PageHelper是mybatis的一个分页插件
PageHelper.startPage放在查询语句的上面相邻 查询时就会自动拼接
PageHelper.startPage(pageNum,pageSize)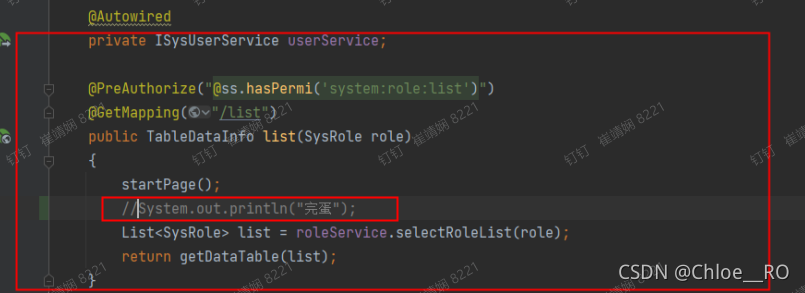
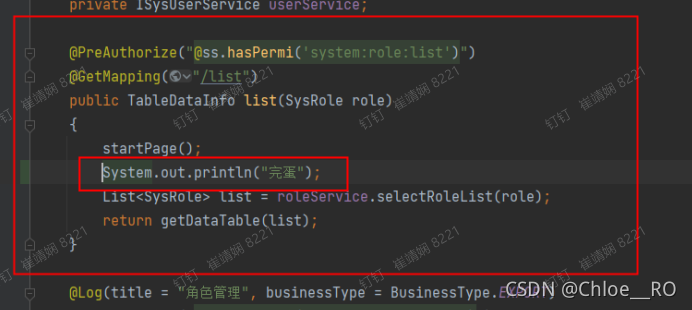
注意在service层也不能有过多的语句,因为这是在controller层加的 所以在service层要保证没有别的东西
像这样
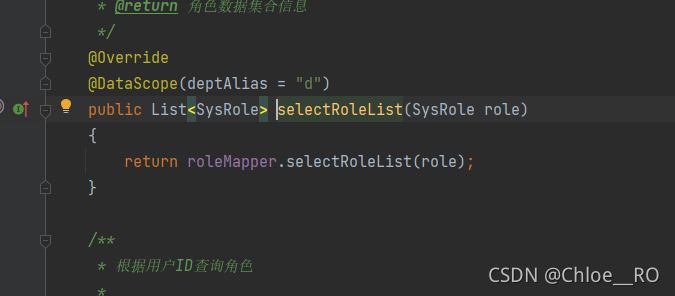
要么就在service层添加PageHelper.startpage(),且不能对返回结果进行任何处理
那sql语句和查询所有数据的时候一样吗?会自动拼接limit,拼接到sql语句结尾(如下)

具体实现如下
/**
* 根据管理员id查询主题列表
*
* @return 结果
*/
@Override
public List<ScoreThemeVO> selectScoreThemeVoList(String searchValue) {
Long userId = SecurityUtils.getUserId();
List<ScoreThemeVO> list = new ArrayList<ScoreThemeVO>();
/**根据用户id获得角色 并返回相应的主题列表参数*/
Integer roleID=scoreThemeMapper.getRoleIdById(userId);
if (ROLE_MANAGER_MAIN_ID.equals(roleID)) {
startPage();
return scoreThemeMapper.selectAllScoreThemeList(searchValue);
}
startPage();
return scoreThemeMapper.selectZiScoreThemeList(userId);
}
/**
* 设置请求分页数据
*/
protected void startPage()
{
PageDomain pageDomain = TableSupport.buildPageRequest();
Integer pageNum = pageDomain.getPageNum();
Integer pageSize = pageDomain.getPageSize();
if (StringUtils.isNull(pageNum) || StringUtils.isNull(pageSize))
{
pageNum = 1;
pageSize = 10;
}
PageHelper.startPage(pageNum, pageSize);
}
pageNum和pageSize一般给个默认值

mybaties 分页查询(这段来自我宝讲的)
/**
* 查询打分主题列表
*/
public ResultJson findPage(@PathVariable Integer currentPage,@PathVariable Integer pageSize)
{
int a = (currentPage-1)*pageSize;
List<Student> byPage = cardService.findByPage(a,pageSize);
return ResultJson.ok(byPage);
}
对应sql语句
/**
* 查询打分主题列表
*/
/* select * from student left join classname on student.id = classname.id limit 1,5
(limit 1,5)从下标为1数据开始拿,选五条数据(像数组一样数据列表第一条下标为0)
1是起始下标,5是返回的记录条数
为了检索从某一个偏移量到记录集的结束所有的记录行,可以指定第二个参数为 -1:
mysql> SELECT * FROM table LIMIT 95,-1; #检索记录行 96-last.
如果只给定一个参数,它表示返回最大的记录行数目:
mysql> SELECT * FROM table LIMIT 5; #检索前 5 个记录行
换句话说,LIMIT n 等价于 LIMIT 0,n。
select * from table LIMIT 5,10; #返回第6-15行数据
select * from table LIMIT 5; #返回前5行
select * from table LIMIT 0,5; #返回前5行*/
[拓展:监听器(注:以下来自大佬的对话)]
监听器 遇到过的最常用的就是rabbitMq 还有cannal同步数据
rabbitMQ 你把数据传到消息队列 通常会有一个延迟值,这个值是不固定的,需要你去监听队列的变化获取数据
举个简单的例子 ,阿里的canal是一个监听数据库增量日志的插件 ,当你同时使用数据库和redis甚至还有elasticsearch三方同时存储数据的时候
你不可能在每个对数据库增删改查的接口里都进行数据同步吧
所以可以根据数据库的增量日志变化 对应它的增删改查进行监听 直接用监听器里同步数据
这样既简化了代码 又实现了异步更新数据
不然的话 比如说你调用了一个增加用户的接口 本来这个操作插入数据库只需要200毫秒,但你又在这个接口下进行同步数据,最后使用了一秒以上,这就大大降低了效率
这是不是使用监听器进行统一同步数据?是
而不是分开一个一个地进行同步? 解耦
就你的代码就完全不需要考虑数据同步了 在监听器里做就可以了
这个是不是因为延迟值,队列的顺序并不是上传的顺序?(rabbitMQ 你把数据传到消息队列 通常会有一个延迟值,这个值是不固定的,需要你去监听队列的变化获取数据 )
就算最早上传,但是延迟值大,也差不多就排到队列的后面
/**
*今天日记完结,撒花~
* 又向我宝靠近一步,开心~
*/