Redis为kv的,而Redis底层又是由c语言写成的,一切皆字典dict,和java的一切皆对象Object
Redis的key类型一般为字符串,value为redis类型RedisObject这里的kv称为dictEntry
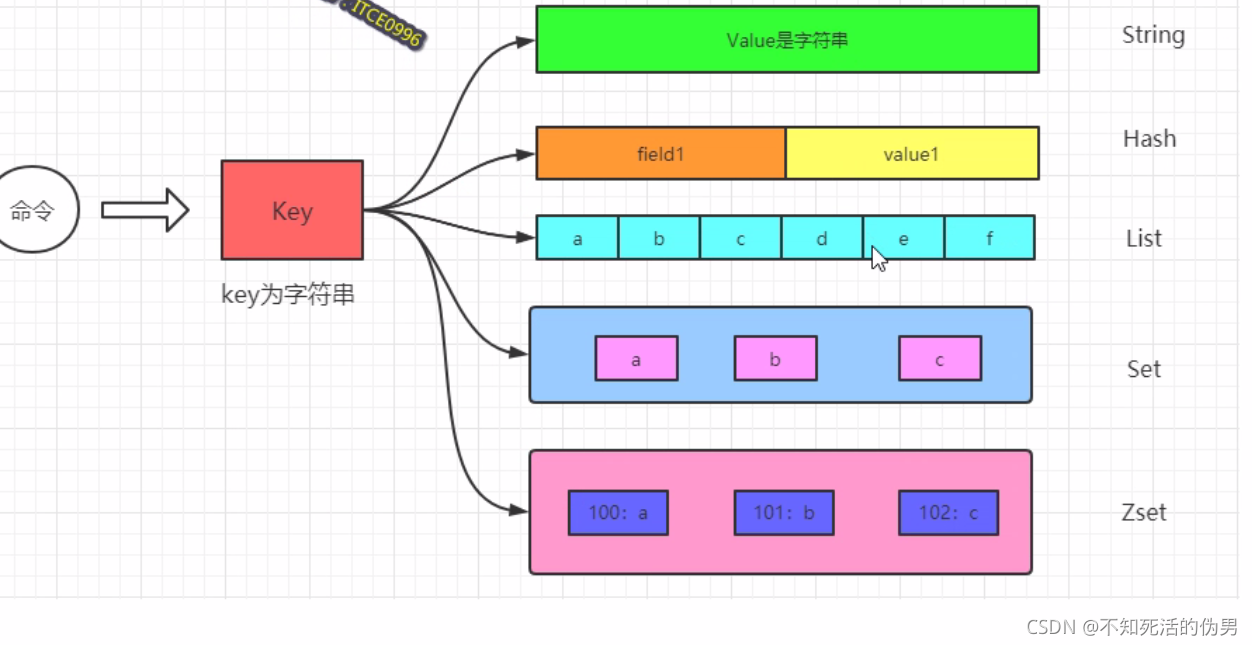
相当与java中的Map<String, redisObject>
bitmap底层为String类型,hyperloglog底层为String,GEO底层为zset
文章目录
1.上帝视角
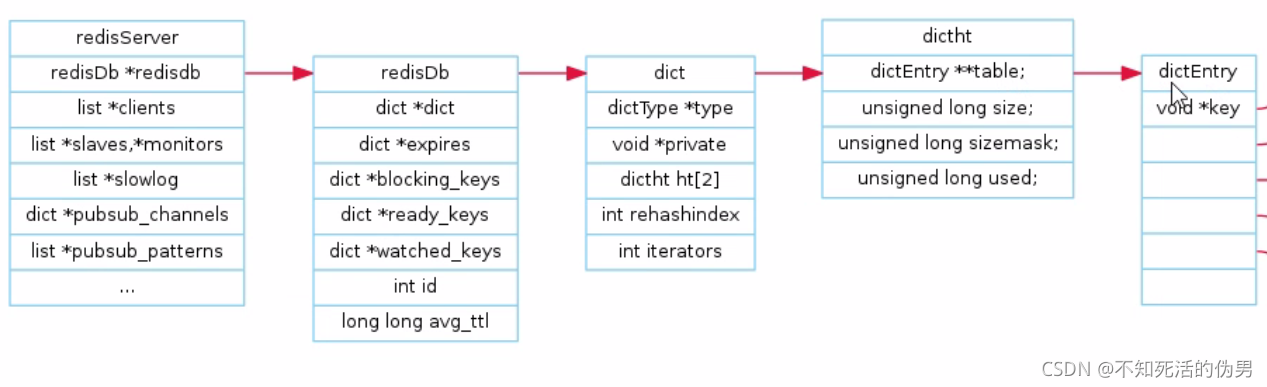
redisServer -> redisDB -> dict -> dictht -> dictEntry -> {String, list, hash, set, zset}
从硬件,网络到数据库到内部资源表到资源表到落地是实体
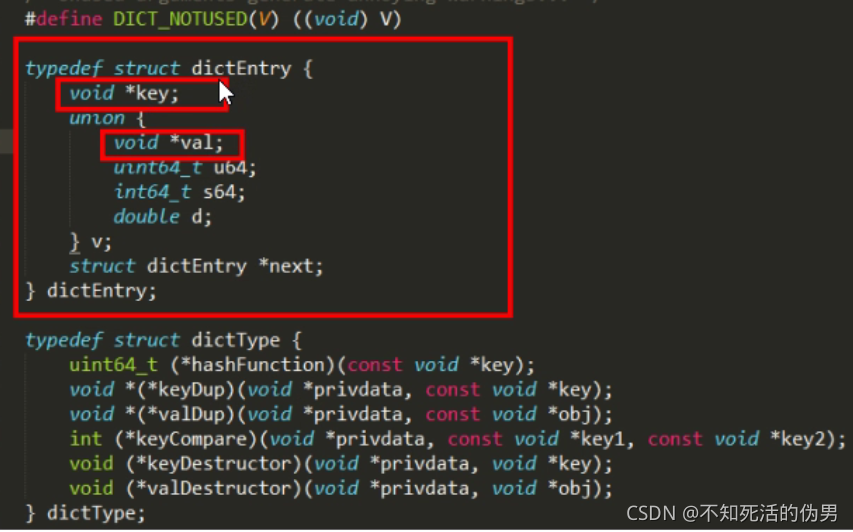
2.disctEntry
