Hardware requirements:
Recommended
- 1 GPU or more
- 16 GB GPU memory
- 8 core CPU
- 32 GB system RAM
- 80 GB free disk space
Software Requirements:
- Ubuntu 16.04 LTS, Downloaded from http://releases.ubuntu.com/?_ga=2.184035374.948257150.1572359816-1174367670.1571739875
- NVIDIA GPU driver v410.xx or above, Download from https://www.nvidia.com/Download/index.aspx?lang=en-us.
- nvidia-docker 2.0 installed, instructions: https://github.com/NVIDIA/nvidia-docker.
1 Annotation Part
1.1 docker installation
本工程需要配置的Nvidia-docker建议安装docker19.03以后的版本,Nvidia-docker我理解的意义是在docker的基础上增加了访问GPU的能力,docker本身是不具备访问GPU的能力的。(TODO:确认Nvidia-docker具体实现了哪些东西。)
安装可见官网,建议离线下载安装:https://download.docker.com/linux/ubuntu/dists/
ubuntu16选择xenial,选择pool,选择edge(目前docker19.03版本还不属于stable版本),选择amd64(一般都是这个,具体参照:https://www.debian.org/ports/index.zh-tw.html),下载containerd.io,docker-ce-cil,docker-ce,因为有依赖关系,按顺序安装,顺序错了会提示你。(dpkg -i 即可)
如果你安装了旧版的docker,需要先卸载:参考官网- https://docs.docker.com/install/linux/docker-ce/ubuntu/
1.2 Nvidia-docker
这个github写的还挺详细的,我在啰嗦写一遍:
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
$ sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
$ sudo systemctl restart docker后边都是针对其他系统的Nvidia-docker配置了,这时候可以测试一下:
#### Test nvidia-smi with the latest official CUDA image
$ docker run --gpus all nvidia/cuda:9.0-base nvidia-smi我现在配置Nvidia-docker的时候已经不是Nvidia-docker 2.0 了,升级了,使用上的差别的话,现在调用GPU是--gpus的命令,过去是 --runtime=nvidia。
1.3 Get NGC API Key
NGC(NVIDIA GPU CLOUD), 网站:https://ngc.nvidia.com/,在左边选择SETUP,选择Generate API Key。按流程操作吧,把Key记下来,只出现一次,后边忘了就要重置了。
1.4 Pull Clara-Train_SDK from nvcr.io
$ docker login nvcr.io
Username: $oauthtoken
Password: <Your Key>注意,这里的Username就输入"$oauthtoken"这个字符串,不是什么你的账号啊、名字之类的。Password就是你上一步保存的Key。
这时候相当于你登录了Nvidia的仓库,你已经获得了Nvida的授权,可以在上边下载东西了,sdk下载使用命令:
docker pull nvcr.io/nvidia/clara-train-sdk:v1.1-py3这个可能多次失败,因为在外网,并且太大了,7个多G。
你们可以试试先logout你们的nvcr.io账户,登录你们的docker账户,用下边的命令从docker的仓库下载
docker pull pengbol/nvidia-clara-train-sdk-original:v1.1-py3这个好想比Nvidia的靠谱点儿,我从这里下载下来的。
1.5 launch the annotation server
# --gpus all means using all gpus in your machine
sudo docker run --gpus '"device=3"' -it --rm -p 5000:5000 pengbol/nvidia-clara-train-sdk-original:v1.1-py3 start_aas.sh
其中DOCKER_IMAGE就是我们前边下载的image(镜像:tag)。
具体的镜像名字和tag可以通过docker image ls查看。
这时候MITK那些软件填写好annotation server的地址后就可以和server通信了,server负责计算MITK中的客户(client)操作。
1.6 pull pre-trained model
最原始的clara-train-sdk image中是没有预训练模型呢的,需要去仓库拉取到server中。官方教程中介绍了两种方法:
方法1: 通过可视化界面交互的方式获取, http://127.0.0.1:5000/docs/ 填写相关信息;
方法2: 通过命令行的形式获取:
curl -X PUT "http://0.0.0.0:5000/admin/model/annotation_ct_spleen" -H "accept: application/json" -H "Content-Type: application/json" -d '{"path":"nvidia/med/annotation_ct_spleen","version":"1"}'-X PUT是指这个操作的基本含义,-H是header信息,-d是路径,这里的路径是指要下载的pre-trained的路径,NGC仓库的路径,不是本地的。PUT后边的路径的basename是个名字而已,可以随意修改。
