《Self-critical Sequence Training(SCST) for Image Captioning》
RL:训练模型,输入state即图片及已经生成的单词,输出action即下一个单词,使得模型得到更高的reward(metric)。
Policy Gradient是RL的一个比较基本的算法,利用reward充当label,基于Policy来做梯度下降从而优化我模型。

假设一次状态行为序列为![]() (状态 动作 奖励)
(状态 动作 奖励)
![]()
![]() 为reward,
为reward, ![]() 表示采取
表示采取 ![]() 策略的发生概率,N为采样
策略的发生概率,N为采样 ![]() 的数目。
的数目。
![]()

使用了两个caption model作为基础,分别是
1.FC model,最小化cross entropy loss。
2.Attention Model,把attention feature输入到LSTM的cell node,并使用ADAM方法优化
把序列问题看作是强化学习问题:
- Agent: LSTM
- Environment: words and image features
- policy:模型参数θ决定policy pθ
- Action: prediction of the next word
- State: cells and hidden states of the LSTM
- Reward: CIDEr score r
![]()
![]()
![]()
引入一个baseline来减少gradient的variance,进行bias correction。
![]()
使用测试时生成的句子作为baseline,避免了单独训练一个baseline function。
在实际训练中过我们用sample得到的caption来作为这个梯度的估计(类似于mini-batch):
![]()

![]()
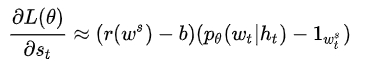
对sample得到的![]() ,后面一项一定是小于0的,这样的话,如果前面
,后面一项一定是小于0的,这样的话,如果前面![]() 大于0的话,对这个单词的梯度就是负的。那么我们在做梯度下降的时候,就会提高这个单词的分数。
大于0的话,对这个单词的梯度就是负的。那么我们在做梯度下降的时候,就会提高这个单词的分数。
SCST的思想就是用当前模型在测试阶段生成的词的reward作为baseline.

用greedy decoding得到的![]() 的reward做baseline。这个方法避免了单独训练一个baseline function。如果sample出来的结果比greedy decoding的结果烂,模型就会抑制这个结果,而如果结果比greedy decoding好的话,模型就会push up这个结果。
的reward做baseline。这个方法避免了单独训练一个baseline function。如果sample出来的结果比greedy decoding的结果烂,模型就会抑制这个结果,而如果结果比greedy decoding好的话,模型就会push up这个结果。