今天介绍如何爬取奇安信认证培训平台上已经购买的视频课程。
环境
- windows 7 x64
- python2.7.16
- Firefox开发版
- vscode 编辑器
- 依赖库 requests,bs4,js2py
总体思路
1. 打开页面 完成登陆鉴权
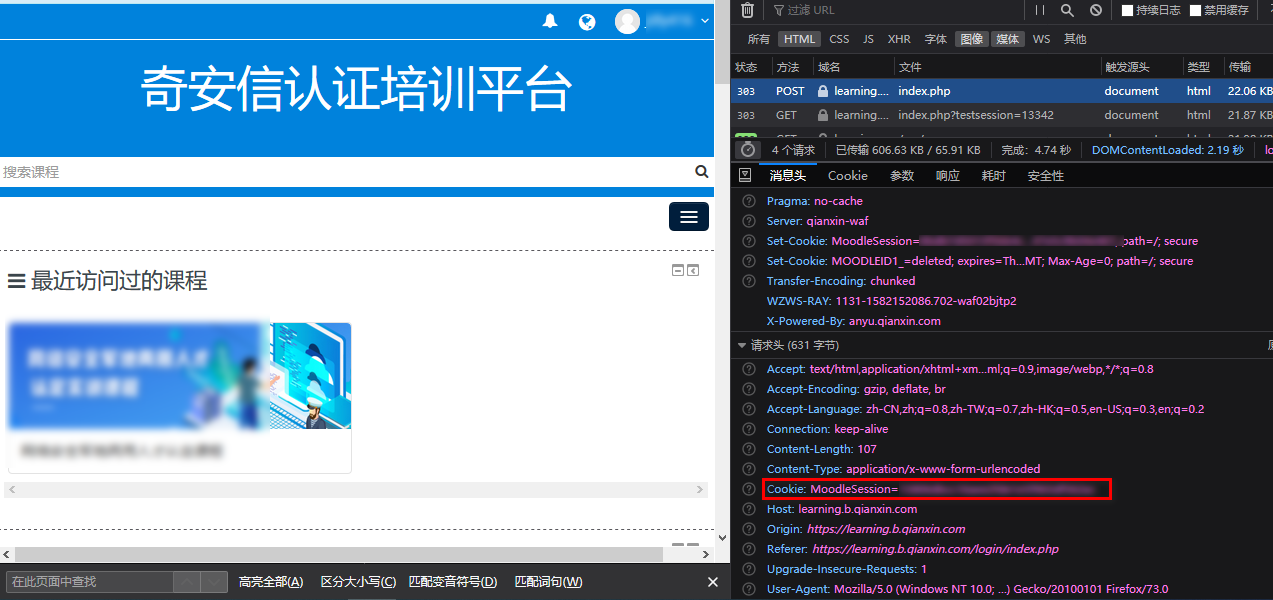
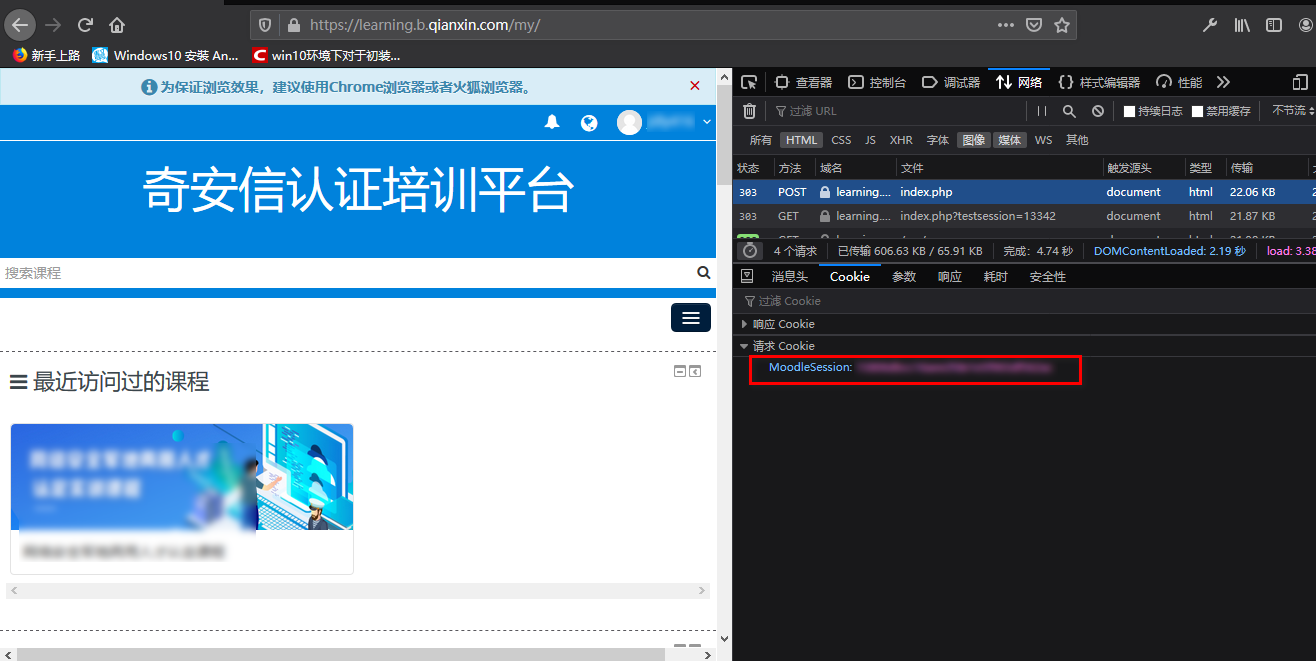
登陆鉴权我们使用了浏览器中的cookie, 这些信息可以从浏览器中拷贝,cookie信息在模拟登陆中会用到
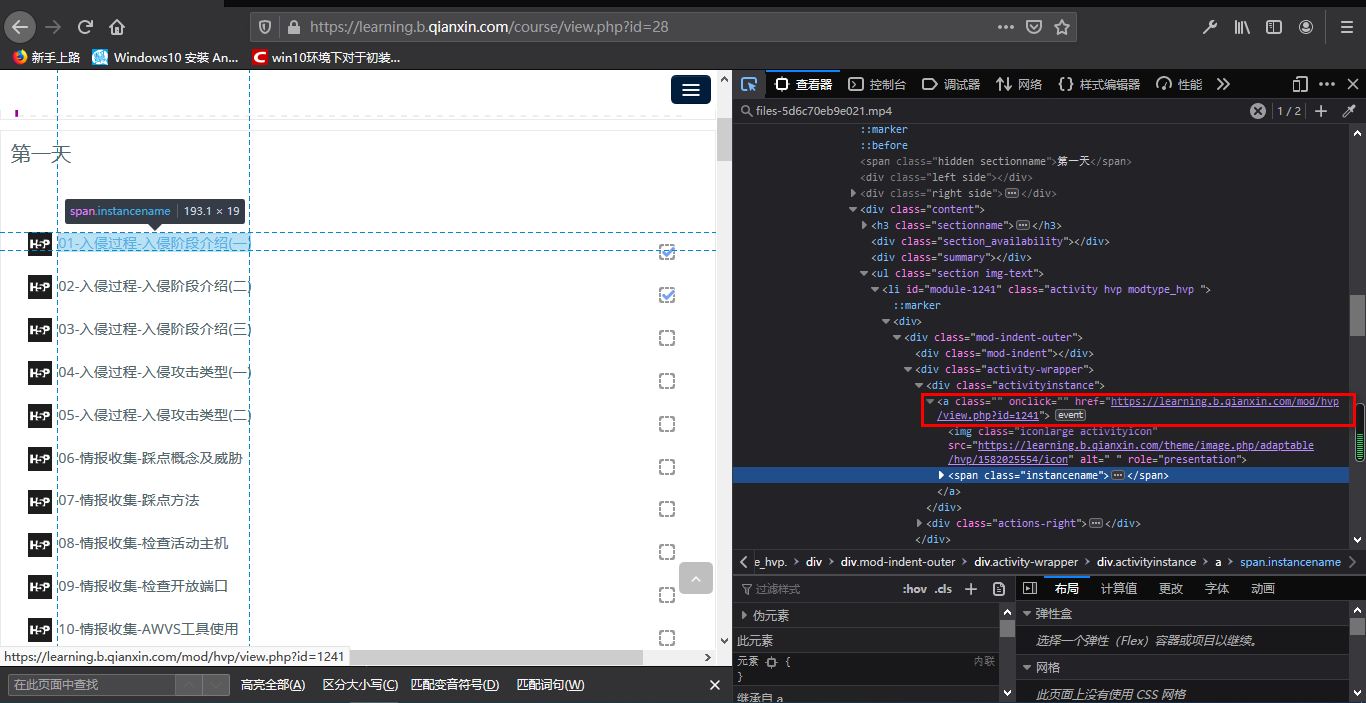
2. 从课程页面中提取出课时的url和title
课程页面中的课时列表,利用bs4库可以轻松提取这些课时的url和title
3. 从课时页面中提取出视频的下载url,下载视频保存到本地
用浏览器打开课时页面,会正常播放视频,但是用requests请求页面,返回的html文档不含有视频的播放地址。分析发现,页面使用js加载了一个视频播放控件,在js中生成视频的播放地址。
在html文档的25行有一个H5PIntegration变量,存储有视频的播放参数。

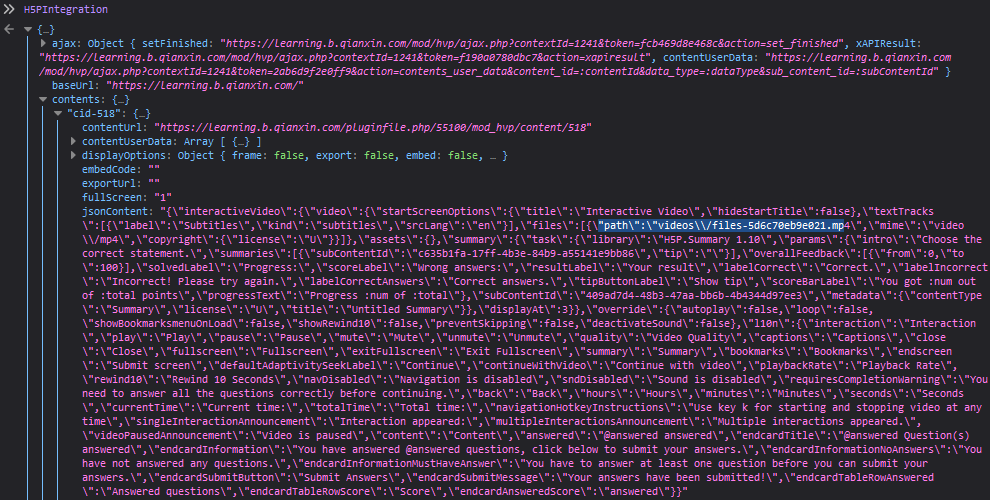
使用js2py可以在python代码中运行js代码。通过这个库可以得到H5PIntegration变量的值。
代码实现
#-*- coding:utf-8 -*-
#writen by wlj @2020-2-20 13:52:33
import json
import js2py
import requests,re,os
from requests.packages import urllib3
urllib3.disable_warnings()
from bs4 import BeautifulSoup
#全局变量
#http headers
cookie_str = 'xxxx'
#使用用户名和密码登陆后,在浏览器的console中输入document.cookie复制即可
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0',
'Referer':'https://learning.b.qianxin.com/my/',
'Cookie':'MoodleSession=%s' % cookie_str
}
