导入requests库
import requests
get方法
url="https://www.baidu.com/"
head={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"
}
response=requests.get(url,headers=head) #得到一个回应
print(response)
运行结果:

说明响应成功
print(response.text)#拿到页面源代码
print(response.request) #拿到页面请求方法
print(response.url) #拿到页面网址
print(response.cookies)#拿到页面cookies值
print(response.headers)#拿到页面头部信息
print(response.content.decode("utf-8"))#拿到页面源代码
post方法
以百度翻译为例
先抓包获取所需要的内容
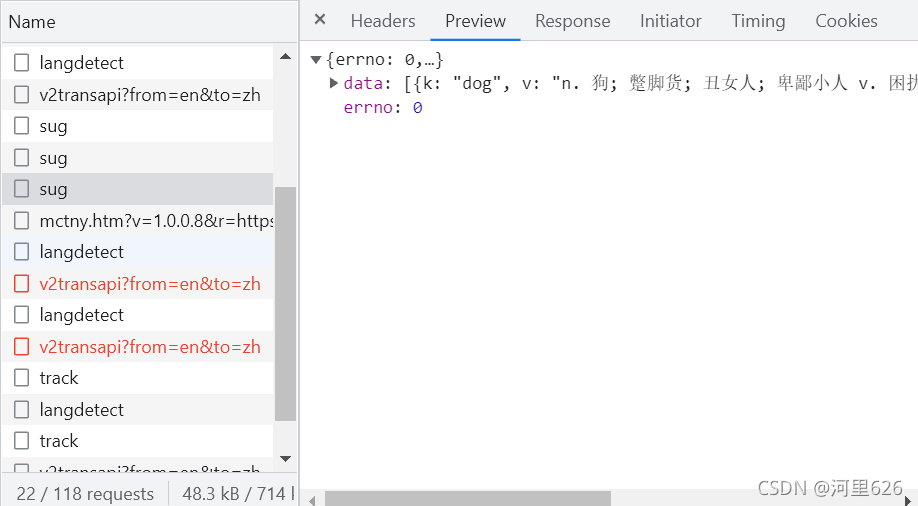
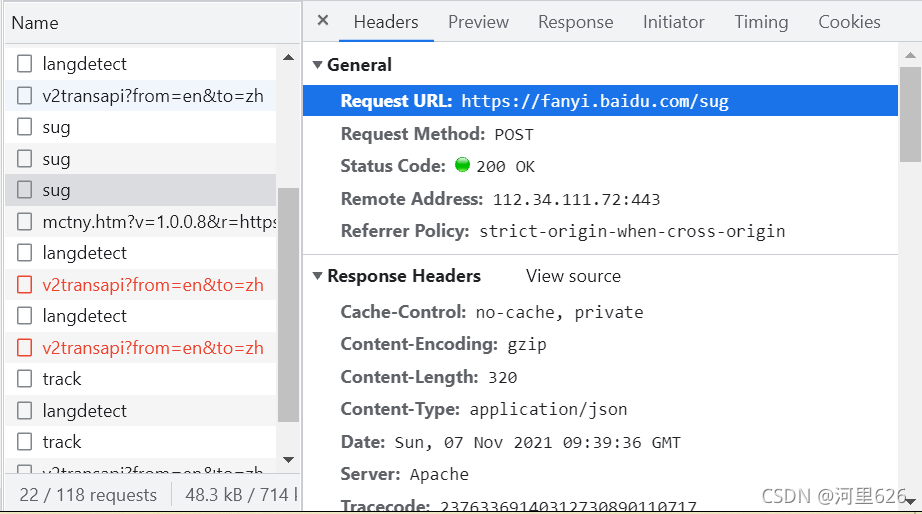
然后得到其url
head={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"
}
url="https://fanyi.baidu.com/sug"
value=input("输入你想翻译的内容")
data={
"kw": value
}
# #发送post请求,内容必须保存在字典内,通过data参数进行传递
response=requests.post(url,data=data,headers=head)
print(response.json())#将服务器返回内容转换成json()==》字典{}
print(response.request)
其中data根据网页的from data来编写
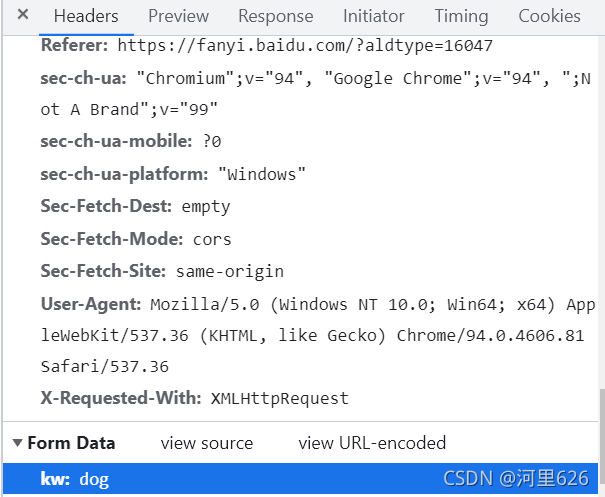
运行结果为:
