n-1)
因为题目问必须用上k种颜色
这里面包含了只用k-1种颜色的情况,应该减掉所有用k-1种的情况
减掉的东西里面,这里面包含了只用k-2种颜色的情况,应该加回来
...
反反复复,最后就得出答案了(这算是解释吗。。。)
最后答案就是
C(m,k) * ( k * (k-1)^(n-1) + [∑((-1)^i * C(k, k - i) * (k-i) * (k-i-1)^(n-1)) ] ) (1 <= i <= k-1) 红色表示容斥部分
(这里m有1e9,C(m, k)直接用for循环算,直接for循环从m*(m-1)*...*(m-k+1)再乘k的阶乘的逆元)
AC代码:
#include<cstdio>
typedef long long LL;
const int N = 1000000 + 5;
const int MOD = (int)1e9 + 7;
int F[N], Finv[N], inv[N];
LL pow_mod(LL a, LL b, LL p){
LL ret = 1;
while(b){
if(b & 1) ret = (ret * a) % p;
a = (a * a) % p;
b >>= 1;
}
return ret;
}
void init(){
inv[1] = 1;
for(int i = 2; i < N; i ++){
inv[i] = (MOD - MOD / i) * 1ll * inv[MOD % i] % MOD;
}
F[0] = Finv[0] = 1;
for(int i = 1; i < N; i ++){
F[i] = F[i-1] * 1ll * i % MOD;
Finv[i] = Finv[i-1] * 1ll * inv[i] % MOD;
}
}
int comb(int n, int m){
if(m < 0 || m > n) return 0;
return F[n] * 1ll * Finv[n - m] % MOD * Finv[m] % MOD;
}
int main(){
init();
int T, n, m, k, ans, flag, temp;
scanf("%d", &T);
for(int cas = 1; cas <= T; cas ++){
scanf("%d%d%d", &n, &m, &k);
ans = k * pow_mod(k-1, n-1, MOD) % MOD;
flag = -1;
//计算容斥
for(int i = 1; i <= k-1; i ++){
ans = (ans + 1ll * flag * comb(k, k-i) * (k-i) % MOD * pow_mod((k-i-1), n-1, MOD) % MOD) % MOD;
flag = -flag;
}
//接下来计算C(m, k)
temp = Finv[k];
for(int i = 1; i <= k; i ++){
temp = 1ll * temp * (m-k+i) % MOD;
}
ans = ((1ll * ans * temp) % MOD + MOD) % MOD;
printf("Case #%d: %d\n", cas, ans);
}
} 抽屉原理
有366人,那么至少有两人同一天出生(好孩子就不要在意闰年啦( ̄▽ ̄"))
有13人,那么至少有两人同一月出生
这就是抽屉原理
抽屉原理:把n+1个物品放到n个抽屉里,那么至少有两个物品在同一个抽屉里
鸽巢原理:把n+1个鸽子放到n个鸽巢里,那么至少有两个鸽子在同一个鸽巢里
球盒原理:把n+1个小球放到n个球盒里,那么至少有两个小球在同一个球盒里
(你看,我都帮你们解释里一遍(≧︶≦*))
其实抽屉原理有两个
第一抽屉原理
原理1: 把多于n+k个的物体放到n个抽屉里,则至少有一个抽屉里的东西不少于两件。
原理2 :把多于mn(m乘以n)+1(n不为0)个的物体放到n个抽屉里,则至少有一个抽屉里有不少于(m+1)的物体。
原理3 :把无穷多件物体放入n个抽屉,则至少有一个抽屉里 有无穷个物体。
原理1 、2 、3都是第一抽屉原理的表述。
第二抽屉原理
把(mn-1)个物体放入n个抽屉中,其中必有一个抽屉中至多有(m—1)个物体(例如,将3×5-1=14个物体放入5个抽屉中,则必定有一个抽屉中的物体数少于等于3-1=2)。
原理懂了,但是你会运用吗?
