写在最前面
代码量高于一切
学习编程一定要上手去写。
学会问问题
学会使用搜索自己解决答案,我们遇到的问题90%都有人遇到过。遇到了bug就直接把错误代码粘贴复制google一下。
用案例去学习,用实践去学习
learn by doing.
不要用新华字典学习中文,通过基础实例教程来激发自己的学习兴趣和学习动力。
在我心中,程序员都是它们领域当中的开拓者,通过代码去创造和解决问题,这很厉害。我也应该学习这种解决问题的意识和能力。
一、撰写准备
1、词云库的安装
如何安装wordcloud库
这个过程中主要会遇到3个问题:
缺少轮子
这个网站
(https://blog.csdn.net/langezuibang/article/details/105667789)https://blog.csdn.net/langezuibang/article/details/105667789
找到适合自己版本的轮子。
如何查看anaconda的python的版本呢?
找到电脑上anaconda-打开文件所在位置-(看到几个快捷方式)-打开文件所在位置-
选中python右键属性-详细信息
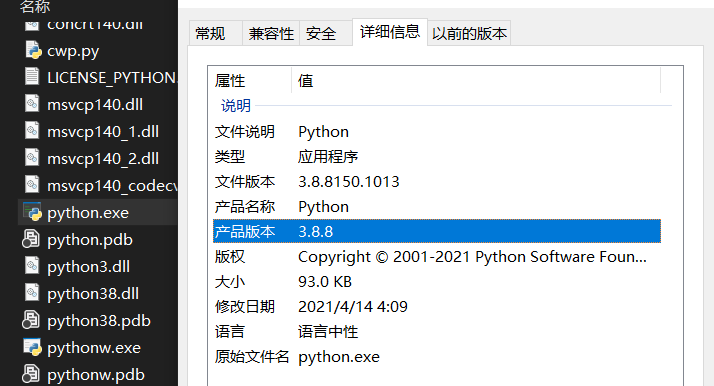
如何查看自己的系统位数?
我的电脑-空白处右键属性
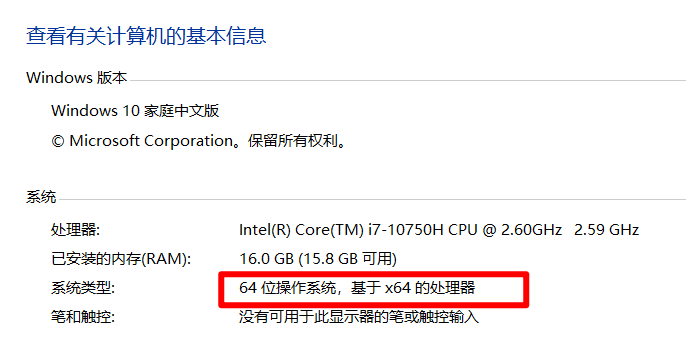
综上得到我的版本应该是python3.8,x64处理器
如何找到特定版本的轮子?
搜索大法好啊。
点击网址后,ctrl + f,在搜索框里搜索wordcloud。
最终选到心仪的轮子。
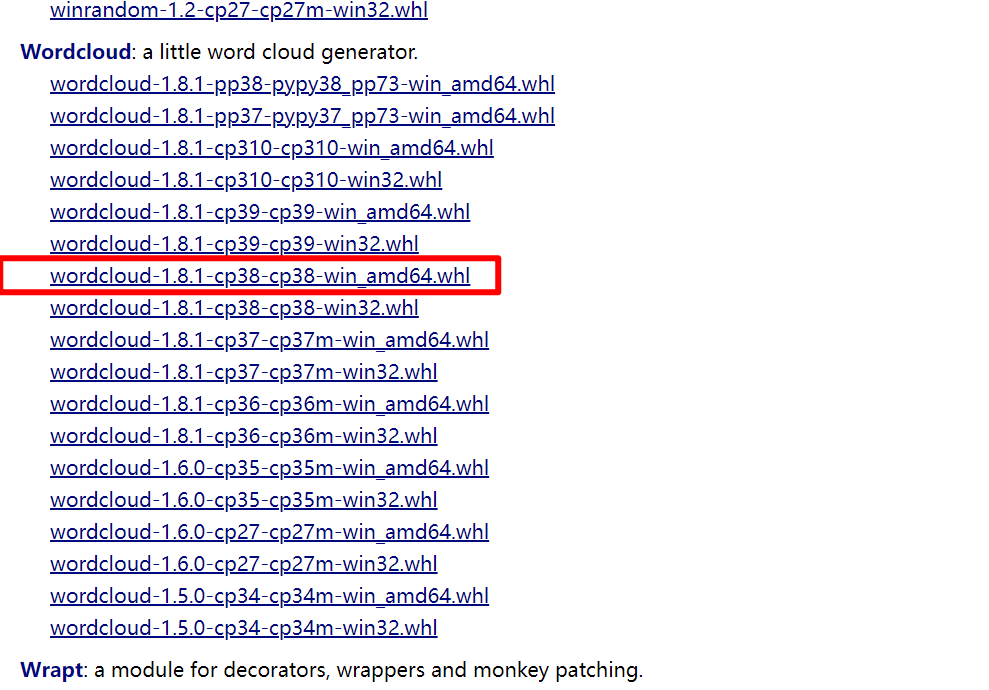
其他小问题
升级pip
python -m pip install --upgrade pip
更换镜像安装加速
永久更换
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
其他镜像源
豆瓣:http://pypi.douban.com/simple/
中科大:https://pypi.mirrors.ustc.edu.cn/simple/
清华:https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:https://mirrors.aliyun.com/pypi/simple/
暂时更换
pip install pandas -i http://pypi.douban.com/simple/
每次的安装包后添加-i http://链接
二、词云撰写
1、四行代码-词云低配版
import wordcloud
w=wordcloud.WordCloud()
w.generate('hello,yes,ok and i love you')
w.to_file('test1.png')

思路:
- 引入库
- 调用wordcloud
- 处理文字用生成函数
- 导出为图片
2、提取女朋友写的情书关键词并做成词云
库的引用
import re,os
import jieba
import docx
from wordcloud import WordCloud,ImageColorGenerator
import matplotlib.pyplot as plt
import imageio
os.chdir('D:\pythonAds2021\wordcloud')
进行中文分词
jgov=jieba.cut(rgov,cut_all=False)
进行词频统计
# 建立列表,作为遍历的基础
seglist=list(jgov)
# 建立字典,存放词与对应的词频
tf={
}
# 遍历:所有的元素第一遍都被赋值为一,第二次遍历时value+1
for seg in seglist:
if seg in tf:
tf[seg]+=1
else:
tf[seg]=1
引入停词表
# 引入停词表
with open ('stopword.txt',encoding='utf-8')as f1:
st=f1.read()