上文的kv键值对,所有的key为String,所有的value为redisObject
3.redisObject
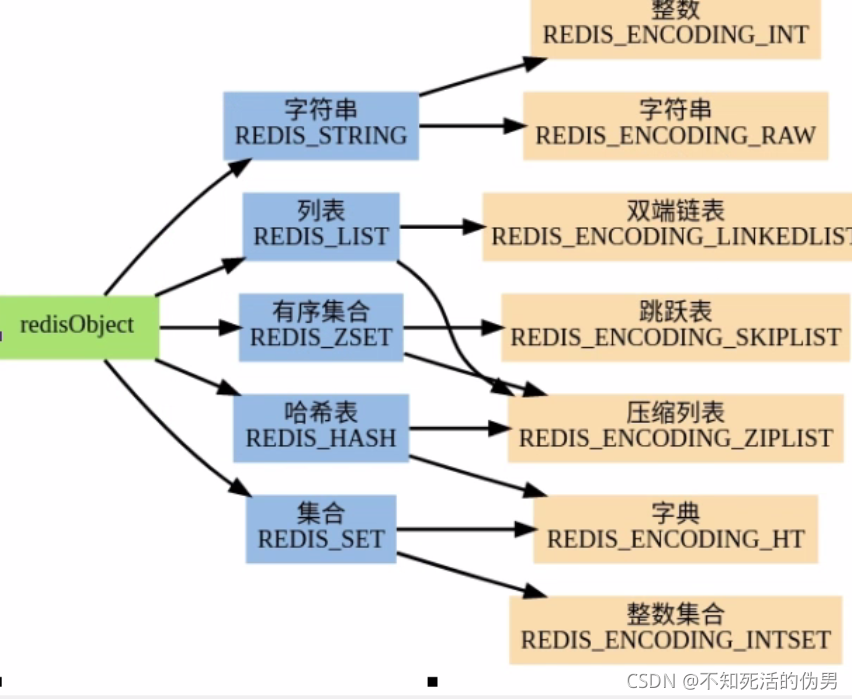

存在的结构体的内容为type,encoding,lru,refcount
type:string.list.set.zset.hash
encoding:当前值对象底层存储的编码类型
lru:采用lru算法清除内存的对象
refcount:记录对象引用次数
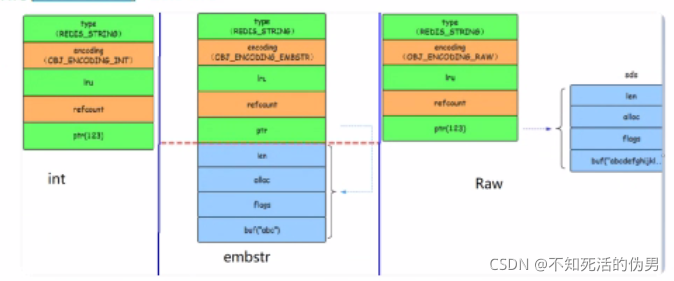
4.string的type和3大编码转换
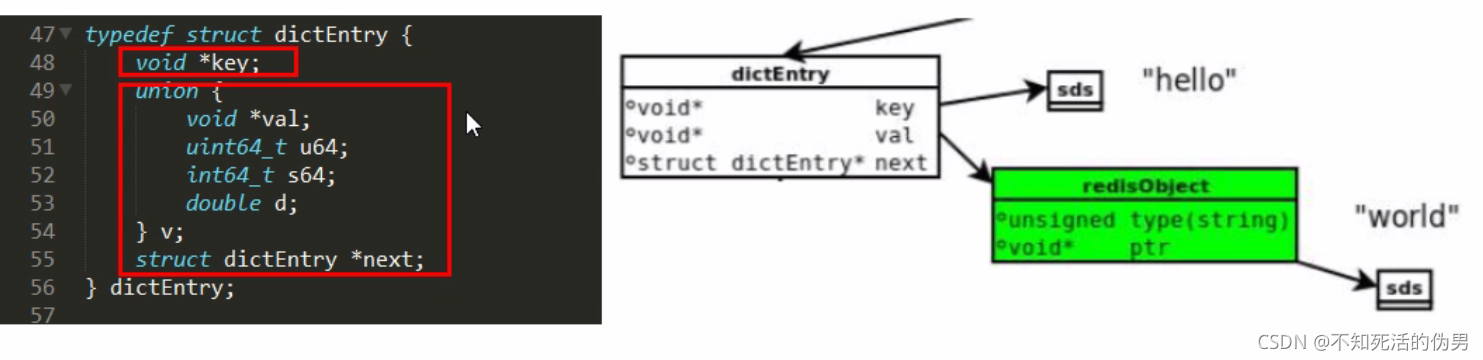
这里set hello world,key为String,但是String是存储在redis自定义的sds,动态字符串中,value为保存在redisObject中
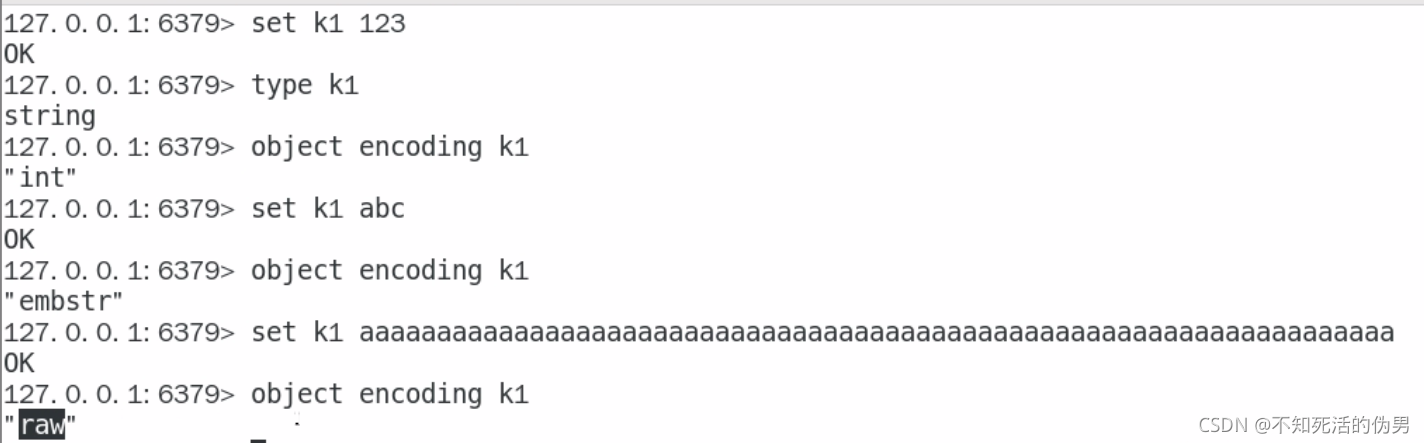