但是这个需要在docker环境下的命令行执行,所以启动了上边的annotation server之后还要再开一个新的terminal进入命令行模式:
sudo docker run -it --rm --ipc=host --net=host --gpus all [--mount type=bind,source=/your/dataset/location,target=/workspace/data] $dockerImage /bin/bash [官方命令]
or
sudo docker run -it --rm --ipc=host --net=host --gpus all [-v source:workspace target] $dockerImage /bin/bash [我用的命令]ps:选择模型的话可以看Nvidia有多少预训练模型,
ngc registry model list nvidia/med/*查看已经下载了多少pre-trained mdoel的方法:
可以去http://0.0.0.0:5000/v1/models 查看
也可以使用curl http://0.0.0.0:5000/v1/models这个命令,会返回网页的信息
1.7 client operation
以MITK为例,因为官方已经帮助集成好了。那我都过一下吧。
先载入图像->设置label的名字->选择3D tools-> Nidia segmentation。
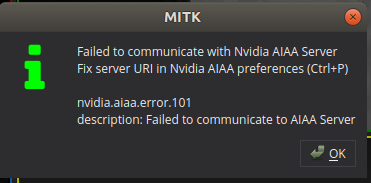
如果出现 不能通信之类的就是你的server路径写错了,或者你的server没有起来,ctrl+p去设置URI http://0.0.0.0:5000/v1/。


成功之后auto segmentation可以直接使用serer上的Segmentation模块生成分割结果以及6个 extreme points,可能会比较慢,因为是整个volume都要进行测试,这时候可以调整生成的6个extreme points使用Annotation模块的Confirm Points功能调用annotation算法重新生成object segmentation的结果;Annotation模块也可以直接使用,自己点出6个extreme points就可以了(shift+左键)。
1.8 transfer learning
使用其他的功能比如加入新数据重新训练之类的操作,我采用官方提供的模板来进行,如:https://ngc.nvidia.com/catalog/models/nvidia:med:segmentation_mri_brain_tumors_br16_t1c2tc/files
这是官方提供的一个模型压缩包,里边有模型文件和一些配置文件。所以我在/bin/bash 启动时候加入-v字段。

其中commands里边是一些sh命令,如训练,导出等等。config中是一些配置文件,models中是tf的模型,有ckpt格式和pb格式。
具体的操作可以参考nvidia官法的视频,就知道怎么操作了。视频地址:https://www.youtube.com/watch?v=T0Pjki4vXx0&t=228s
将数据放到-v中的source目录,执行命令来重采样到1x1x1mm(好像只有ct数据需要)
tlt-dataconvert -d ${SOURCE_IMAGE_ROOT} -r 1 -s .nii.gz -e .nii -o ${DESTINATION_IMAGE_ROOT}然后修改好dataset_0.json和environment.json文件就可以去command中执行train的sh文件了。
我尝试了一下,pb文件个ckpt的文件都可以用来载入模型训练,保存下来的都是ckpt格式。
# todo:不知道这种方式对不对
1.9 上传自己的文件
# 不知道 官方“# If you have MMAR archive”这句话什么意思,我理解MMAR就是上边的那个zip文件??todo
目前可行方案:
curl -X PUT "http://127.0.0.1:5000/admin/model/byom_segmentation_spleen" -F "[email protected];type=application/json" -F "[email protected]"
---------------------------------------------------------------------------
# If you have MMAR archive
curl -X PUT "http://127.0.0.1:5000/admin/model/segmentation_ct_spleen" -F "[email protected];type=application/json" -F "data=@segmentation_ct_spleen.with_models.tgz"
# If you have MMAR archive (if model config is skipped, it will search config_aiaa.json inside Archive)
curl -X PUT "http://127.0.0.1:5000/admin/model/segmentation_ct_spleen" -F "data=@segmentation_ct_spleen.with_models.tgz"可以上传至server使用,但是我不确定一些数据处理操作具体怎么写。#todo
还有一些更新config_aiaa.json配置和删除server已有模型的命令:
# refresh
curl -X PATCH "http://127.0.0.1:5000/admin/model/byom_segmentation_spleen" -H "Content-Type: application/json" -d @config-aiaa.json
# delete
curl -X DELETE "http://127.0.0.1:5000/admin/model/byom_segmentation_spleen"自己使用更多的是pytorch模型,需要先转到tensorflow的模型再按照上边的操作训练之类的即可。我采用的是ONNX的方式。可以参考我的另一篇https://blog.csdn.net/Eric_Evil/article/details/102941078
未完待续...