一、底图(geotiff)与瓦片(png)
瓦片地图的大小一般是256*256像素,文件格式一般是png,同一级中的所有瓦片地图拼接起来得到这一级的地图,png格式的地图不含地理信息,需要将该地图转换成包含地理信息的geotiff格式(也称tiff或tif)
geotiff的地理信息一般包括projection(投影坐标系,常用的是EPSG:4326和EPSG:3857)和地图范围(EPSG:4326对应的是经纬度的最大最小值,EPSG:3857对应的是横纵坐标的最大最小值)
二、国内底图市场现状
相信很多giser在获取底图的时候都会第一时间想到免费的地图下载器,国内比较知名的地图下载器有太乐地图、水经微图、Bigemap。无一例外,他们在早期开拓市场的时候,都能提供很多免费的地图下载。但现在想要获取免费地图,他们提供的条件都很苛刻,太乐地图每周二下午3点发放许可,逾期不候,激活后也仅能下载高德地图。
由于市面上免费的地图几乎都是有偏移的,tiff格式的地图在arcgis中纠偏,不仅有平移还会有旋转,因为tiff格式的地图本质上是一张图片,旋转的结果注定导致地图上的文字标注模糊,所以一般地图纠偏仅适合shapefile格式的矢量地图。
这就导致了一个困局,如果你底图之上的其他地图是无偏的,那么想让这些地图和底图完美匹配,必须要保证底图是无偏的,但是市面上没有免费的无偏底图,免费的有偏底图纠偏后文字标注又会模糊。想打破这个困局,你就必须要在这些地图下载器里开通vip,才能下载到你需要的无偏底图。
而我选择了另一条路:天地图
天地图是国家背书的无偏地图,天地图的官网提供了开发者入口,注册后可以申请tk,通过tk可以获得在线天地图瓦片服务,但不提供地图下载方式。国内这些地图下载器开通vip后都可以下载天地图。于是我也想通过爬虫的方式获取天地图。
开工前我先去GitHub上搜索了一下,确实有挺多人做过相关的工作,但是很多年代都比较久远了,找了很久都没有找到满意的开源项目。结合了下面这个下载谷歌影像地图的开源项目,我写了一个爬取速度还ok的天地图瓦片下载demo。
 https://github.com/cutecore/google_map_satellite_download
https://github.com/cutecore/google_map_satellite_download三、调用天地图服务
一般情况下,能使用在线地图,没人会使用本地地图。这里提供一个调用天地图在线地图的demo,详见
Openlayers在线调用天地图服务_ 一只博客-CSDN博客![]() https://blog.csdn.net/qq_42276781/article/details/121380342由于几乎所有在线地图,包括天地图都使用的是EPSG:3857,EPSG:4326的经纬度范围需要换算到EPSG:3857的横纵坐标范围,这里的经度范围是110°E-118°E,纬度范围30°S-34.5°S(下同)
https://blog.csdn.net/qq_42276781/article/details/121380342由于几乎所有在线地图,包括天地图都使用的是EPSG:3857,EPSG:4326的经纬度范围需要换算到EPSG:3857的横纵坐标范围,这里的经度范围是110°E-118°E,纬度范围30°S-34.5°S(下同)
