STM32串口配置性能对比
Preface
上一篇博客说了下STM32串口丢失首字符相关的问题,这篇博客呢,想好好的讨论一下基于串口的printf函数。
Attention:三种方式已经上传到GitHub,基于正点原子探索者开发板!都是以工程文件夹的形式,下载编译运行即可
这个函数相信大家都不陌生,你开始在学习C语言的时候是不是这样的呢
#include "stdio.h"
int main(void)
{
printf("hello world\n");
return 0;
}
我们今天说的这个printf不在于它源码的实现,而在于使用它对嵌入式系统性能的影响。
1.printf
我们在嵌入式开发的过程中,经常用到串口这个外设。我们总是使用printf来打印调试信息,但是你知道吗,这个函数可没有你想象的那么好。
printf函数源码太大,我们写个简易版本的(对系统的影响没有区别)。
static void myprintf(char *str)//这是串口发送函数
{
while (*str)
{
USART1->DR = (u8)*str;
while ((USART1->SR & 0X40) == 0)
; //循环发送,直到发送完毕
str++;
}
}
上面函数就是实现了字符串的打印输出。
看起来没有问题,但是你有没有发现:
当cpu向串口数据寄存器写完数据,必须等待写入的数据全部发送出去以后才能够再次写入
那么这就意味在这段时间内cpu做不了其它的事,如果待发送的数据量大的话,那效率就太低了。
void task1_task(void *pvParameters)
{
char recv_item = 0;
while (1)
{
if (xQueueReceive(public_queue, &recv_item, 1000 / portTICK_PERIOD_MS) == pdTRUE)
{
putchar(recv_item);
}
else
{
printf("hello world!!!\r\n");
}
}
}
这个任务的功能是:每过1s中通过串口发送hello world。
再看systemview:
Context

task1占用cpu0.14%的资源,看起来不是很多。
Timeline
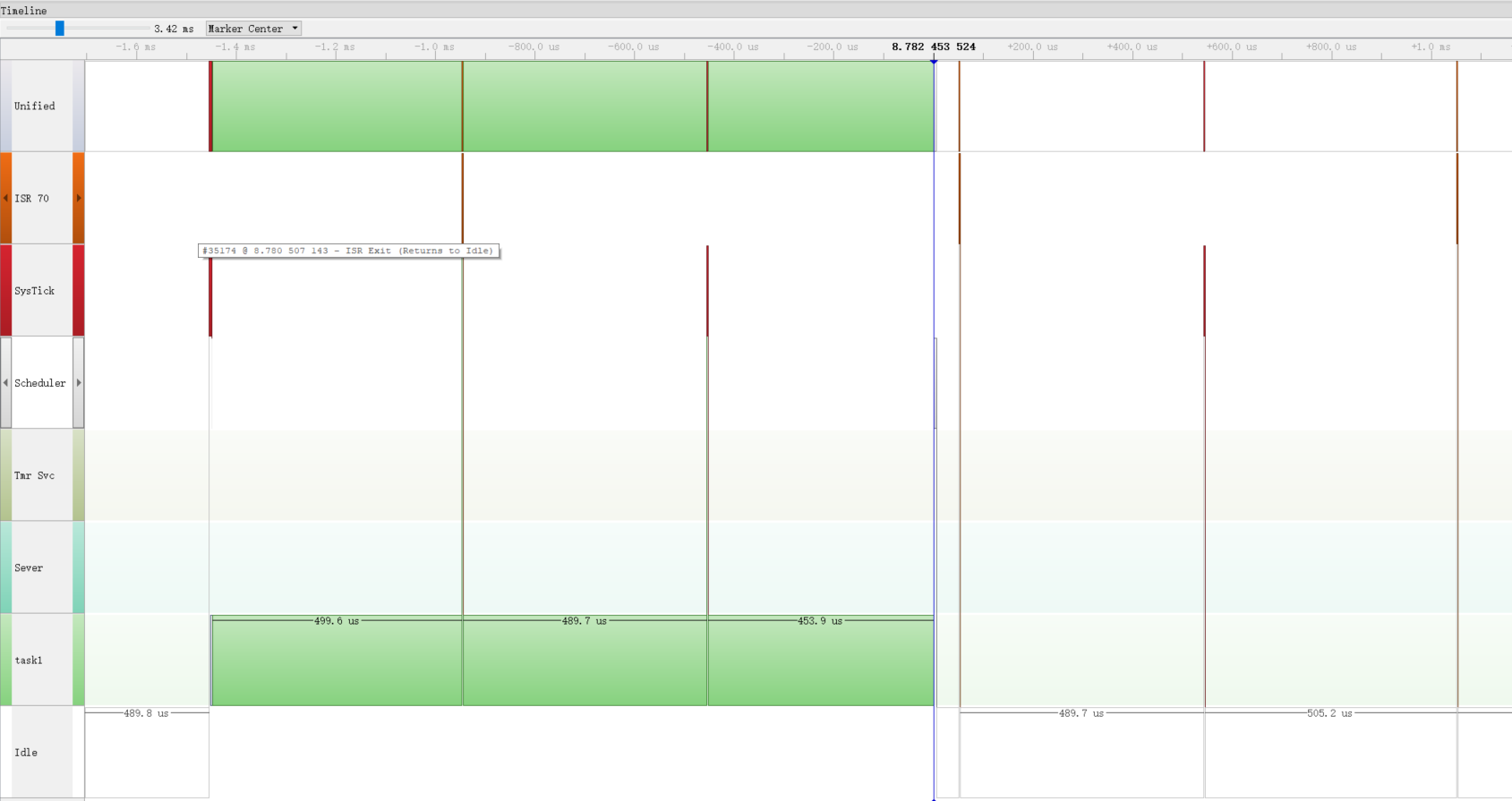
每调用一次函数,差不多要用到1.5ms!!!