# 建立ci,作为词频遍历的基础
ci=list(tf.keys())
进行词频筛选
# 词频小于五的去除,长度小于2的去除,含一的去除,在停词表的去除
for seg in ci :
if tf[seg]<5 or len(seg)<2 or '一'in seg or seg in st or '事情'in seg or '东西'in seg:
tf.pop(seg)
读取词云的框图

mk=imageio.imread('heart.png')
wcd=WordCloud(font_path='D:\pythonAds2021\Alibaba-PuHuiTi-Heavy.otf',
mask=mk,
background_color=None, mode='RGBA',scale=32, max_words=100).generate_from_frequencies(tf)
# 引入颜色
imcolor=ImageColorGenerator(mk)
# 重新上色
plt.imshow(wcd.recolor(color_func=imcolor))
wcd.to_image()
wcd.to_file('dog.png')
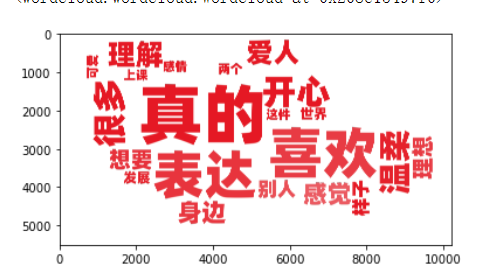
结果展示
完整代码
import re,os
import jieba
import docx
from wordcloud import WordCloud,ImageColorGenerator
import matplotlib.pyplot as plt
import imageio
os.chdir('D:\pythonAds2021\wordcloud')
# 读取docx文档
def readFile(path):
file=docx.Document(path)
# 读取每一段的内容
article = ' '
for para in file.paragraphs:
if para != '/n':
article = article + '' + para.text
return article
rgov=readFile("今天我喜欢的人他过生日.docx")
jgov=jieba.cut(rgov,cut_all=False)
# 建立列表,作为遍历的基础
seglist=list(jgov)
# 建立字典,存放词与对应的词频
tf={
}
# 遍历:所有的元素第一遍都被赋值为一,第二次遍历时value+1
for seg in seglist:
if seg in tf:
tf[seg]+=1
else:
tf[seg]=1
# 引入停词表
with open ('stopword.txt',encoding='utf-8')as f1:
st=f1.read()
# 建立ci,作为词频遍历的基础
ci=list(tf.keys())
# 词频小于五的去除,长度小于2的去除,含一的去除,在停词表的去除
for seg in ci :
if tf[seg]<5 or len(seg)<2 or '一'in seg or seg in st or '事情'in seg or '东西'in seg:
tf.pop(seg)
# 通过imageio引入mask
mk=imageio.imread('heart.png')
# 使用WordCloud,字体位置,mask,背景透明
# 并采用根据词频生成词云图
wcd=WordCloud(font_path='D:\pythonAds2021\Alibaba-PuHuiTi-Heavy.otf',
mask=mk,
background_color=None, mode='RGBA',scale=32).generate_from_frequencies(tf)
# 引入颜色
imcolor=ImageColorGenerator(mk)
# 重新上色
plt.imshow(wcd.recolor(color_func=imcolor))
wcd.to_image()
wcd.to_file('dog.png')