string的encoding:
1.int
2.raw
3.emstr
如果为数字的话encoding为int,如果不是数字的话为embstr,如果字符长度大于44的话为raw
长度0 ~ 19的话为int, 19 ~ 44 为str, >44 为raw
数字的话为int,不是数字为embstr,但是如果数字大于19 小于44的话为embstr。
全部的encoding:
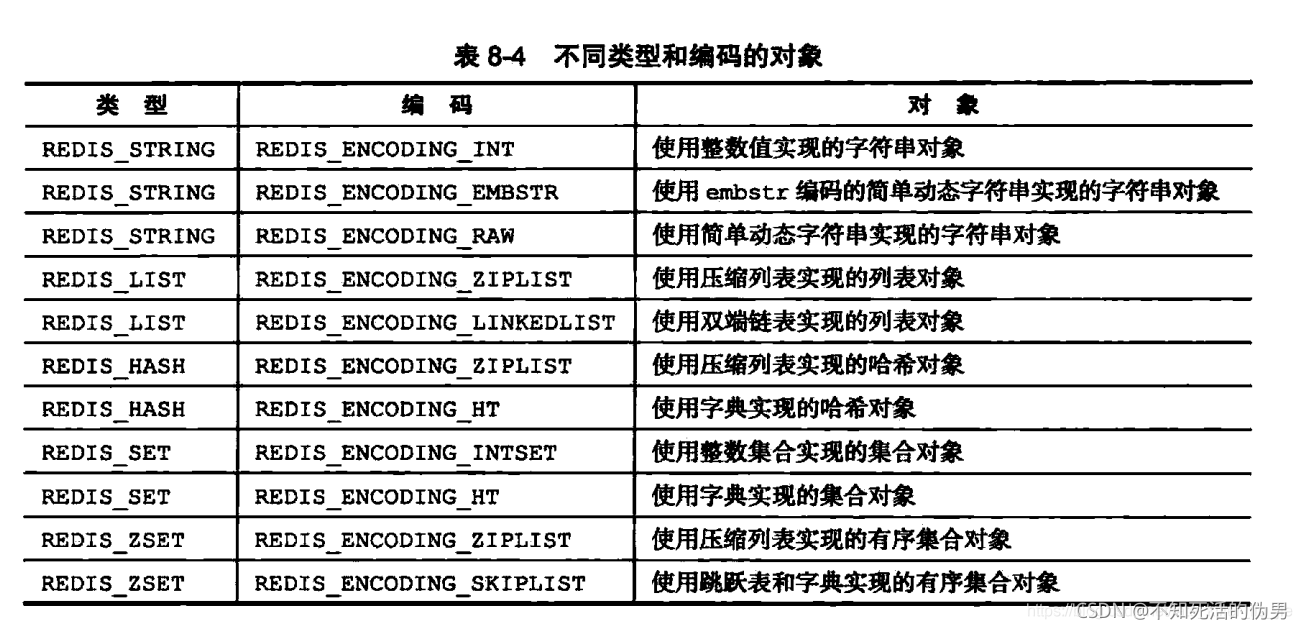
如果命令行为set age 17的话底层的C语言:
set age 17
{
type:string
encoding:int
lru
refcount
}
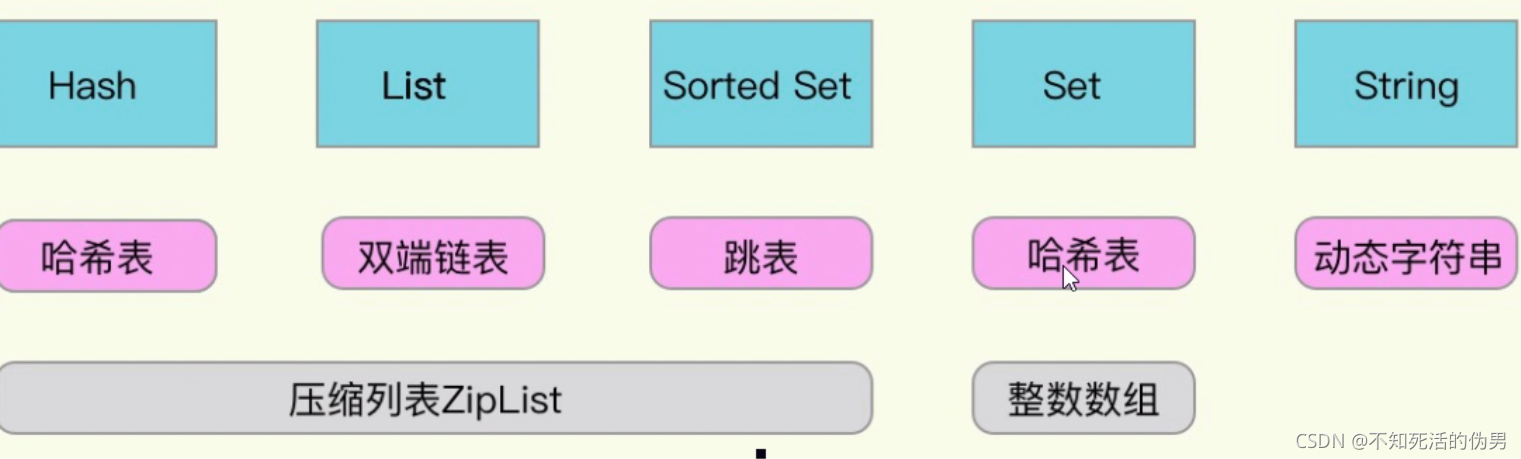
5.Redis底层的数据结构
5.1.sds:simple dynamic string
sds.h
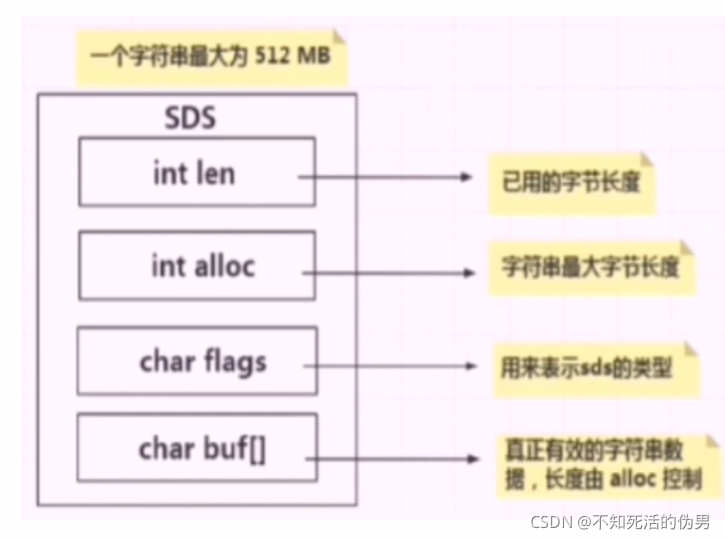