来看这一题
cf 577B
http://codeforces.com/problemset/problem/577/B
Modulo Sum
给你一个序列a1,a2...an,再给你一个数字m
问你能不能从中选出几个数,把他们相加,令这个和能够整除m
能就是输出YES,不能就输出NO
不知道你有木有思路(O ° ω ° O )
正常讲肯定是dp咯,加一点剪枝,勉强卡过了(因为CF上面都是单组数据,多组可能就超时了)
AC代码:
const int MAX=1e6+5;
int dp[1005][1005];
int a[MAX];
int main(){
int n,m;
cin>>n>>m;
for(int i=1;i<=n;i++){
cin>>a[i];
}
dp[0][0]=1;
if(n>m){
cout<<"YES"<<endl;
return 0;
}
int flag=0;
for(int i=1;i<=n;i++){
for(int j=0;j<m;j++){
int temp=((j-a[i])%m+m)%m;
if(dp[i-1][temp]){
dp[i][j]=1;
if(j==0){
flag=1;
}
}
if(dp[i-1][j]){
dp[i][j]=1;
}
}
}
if(flag) cout<<"YES";
else cout<<"NO";
}
生成器函数:
前排出售零食瓜子)
前言:
母函数是个很难的东西,难在数学
而ACM中所用的母函数只是母函数的基础
应该说除了不好理解外,其他都是非常简单的
母函数即生成函数,是组合数学中尤其是计数方面的一个重要理论和工具。
但是ACM中的母函数木有像数学那么深究,应用的都是母函数的一些基本
(就好比方程的配方,因式的分解,写起来容易,你用电脑写起来就麻烦了,所以学计算机就不要老跟数学家瞎闹( ̄3 ̄))
什么是母函数
就是把一个已知的序列和x的多项式合并起来,新产生的多项式就叫原来序列的母函数
至于怎么合并,看这个例子
序列{0,1,2,3,4,5...n}的母函数就是
f(x)=0+x+2x^2+3x^3+4x^4+...+nx^n(这个x没有任何意义,应该说,你不需要把它当做一个函数,你只要知道母函数这么写就可以了)
序列{1,1,1,1,1......}的母函数就是
f(x)=1+x+x^2+x^3+x^4....
二项式展开的序列比如这个{1,4,6,4,1,0,0,0,0,0.....}是C(4,0)到C(4,4)的系数,那它的母函数就是
f(x)=1+4x+6x^2+4x^3+1x^4
母函数就长这样,对正常人来讲,这种东西毫无意义( ° △ °|||)
那看点有意义的东西(以下都是经典题型,我从杭电ACM课件抄来的)
有1克、2克、3克、4克的砝码各一枚,能称出哪几种重量?每种重量各有几种可能方案?
假如x的幂次数表示几克的砝码
那么
1克的砝码表示为1+x^1
2克的砝码表示为1+x^2
3克的砝码表示为1+x^3
4克的砝码表示为1+x^4
每个砝码都可以选择取或不取
所以这里的1可以认为1*x^0,表示不取这颗砝码
那么把这些乘起来
(1+x^1)(1+x^2)(1+x^3)(1+x^4)
=1+(x^1)+(x^2)+2(x^3)+2(x^4)+2(x^5)+2(x^6)+2(x^7)+(x^8)+(x^9)+(x^10)
根据指数来看,我们可以称出0~10这么多的重量,其中3~7的系数为2,说明有2种称的方法
那么我们来细看一遍
0:(什么砝码都不放).......................(1种)
1:1.............................................(1种)
2:2.............................................(1种)
3:3或1+2.....................................(2种)
4:4或1+3.....................................(2种)
5:1+4或2+3.................................(2种)
6:2+4或1+2+3..............................(2种)
7:3+4或1+2+4..............................(2种)
8:1+3+4......................................(1种)
9:2+3+4......................................(1种)
10:1+2+3+4.................................(1种)
分毫不差(・ˍ・*)
所以说母函数在ACM就是这么用的,跟函数没关系,跟写法有关系。。。
再来一题
求用1分、2分、3分的邮票贴出不同数值的方案数:(每张邮票的数量是无限的)
那么
1分:(1+x^1+x^2+x^3+x^4+......)
2分:(1+x^2+x^4+x^6+x^8+......)
3分:(1+x^3+x^6+x^9+x^12+......)
然后这3个乘起来(让电脑去乘吧)
对于这种无限的,题目肯定会给你他询问的数值的范围,计算到最大的范围就可以了
附代码:
#include<cstdio>
typedef long long LL;
const int N = 100 + 5;//假如题目只问到100为止
const int MAX = 3;//题目只有1,2,3这3种邮票
LL c1[N], c2[N];//c2是临时合并的多项式,c1是最终合并的多项式
int n;
void init(){
c1[0] = 1;//一开始0的情况算一种
for(int i = 1; i <= MAX; i ++){//把1分到MAXN的邮票合并,变成一个多项式
for(int j = 0; j < N; j += i){//i分的邮票,步长是i
for(int k = 0; j + k < N; k ++){//从x^0到x^N遍历一遍
c2[j + k] += c1[k];//因为j的所有项系数为1,所以c1[k]可以看成c1[k]*1;
}
}
for(int j = 0; j < N; j ++){//把c2的数据抄到c1,清空c2
c1[j] = c2[j];
c2[j] = 0;
}
}
}
int main(){
init();