转换到横纵坐标之后变成[12245143.987260092,13135699.91360628]和[3503549.8435043739, 4096139.0404472323],EPSG:3857和EPSG:4326的互转方法我之前有些,详见
C语言实现EPSG:4326和EPSG:3857的互转_ 一只博客-CSDN博客![]() https://blog.csdn.net/qq_42276781/article/details/120515458
https://blog.csdn.net/qq_42276781/article/details/120515458
四、代码部分
天地图官网增加了很多反爬机制,很多旧的代码不能拿来就用,一方面是因为天地图服务的网址变更了,另一方面就是因为天地图的反爬机制。
requests请求中的headers必须要包含Cookie,没有Cookie或Cookie不对,都不能正确访问天地图服务,更不必说下载瓦片了。
这里我提供一个测试网址
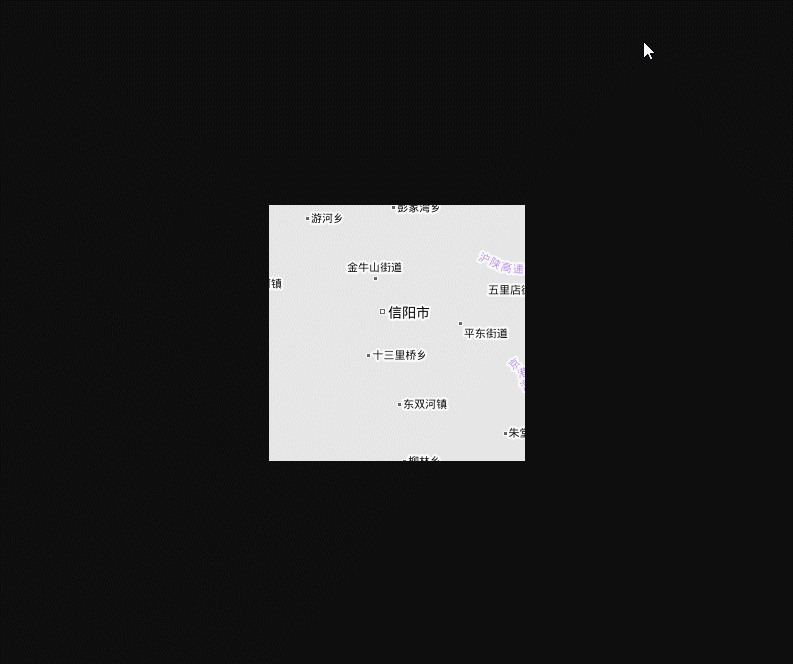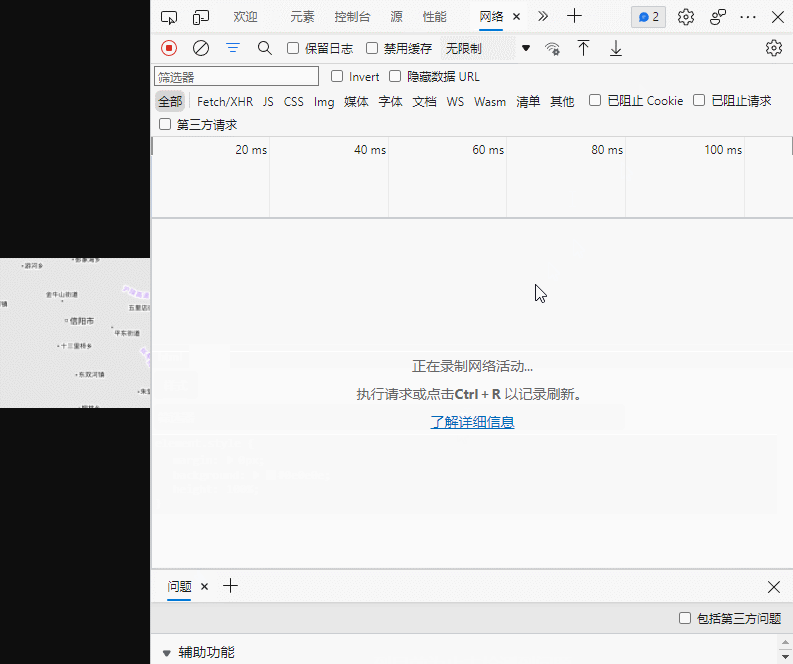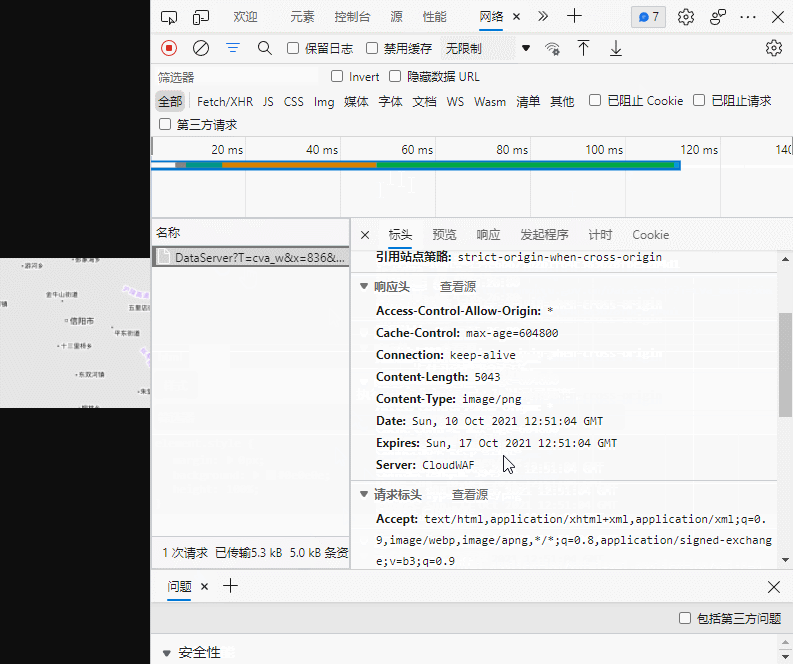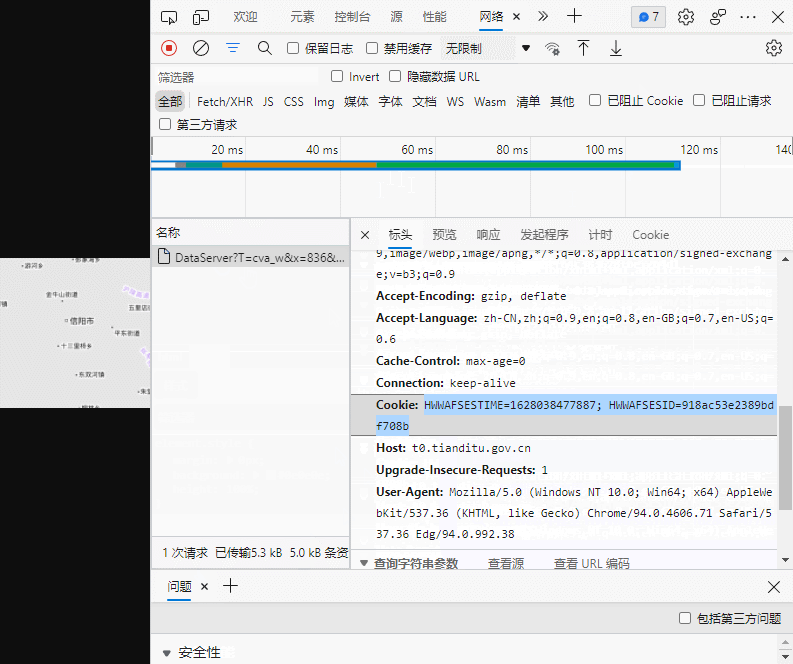
DataServer (256×256) (tianditu.gov.cn)![]() http://t0.tianditu.gov.cn/DataServer?T=cva_w&x=836&y=415&l=10&tk=134e6b671b2b1f64c383628fbe12b4d1进入该网址后,进行如下操作(点击网络后按Ctrl+R),获得你的Cookie,并在下面代码的第15行进行替换。
http://t0.tianditu.gov.cn/DataServer?T=cva_w&x=836&y=415&l=10&tk=134e6b671b2b1f64c383628fbe12b4d1进入该网址后,进行如下操作(点击网络后按Ctrl+R),获得你的Cookie,并在下面代码的第15行进行替换。
import requests
import numpy as np
from tqdm import tqdm
import cv2
import math
import os
# vec_w 街道, cva_w 注记
type1 = "vec_w"
type2 = "cva_w"
tk = "134e6b671b2b1f64c383628fbe12b4d1"
headers = {
'Host': "t0.tianditu.gov.cn",
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47",
'Cookie': "HWWAFSESTIME=1628038477818; HWWAFSESID=9418b1fc417688635e4"