flags可以为sdshdr5,sdshdr8,sdshdr16,sdshdr32,sdshdr54
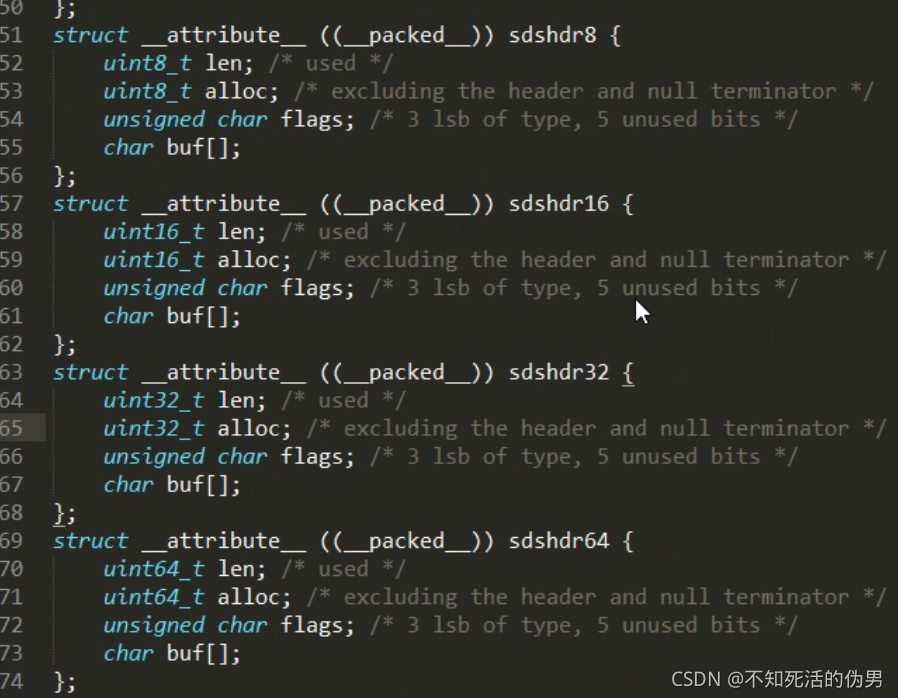
sds优点
1.记录了长度信息,strlen命令的开销变小
2.alloc:空间预分配:
如果SDS占用的空间小于1MB,那么每次扩展空间的时候会额外为SDS多分配一倍的空间,如果SDS占有的空间大于1MB,那么每次扩展之后额外分配1MB。
惰性释放指sds占用的空间缩小之后不会马上回收,而是标记起来,等下次要用的时候就直接取消标记,这样就省去了回收和重新分配的开销。
3.SDS二进制安全,C字符串使用空字符来标志字符串结束,那么就无法表示含有空字符的字符串,而SDS使用长度来标志结束,可以含有空字符。
4.防止了缓冲区溢出,如果使用C的字符数组保存数据,那么当字符串的长度超过数组时会覆盖掉后面的数据,造成溢出。而SDS在保存字符串的时候会首先检查空间是否足够,不够的话会先补足缺少的空间。
这里的int.embstr.raw:
