libfacedetection整体工作的亮点在于:
1.加速,使用int8数据类型,运行在CPU上,intel处理器就用SIMD指令加速,arm平台就用neon指令加速,速度快是一个很大的亮点,整体网络的卷积层59层,其中一半是33的卷积核,一半是11的卷积核,参数量确实不大。
2.多平台的可移植性,作者给出了ios,antroid的版本,给出了基于opencv dnn\caffe\openvino的部署;
3.训练技巧,无论是图像输入的归一化(去掉了mean,直接uint8输入,还是头100个epoch只训练框的回归,后400个epoch是框跟点一起回归(相当于是先收敛简单的任务,在学习复杂的任务),对称的8bit量化,总之作者加入了训练的诸多tricks;
网络的基于结构有:
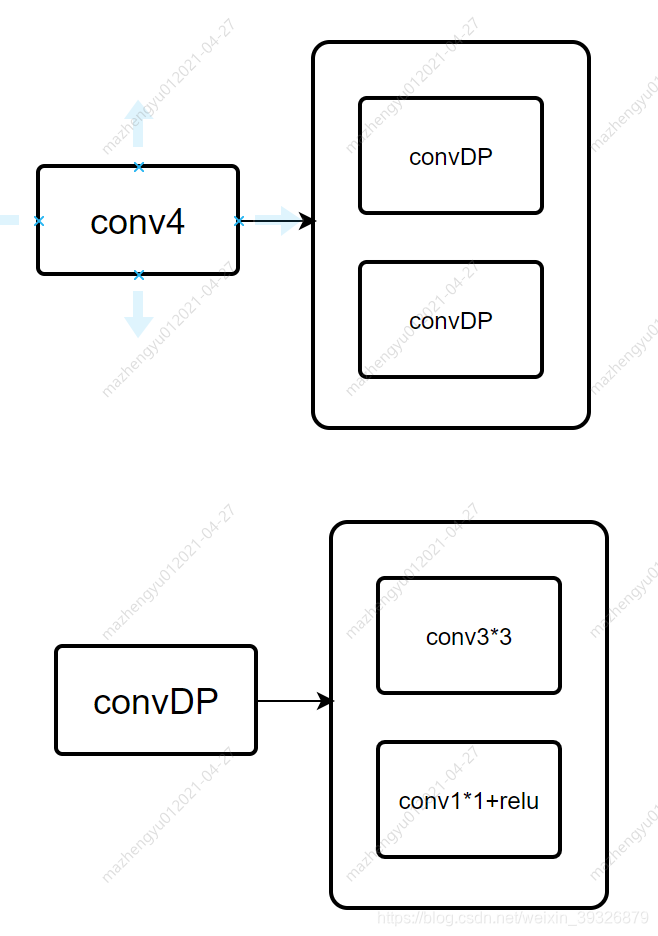
网络的主干部分:
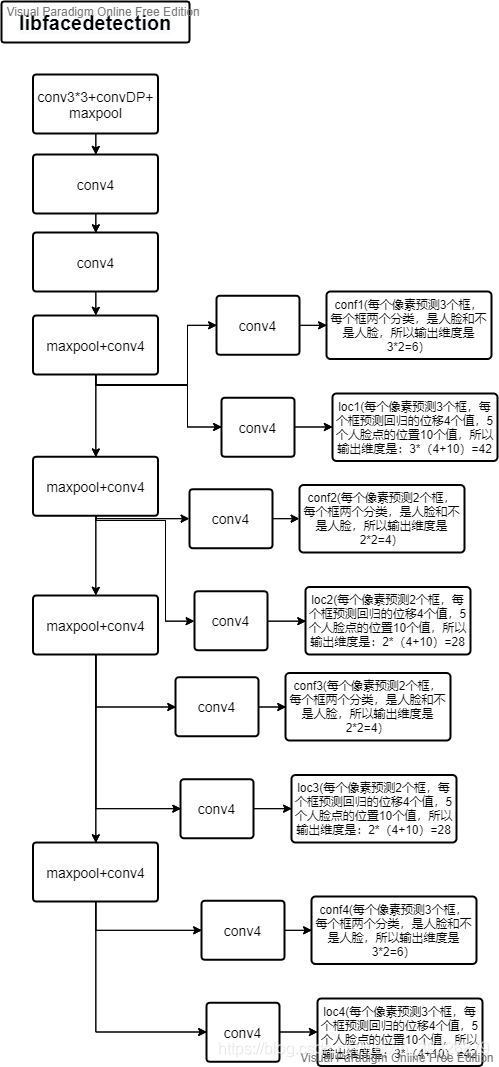
网络的后处理部分有:
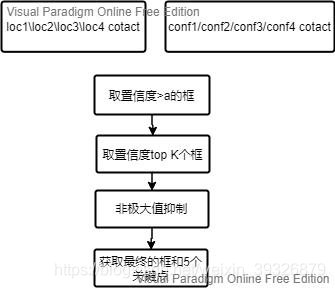
这个项目量化采用的方式比较粗暴:
1.直接除以参数最大值乘以127对参数进行int8量化;
2.仅仅对卷积参数进行了量化,并未对激活值进行量化;
量化部分代码如下(仅看标注处即为量化部分):
关于BN层的相关参数介绍可参考这篇博客:
https://blog.csdn.net/LoseInVain/article/details/86476010
class ConvBNReLU(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, **kwargs):
super(ConvBNReLU, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=True, **kwargs)
self.bn = nn.BatchNorm2d(out_channels)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = F.relu(x, inplace=True)
return x
#量化部分
#这个函数的目的相当于是将卷积的和bn的参数进行融合
#之所以要融合conv和bn,是因为它们都是线性的操作,融合后更加高效,乘法次数更少
def combine_conv_bn(self):
conv_result = nn.Conv2d(self.in_channels, self.out_channels,
self.conv.kernel_size, stride=self.conv.stride,
padding=self.conv.padding, bias=True)
#self.bn.weight BN层尺度的伸缩
#self.bn.bias BN层尺度的偏移
#self.bn.running_var BN层的方差
#self.bn.running_mean BN层的均值
#self.bn.eps 归一化时防止分母为0加的一个常量
#以下的地方稍微套一下公式即可明白,就是把BN的参数叠加到CNN上
scales = self.bn.weight / torch.sqrt(self.bn.running_var + self.bn.eps)
conv_result.bias[:] = (self.conv.bias - self.bn.running_mean) * scales + self.bn.bias
for ch in range(self.out_channels):
conv_result.weight[ch, :, :, :] = self.conv.weight[ch, :, :, :] * scales[ch]
return conv_result
class Conv_2layers(nn.Module):
def __init__(self, in_channels, mid_channels, out_channels, stride, **kwargs):
super(Conv_2layers, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.conv1 = ConvBNReLU(in_channels, mid_channels, 3, stride, 1, **kwargs)
self.conv2 = ConvBNReLU(mid_channels, out_channels, 1, 1, 0, **kwargs)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
return x
class Conv_3layers(nn.Module):
def __init__(self, in_channels, mid1_channels, mid2_channels, out_channels, stride, **kwargs):
super(Conv_3layers, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.conv1 = ConvBNReLU(in_channels, mid1_channels, 3, stride, 1, **kwargs)
self.conv2 = ConvBNReLU(mid1_channels, mid2_channels, 1, 1, 0, **kwargs)
self.conv3 = ConvBNReLU(mid2_channels, out_channels, 3, 1, 1, **kwargs)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
return x
class YuFaceDetectNet(nn.Module):
def __init__(self, phase, size):
super(YuFaceDetectNet, self).__init__()
self.phase = phase
self.num_classes = 2
self.size = size
self.model1 = Conv_2layers(3, 32, 16, 2)
self.model2 = Conv_2layers(16, 32, 32, 1)
self.model3 = Conv_3layers(32, 64, 32, 64, 1)
self.model4 = Conv_3layers(64, 128, 64, 128, 1)
self.model5 = Conv_3layers(128, 256, 128, 256, 1)
self.model6 = Conv_3layers(256, 256, 256, 256, 1)
self.loc, self.conf, self.iou = self.multibox(self.num_classes)
if self.phase == 'test':
self.softmax = nn.Softmax(dim=-1)
if self.phase == 'train':
for m in self.modules():
if isinstance(m, nn.Conv2d):
if m.bias is not None:
nn.init.xavier_normal_(m.weight.data)
m.bias.data.fill_(0.02)
else:
m.weight.data.normal_(0, 0.01)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def multibox(self, num_classes):
loc_layers = []
conf_layers = []
iou_layers = []
loc_layers += [nn.Conv2d(self.model3.out_channels, 3 * 14, kernel_size=3, padding=1, bias=True)]
conf_layers += [nn.Conv2d(self.model3.out_channels, 3 * num_classes, kernel_size=3, padding=1, bias=True)]
iou_layers += [nn.Conv2d(self.model3.out_channels, 3, kernel_size=3, padding=1, bias=True)]
loc_layers += [nn.Conv2d(self.model4.out_channels, 2 * 14, kernel_size=3, padding=1, bias=True)]
conf_layers += [nn.Conv2d(self.model4.out_channels, 2 * num_classes, kernel_size=3, padding=1, bias=True)]
iou_layers += [nn.Conv2d(self.model4.out_channels, 2, kernel_size=3, padding=1, bias=True)]
loc_layers += [nn.Conv2d(self.model5.out_channels, 2 * 14, kernel_size=3, padding=1, bias=True)]
conf_layers += [nn.Conv2d(self.model5.out_channels, 2 * num_classes, kernel_size=3, padding=1, bias=True)]
iou_layers += [nn.Conv2d(self.model5.out_channels, 2, kernel_size=3, padding=1, bias=True)]
loc_layers += [nn.Conv2d(self.model6.out_channels, 3 * 14, kernel_size=3, padding=1, bias=True)]
conf_layers += [nn.Conv2d(self.model6.out_channels, 3 * num_classes, kernel_size=3, padding=1, bias=True)]
iou_layers += [nn.Conv2d(self.model6.out_channels, 3, kernel_size=3, padding=1, bias=True)]
return nn.Sequential(*loc_layers), nn.Sequential(*conf_layers), nn.Sequential(*iou_layers)
def forward(self, x):
detection_sources = list()
loc_data = list()
conf_data = list()
iou_data = list()
x = self.model1(x)
x = F.max_pool2d(x, 2)
x = self.model2(x)
x = F.max_pool2d(x, 2)
x = self.model3(x)
detection_sources.append(x)
x = F.max_pool2d(x, 2)
x = self.model4(x)
detection_sources.append(x)
x = F.max_pool2d(x, 2)
x = self.model5(x)
detection_sources.append(x)
x = F.max_pool2d(x, 2)
x = self.model6(x)
detection_sources.append(x)
for (x, l, c, i) in zip(detection_sources, self.loc, self.conf, self.iou):
loc_data.append(l(x).permute(0, 2, 3, 1).contiguous())
conf_data.append(c(x).permute(0, 2, 3, 1).contiguous())
iou_data.append(i(x).permute(0, 2, 3, 1).contiguous())
loc_data = torch.cat([o.view(o.size(0), -1) for o in loc_data], 1)
conf_data = torch.cat([o.view(o.size(0), -1) for o in conf_data], 1)
iou_data = torch.cat([o.view(o.size(0), -1) for o in iou_data], 1)
if self.phase == "test":
output = (loc_data.view(loc_data.size(0), -1, 14),
self.softmax(conf_data.view(conf_data.size(0), -1, self.num_classes)),
iou_data.view(iou_data.size(0), -1, 1))
else:
output = (loc_data.view(loc_data.size(0), -1, 14),
conf_data.view(conf_data.size(0), -1, self.num_classes),
iou_data.view(iou_data.size(0), -1, 1))
return output
def convert_conv_intstring(self, conv, name):
'''
Convert the weights into int8
bias data will be converted at the same scale with weights,
but bias will be stored in int32
将参数转换成int8,同时常数项bias偏置被转换到跟weights相同的尺度,但是仍然是int32类型
'''
(out_channels, in_channels, width, height) = conv.weight.size()
w = conv.weight.detach().numpy().reshape(-1)
b = conv.bias.detach().numpy().reshape(-1)
#获取参数的最大值
maxvalue = np.amax(np.abs(w))
#将参数归一化到-128~127之间,获取scale
scale = 127 / maxvalue
#参数和偏置都要转换成int型
intw = np.round(w * scale).astype(int)
intb = np.round(b * scale).astype(int)
lengthstr_w = str(out_channels) + '*' + str(in_channels) + '*' + str(width) + '*' + str(height)
resultstr = 'signed char ' + name + '_weight[' + lengthstr_w + '] = {'
for idx in range(intw.size - 1):
resultstr += (str(intw[idx]) + ', ')
resultstr += str(intw[-1])
resultstr += '};\n'
resultstr += 'int ' + name + '_bias[' + str(out_channels) + '] = {'
for idx in range(intb.size - 1):
resultstr += (str(intb[idx]) + ', ')
resultstr += str(intb[-1])
resultstr += '};\n'
#print('weight size:', w.size)
#print('weight max:', maxvalue)
return resultstr, scale
def export_cpp(self, filename):
'''This function can export CPP data file for libfacedetection'''
result_str = '// Auto generated data file\n'
result_str += '// Copyright (c) 2018-2020, Shiqi Yu, all rights reserved.\n'
result_str += '#include "facedetectcnn.h" \n\n'
# ConvBNReLU types
conv_bn_relu = [self.model1.conv1, self.model1.conv2,
self.model2.conv1, self.model2.conv2,
self.model3.conv1, self.model3.conv2, self.model3.conv3,
self.model4.conv1, self.model4.conv2, self.model4.conv3,
self.model5.conv1, self.model5.conv2, self.model5.conv3,
self.model6.conv1, self.model6.conv2, self.model6.conv3]
# nn.Conv2D types
convs = []
for c in conv_bn_relu:
convs.append(c.combine_conv_bn())
for (l, c, i) in zip(self.loc, self.conf, self.iou):
convs.append(l)
convs.append(c)
convs.append(i)
#这里是量化部分
# convert to int8(weight) and int(bias)
# then convert to a string
num_conv = len(convs)
scales = []
for idx in range(num_conv):
rs, scale = self.convert_conv_intstring(convs[idx], 'f' + str(idx))
result_str += rs
result_str += '\n'
scales.append(scale)
# print(self.convert_conv_intstring(convs[0], 'f0'))
result_str += 'ConvInfoStruct param_pConvInfo[' + str(num_conv) + '] = { \n'
for idx in range(num_conv):
result_str += (' {' +
str(convs[idx].padding[0]) + ', ' +
str(convs[idx].stride[0]) + ', ' +
str(convs[idx].kernel_size[0]) + ', ' +
str(convs[idx].in_channels) + ', ' +
str(convs[idx].out_channels) + ', ' +
str(scales[idx]) + 'f, ' +
'f' + str(idx) + '_weight' + ', ' +
'f' + str(idx) + '_bias' +
'}')
if (idx < num_conv - 1):
result_str += ','
result_str += '\n'
result_str += '};\n'
# write the content to a file
#print(result_str)
with open(filename, 'w') as f:
f.write(result_str)
f.close()
return 0