}
# 下载单张地图到内存中
def downloadOne(type, x, y, z):
url = "http://t1.tianditu.gov.cn/DataServer?T={type}&x={x}&y={y}&l={z}&tk={tk}".format(type=type, x=x, y=y, z=z, tk=tk)
response = requests.get(url, headers=headers, timeout=10)
img = np.asarray(bytearray(response.content), dtype="uint8")
return cv2.imdecode(img, cv2.IMREAD_COLOR)
# 下载前校验
def checkFile(path, file):
# 不存在文件夹则创建文件夹,并返回false
if not os.path.exists(path):
os.makedirs(path)
return False
# 存在文件夹但不存在文件,返回false
elif not os.path.exists(path+file):
return False
# 存在文件夹且存在文件,返回true
else:
return True
# 下载两张瓦片并叠加
def downloadTwo(path, x, y, z):
path = path + "{z}\\".format(z=z)
file = "{x}_{y}.png".format(x=x, y=y)
if(checkFile(path, file)):
return
img1 = downloadOne(type1, x, y, z) # 下载街道地图
img2 = downloadOne(type2, x, y, z) # 下载文字注记
img_add_img(img1, img2, path+file) # 叠加两幅瓦片
# 图像img1和img2叠加,并保存到file
def img_add_img(img1, img2, file):
size = img1.shape #获取img1的大小
img = np.zeros((size[0], size[1], 3), np.uint8)
for i in range(0, size[0]):
for j in range(0, size[1]):
if img2[i,j,0] < 10 and img2[i,j,1] < 10 and img2[i,j,2] < 10:
img[i,j,0] = img1[i,j,0]
img[i,j,1] = img1[i,j,1]
img[i,j,2] = img1[i,j,2]
elif img2[i,j,0] > 240 and img2[i,j,1] > 240 and img2[i,j,2] > 240:
img[i,j,0] = img1[i,j,0]
img[i,j,1] = img1[i,j,1]
img[i,j,2] = img1[i,j,2]
else:
img[i,j,0] = img2[i,j,0]