1.对于embstr来说,由于实现为只读,所以修改的话,会变为raw,无论超没超过44字节
2.一开始判断是不是embstr或者raw,如果是的话,看长度是否大于20,如果不是则判断是否配置maxmemory且调整[0, 10000],然后直接从共享数拿到。
3.为何有3种编码格式,为的是极度的减少内存碎片
4.浮点数为emstr,raw
5.embstr:为嵌入式string,只是内存+1字节然后后面的内存嵌入到最后一字节中
如果是raw的话则另外开辟内存,如果是int的话,不用额外开启内存
5.2 hash
hash-max-ziplist-enties,使用压缩列表保存哈希集中最大元素个数,512
hash-max-ziplist-value,使用压缩列表保存哈希集中单个元素的最大长度,64byte
hash底层为ziplist+hashtable
当hash的数量小于hash-max-ziplist-enties,且字段小于hash-max-ziplist-value的时候为ziplist。
任意一个不满足的话改为hashtable
ziplist转为hashtable后不可以转回ziplist
5.2.1 ziplist跳表
zip + list
双向列表
压缩列表,思想为为了多花时间换取空间,以部分读写为代价换取极高的内存空间利用率

可以看到,压缩列表的格式很类似一些文件的编码方式,在文件开头有一些元数据,记录数据区域的位置和数据的条数。这种紧凑的格式避免了内存对齐这样的为了方便访问而引发的内存开销,压缩列表是在数据结构中元素较少时采取的数据结构,使用压缩列表节约了内存开支,但是降低了访问的速度,不过对于规模较小的对象,这样的损失可以忽略不记。
压缩列表节点构成
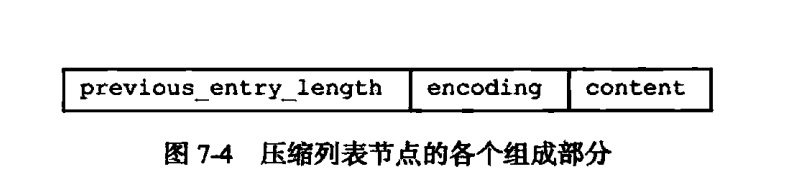
前一个节点长度+encoding+entry-data
previous_entry_length

encoding

5.2.2 hashtable字典dict

字典类似于Java中的Map,Python中的dict,是一种保存键值对的数据结构。Redis中的Hash由字典实现。其实Redis自身可以看成一个大的dict。
dict的实现如下:

table属性是一个数组,里面包含多个dictEntry,每个dictEntry保存了一个键值对。下面是一个空的dict。
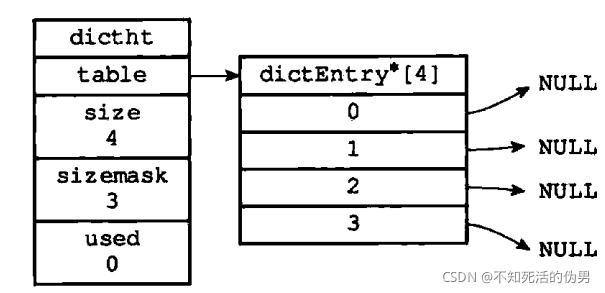
dictEntry是一个如下的结构体:

dictEntry里面包含一个dictEntry*的next,可以看出,这里是使用的拉链法来解决键冲突的,即hash值相同的键会保存在一个链表中。最后在dictht之上,Redis还做了一层封装,真正使用的dict是这样的:

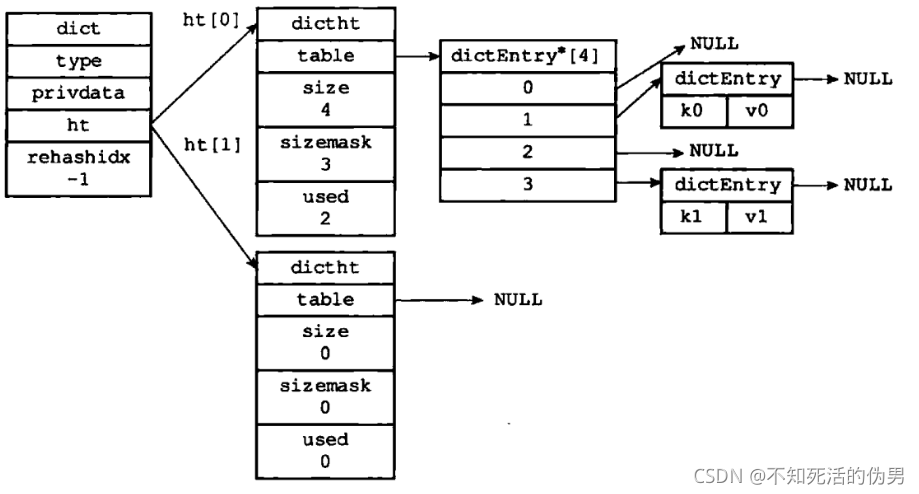
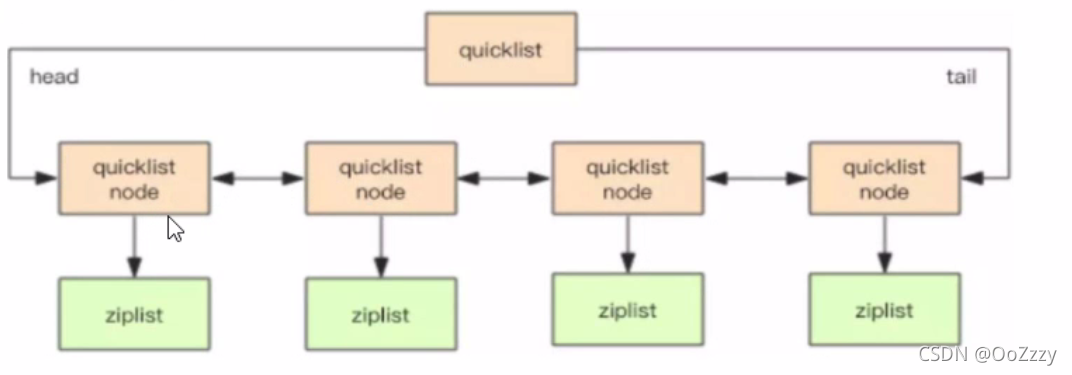
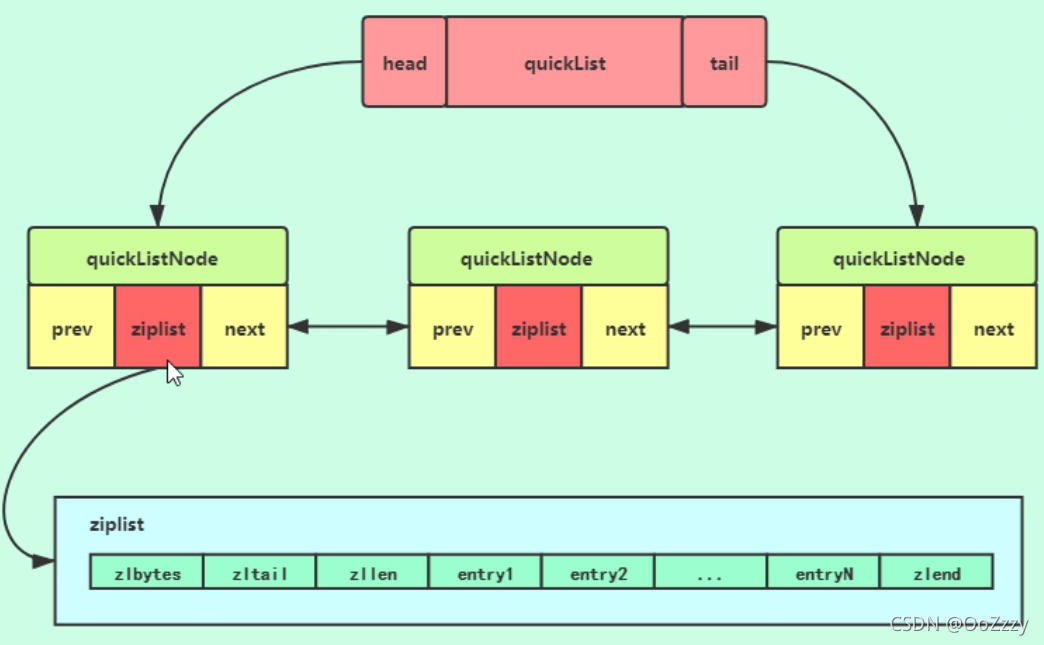
5.3 quicklist
list用quicklist存储的,quicklist存储一个双端链表,每一个节点为一个ziplist
低版本的redis,list用的为ziplist+linkedlist
高版本的redis,list用的为quicklist,为ziplist+linkedlist

5.4 inset
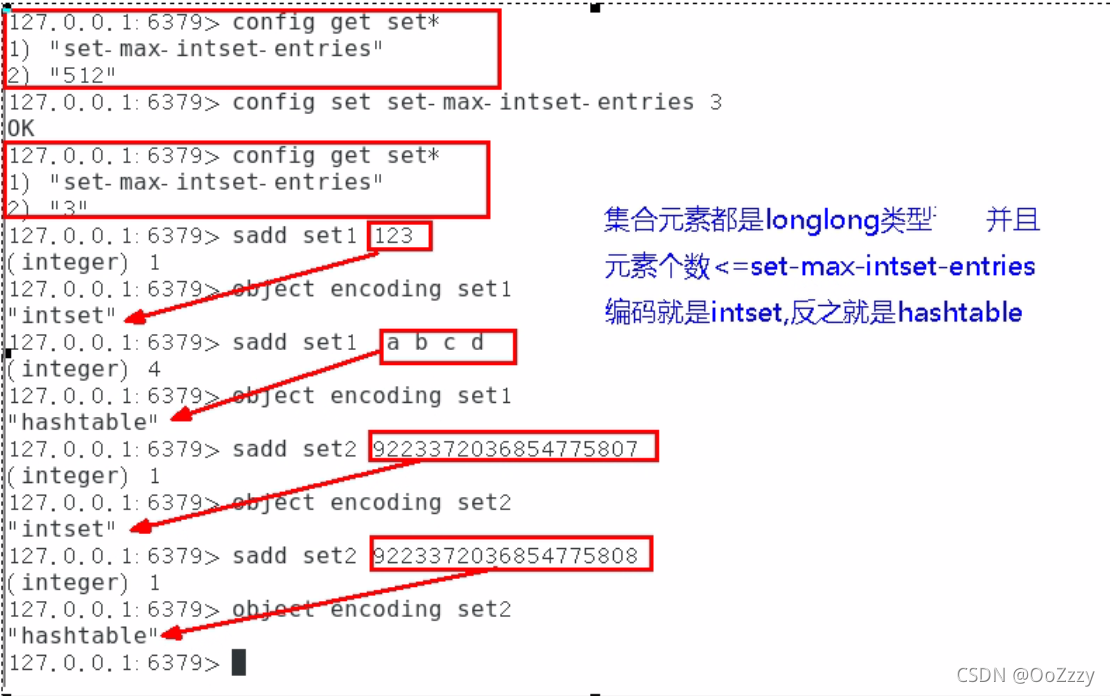
set用的为inset和hashtable底层的。
如果元素都为整数的话为Insert,如果不是整数的话为hashtable
5.5 skiplist跳表
zset底层为skiplist和ziplist
当server:zset_max_ziplist_entries > 128 或 server:zset_max_ziplist_value > 64时候.使用跳跃表,否则使用ziplist
skiplist = list + 多级索引
空间换时间
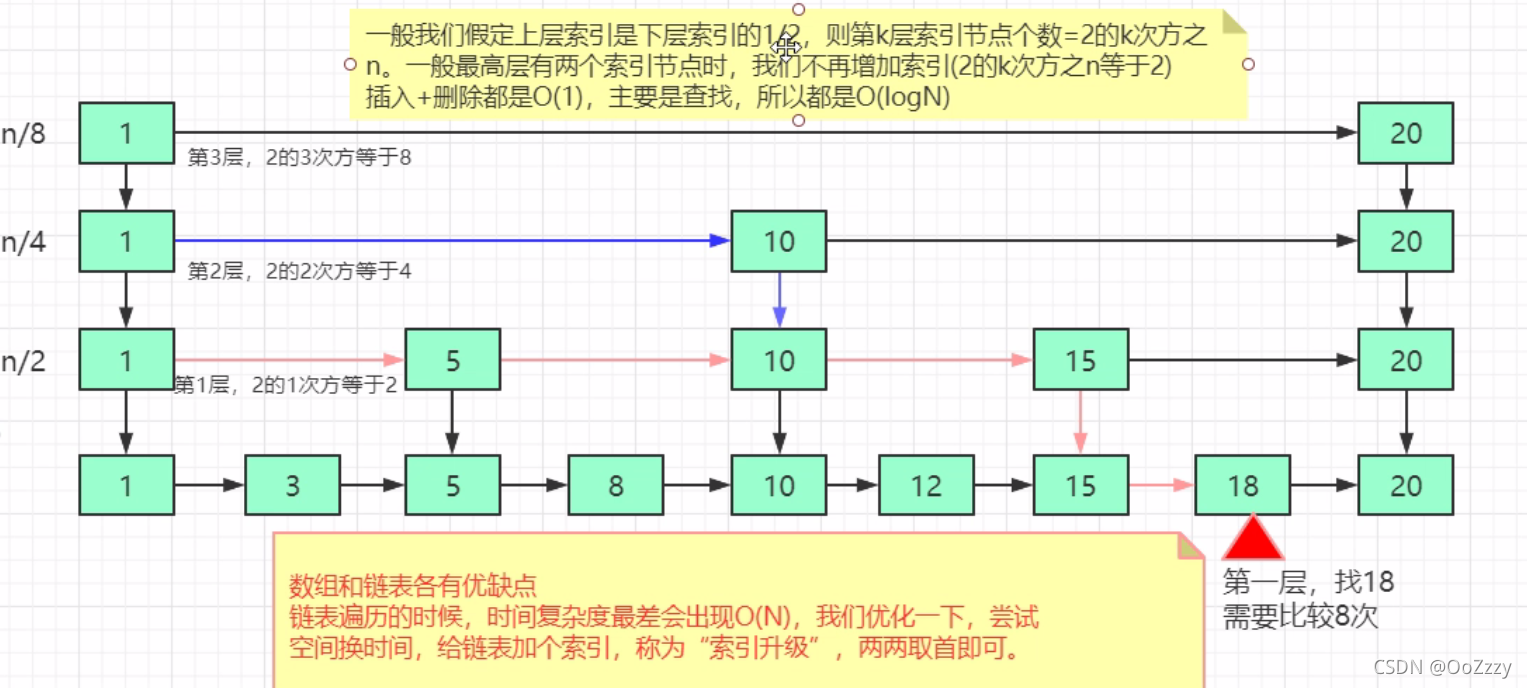
可以为隔3。
时间复杂度为O(logN)
空间复杂度为O(N)