cookies = {"MoodleSession":cookie_str}
#requests的会话对象
s = requests.Session()
#根据视频页面的url将视频保存为指定文件
def download_video(url,filename):
r= s.get(url,headers=headers,verify=False,cookies=cookies)
if r.status_code == 200:
#找到页面中这一段js代码,里面有视频url信息
a = re.findall(r'(var H5PIntegration = .*?;)',r.text)
#使用js2py库来加载这段js,并输入变量H5PIntegration
H5PIntegration = js2py.eval_js(a[0]+'H5PIntegration')
#得到视频的url前缀
key=''
prefix = ''
for k in H5PIntegration['contents']:
if k.startswith('cid'):
key = k
prefix = H5PIntegration['contents'][k]['contentUrl']
break
#得到视频的路径
jsonContent = H5PIntegration['contents'][key]['jsonContent']
path = json.loads(jsonContent)['interactiveVideo']['video']['files'][0]['path']
#拼接成完整的url
video_url = str(prefix)+'/'+path
print(video_url)
#视频的播放地址如 'https://learning.b.qianxin.com/pluginfile.php/55100/mod_hvp/content/518/videos/files-5d6c70eb9e021.mp4'
#下载视频文件
res1 = s.get(url = video_url, headers=headers,stream=True,verify=False)
with open(filename, "wb") as f:
for chunk in res1.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
print(filename,'downloaded!')
#爬虫主函数
def main():
#课程的url
url = 'https://learning.b.qianxin.com/course/view.php?id=28'
r = s.get(url,headers=headers,verify=False)
if r.status_code == 200:
#利用bs4库从页面html文档中解析出课程各课时的title和url
soup = BeautifulSoup(r.text,'lxml')
for li in soup.find_all('li',class_=['section', 'main', 'clearfix'])[1:-1]:
#课程的章节名称,如“第一天”
chapter_name = li['aria-label'].strip()
#构造课程的保存路径
dir_path = 'data\\%s' % chapter_name
#不存在的话,将其创建
if not os.path.isdir(dir_path):
os.makedirs(dir_path)
print(chapter_name)
#提取本章节中所有的课时的title和url
for a in li.ul.find_all('a'):
#课时页面的url
href = a['href']
#课时的title
title = a.text.strip().split(' ')[0]
#print(title)
#print(href)
#构造文件名,去掉不合法的字符
illege_chars = ['<','>','/','\\','|',':','"','*','?']
for char in illege_chars:
title = title.replace(char,'_')
#视频最终的文件名
filename = dir_path + os.sep + title + '.mp4'
#print(filename)
#若该视频没被下载,将其下载到本地
if not os.path.isfile(filename):
download_video(href,filename)
main()
脚本使用方法
首先打开Firefox,使用合法的用户名和密码登陆网站(https://learning.b.qianxin.com)后,打开开发者工具的console选项卡,输入document.cookie即可获取到用户的cookie,将其中的MoodleSession的值赋值给脚本中的cookie_str变量,运行脚本即可下载课程了。
结果