img[i,j,1] = img2[i,j,1]
img[i,j,2] = img2[i,j,2]
cv2.imwrite(file, img, [int(cv2.IMWRITE_PNG_COMPRESSION), 0])
# 输入经纬度和层级,获取该层级的横纵坐标
def lonlat2xy(lon, lat, zoom):
n = math.pow(2, zoom)
x = ((lon + 180) / 360) * n
y = (1 - (math.log(math.tan(math.radians(lat)) + (1 / math.cos(math.radians(lat)))) / math.pi)) / 2 * n
return int(x), int(y)
# 下载第zoom层级的瓦片
def download(path, mapRange, zoom):
x1, y1 = lonlat2xy(mapRange[0], mapRange[1], zoom)
x2, y2 = lonlat2xy(mapRange[2], mapRange[3], zoom)
total = (x2+1-x1) * (y2+1-y1)
#进度条
pbar = tqdm(total=total, desc='下载第{zoom}级地图瓦片'.format(zoom=zoom), unit='img')
for x in range(x1, x2+1):
for y in range(y1, y2+1):
downloadTwo(path, x, y, zoom)
pbar.update(1) #进度条更新
pbar.close() #关闭进度条
# 测试tk有效性
def test():
url = 'http://t0.tianditu.gov.cn/DataServer?T=cva_w&x=836&y=415&l=10&tk={tk}'.format(tk=tk)
response = requests.get(url, headers=headers, timeout=10)
if response.status_code != 200:
print('tk失效!请更换')
exit(1)
# 主函数
def main():
test()
path = r"D://tiles//"
startZoom = 9
endZoom = 11
# mapRange[min_lon, max_lat, max_lon, min_lat]
mapRange = [110, 34.5, 118, 30]
for zoom in range(startZoom, endZoom+1):
download(path, mapRange, zoom)
if __name__ == '__main__':
main()运行效果图


经度范围110°E-118°E,纬度范围30°S-34.5°S,9-11级地图,总计1949个瓦片,耗时18分46秒,平均每秒下载1.73个瓦片,速度勉强能用的水准。
使用多线程可以提高下载速度,但是频繁访问会被天地图检测到而禁止抓取。中间的取舍问题有兴趣的人可以和我讨论。