while(scanf("%d", &n) != EOF){
printf("%I64d\n", c1[n]);
}
}我们就来把这个模板用于实际吧
hdu 1028
http://acm.hdu.edu.cn/showproblem.php?pid=1028
题目问一个数字n能够拆成多少种数字的和
比如n=4
4 = 4;
4 = 3 + 1;
4 = 2 + 2;
4 = 2 + 1 + 1;
4 = 1 + 1 + 1 + 1;
有5种,那么答案就是5
AC代码:
#include<cstdio>
typedef long long LL;
const int N = 120 + 5;
const int MAX = 120 + 5;
LL c1[N], c2[N];
int n;
void init(){
c1[0] = 1;
for(int i = 1; i <= MAX; i ++){
for(int j = 0; j < N; j += i){
for(int k = 0; j + k < N; k ++){
c2[j + k] += c1[k];
}
}
for(int j = 0; j < N; j ++){
c1[j] = c2[j];
c2[j] = 0;
}
}
}
int main(){
init();
while(scanf("%d", &n) != EOF){
printf("%I64d\n", c1[n]);
}
}再来,hdu 1398
http://acm.hdu.edu.cn/showproblem.php?pid=1398
题目说一个国家的硬币都是方形的,面值也是方形的
有1块钱,4块钱,9块钱,16块钱......一直到289块钱(17^2)
问想组成n块钱有几种方法
AC代码
#include<cstdio>
typedef long long LL;
const int N = 300 + 5;
const int MAX = 17;
LL c1[N], c2[N];
int n;
void init(){
c1[0] = 1;
for(int i = 1; i <= MAX; i ++){
for(int j = 0; j < N; j += i*i){
for(int k = 0; j + k < N; k ++){
c2[j + k] += c1[k];
}
}
for(int j = 0; j < N; j ++){
c1[j] = c2[j];
c2[j] = 0;
}
}
}
int main(){
init();
while(scanf("%d", &n) != EOF && n){
printf("%I64d\n", c1[n]);
}
}都是改一些小地方,都是模板题(o゚ω゚o)
最后一道
hdu 1085
http://acm.hdu.edu.cn/showproblem.php?pid=1085
AC代码:
#include<cstdio>
#include<cstring>
typedef long long LL;
const int N = 1000 * (1+2+5) + 5;
int cost[3] = {1, 2, 5};
LL c1[N], c2[N];
int num[3];
int MAX;
int main(){
while(~scanf("%d%d%d", &num[0], &num[1], &num[2])){
if(num[0] == 0 && num[1] == 0 && num[2] == 0) break;
memset(c1, 0, sizeof(c1));
memset(c2, 0, sizeof(c2));
MAX = num[0] + num[1] * 2 + num[2] * 5;//计算最大值
c1[0] = 1;
for(int i = 0; i < 3; i ++){
for(int j = 0; j <= num[i] * cost[i]; j += cost[i]){
for(int k = 0; j + k <= MAX; k ++){
c2[j + k] += c1[k];
}
}
for(int j = 0; j < N; j ++){
c1[j] = c2[j];
c2[j] = 0;
}
}
for(int i = 1; i <= MAX + 1; i ++){
if(!c1[i]){
printf("%d\n", i);
break;
}
}
}
}反演定理
终于讲到反演定理了,反演定理这种东西记一下公式就好了,反正我是证明不出来的~(~o ̄▽ ̄)~o
首先,著名的反演公式
我先简单的写一下o( ̄ヘ ̄*o)
比如下面这个公式
f(n) = g(1) + g(2) + g(3) + ... + g(n)
如果你知道g(x),蓝后你就可以知道f(n)了
如果我知道f(x),我想求g(n)怎么办
这个时候,就有反演定理了
反演定理可以轻松的把上面的公式变为
g(n) = f(1) + f(2) + f(3) + ... + f(n)
当然,我写的只是个形式,怎么可能这么简单。◕‿◕。
其实每一项再乘一个未知的函数就对了,但是这个函数我们不知道(不用担心,数学家已经帮我们解决了,我们直接用就可以了)
反演公式登场( >ω<)
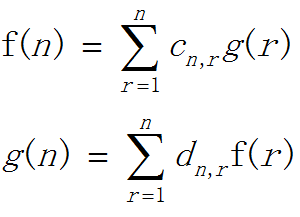
c和d是两个跟n和r有关的函数
根据用法不同,c和d是不同的
一般数学家会先随便弄c函数
然后经过复杂的计算和证明,得到d函数
然后公式就可以套用了
正片开始
二项式反演公式
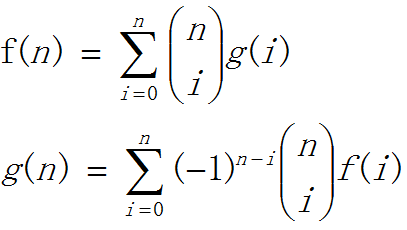
那个括号起来的就是组合数,我记得组合数那章我有说过

二项式反演也就是记住这个公式就算结束了
然后我们开始实战(/ω\)
容斥那章讲过的全错排(装错信封问题)
hdu 1465
http://acm.hdu.edu.cn/showproblem.php?pid=1465
设g(i)表示正好有i封信装错信封
那么全部的C(n, i)*g(i)加起来正好就是所有装信的情况,总共n!种情况
n! = Σ C(n, i)*g(i) (i从0到n)
那么f(n) = n!,所以f(x) = x!
那么我们要求g(n)
根据公式
g(n) = Σ (-1)^(n-i) * C(n, i) * f(i) (i从0到n)
那么就可以计算啦~\(≧▽≦)/~
AC代码: