TensorFlow2.0学习三之线性回归
一个实际问题,某城市在 2013 年 - 2017 年的房价如下表所示:
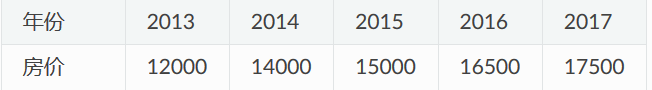
现在,我们希望通过对该数据进行线性回归,即使用线性模型 y = ax + b 来拟合上述数据,此处 a 和 b 是待求的参数。
首先,定义数据,进行归一化操作
import numpy as np
X_raw = np.array([2013, 2014, 2015, 2016, 2017], dtype=np.float32)
y_raw = np.array([12000, 14000, 15000, 16500, 17500], dtype=np.float32)
X = (X_raw - X_raw.min()) / (X_raw.max() - X_raw.min())
y = (y_raw - y_raw.min()) / (y_raw.max() - y_raw.min())
梯度下降方法来求线性模型中两个参数 a 和 b 的值

Numpy下的线性回归
使用Numpy这一通用的科学计算库来实现梯度下降方法。
NumPy 提供了多维数组支持,可以表示向量、矩阵以及更高维的张量。同时,也提供了大量支持在多维数组上进行操作的函数(比如下面的 np.dot() 是求内积, np.sum() 是求和)。
a, b = 0, 0
num_epoch = 10000
learning_rate = 1e-3
for e in range(num_epoch):
# 手动计算损失函数关于自变量(模型参数)的梯度
y_pred = a * X + b
grad_a, grad_b = (y_pred - y).dot(X), (y_pred - y).sum()
# 更新参数
a, b = a - learning_rate * grad_a, b - learning_rate * grad_b
print(a, b)
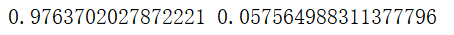
两个痛点:
①经常需要手工求函数关于参数的偏导数。如果是简单的函数或许还好,但一旦函数的形式变得复杂(尤其是深度学习模型),手工求导的过程将变得非常痛苦,甚至不可行。
②经常需要手工根据求导的结果更新参数。这里使用了最基础的梯度下降方法,因此参数的更新还较为容易。但如果使用更加复杂的参数更新方法(例如 Adam 或者 Adagrad),这个更新过程的编写同样会非常繁杂。
而 TensorFlow 等深度学习框架的出现很大程度上解决了这些痛点,为机器学习模型的实现带来了很大的便利。
TensorFlow 下的线性回归
使用 tape.gradient(ys, xs) 自动计算梯度;
使用 optimizer.apply_gradients(grads_and_vars) 自动更新模型参数。
X = tf.constant(X)
y = tf.constant(y)
a = tf.Variable(initial_value=0.)
b = tf.Variable(initial_value=0.)
variables = [a, b]
num_epoch = 10000
optimizer = tf.keras.optimizers.SGD(learning_rate=1e-3) # 声明了一个梯度下降优化器optimizer,学习率为1e-3
for e in range(num_epoch):
# 使用tf.GradientTape()记录损失函数的梯度信息
with tf.GradientTape() as tape:
y_pred = a * X + b
loss = 0.5 * tf.reduce_sum(tf.square(y_pred - y))
# TensorFlow自动计算损失函数关于自变量(模型参数)的梯度
grads = tape.gradient(loss, variables)
# TensorFlow自动根据梯度更新参数
optimizer.apply_gradients(grads_and_vars=zip(grads, variables))
print(a, b)