竟然需要花费这么多的时间,这下你就知道为什么不要在中断函数里面调用printf了!!!
时间实在是太长了,freertos的心跳时间就是1个ms,差不多你调用一个printf,其它任务也就别执行了(假设调用printf的任务优先级最高)。
这显然是对嵌入式系统有很大的影响,特别是随着系统任务的增加。
Cpu Load

当你使用printf的时候,就相当于从那个时刻开始的之后一段时间内,cpu的资源都要给printf
总结
在嵌入式开发过程中,如果涉及到大量且频繁的数据这种方法肯定是不行的。
2.printf+interrupt
针对于单纯的使用printf函数所带来的总总问题,可以采用串口加中断的方式,以下是基于STM32的实现方法
2.1串口的初始化
void uart_init(u32 bound)
{
//GPIO端口设置
GPIO_InitTypeDef GPIO_InitStructure;
USART_InitTypeDef USART_InitStructure;
NVIC_InitTypeDef NVIC_InitStructure;
RCC_AHB1PeriphClockCmd(RCC_AHB1Periph_GPIOA, ENABLE); //使能GPIOA时钟
RCC_APB2PeriphClockCmd(RCC_APB2Periph_USART1, ENABLE); //使能USART1时钟
//串口1对应引脚复用映射
GPIO_PinAFConfig(GPIOA, GPIO_PinSource9, GPIO_AF_USART1); //GPIOA9复用为USART1
GPIO_PinAFConfig(GPIOA, GPIO_PinSource10, GPIO_AF_USART1); //GPIOA10复用为USART1
//USART1端口配置
GPIO_InitStructure.GPIO_Pin = GPIO_Pin_9 | GPIO_Pin_10; //GPIOA9与GPIOA10
GPIO_InitStructure.GPIO_Mode = GPIO_Mode_AF; //复用功能
GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz; //速度50MHz
GPIO_InitStructure.GPIO_OType = GPIO_OType_PP; //推挽复用输出
GPIO_InitStructure.GPIO_PuPd = GPIO_PuPd_UP; //上拉
GPIO_Init(GPIOA, &GPIO_InitStructure); //初始化PA9,PA10
//USART1 初始化设置
USART_InitStructure.USART_BaudRate = bound; //波特率设置
USART_InitStructure.USART_WordLength = USART_WordLength_8b; //字长为8位数据格式
USART_InitStructure.USART_StopBits = USART_StopBits_1; //一个停止位
USART_InitStructure.USART_Parity = USART_Parity_No; //无奇偶校验位
USART_InitStructure.USART_HardwareFlowControl = USART_HardwareFlowControl_None; //无硬件数据流控制
USART_InitStructure.USART_Mode = USART_Mode_Rx | USART_Mode_Tx; //收发模式
USART_Init(USART1, &USART_InitStructure); //初始化串口1
USART_Cmd(USART1, ENABLE); //使能串口1
//USART_ClearFlag(USART1, USART_FLAG_TC);
#if EN_USART1_RX
USART_ITConfig(USART1, USART_IT_RXNE, ENABLE); //开启相关中断
<font color='red'>注意,这个时候不要开启发送中断</font>
//Usart1 NVIC 配置
NVIC_InitStructure.NVIC_IRQChannel = USART1_IRQn; //串口1中断通道
NVIC_InitStructure.NVIC_IRQChannelPreemptionPriority = 14; //抢占优先级3
NVIC_InitStructure.NVIC_IRQChannelSubPriority = 0; //子优先级3
NVIC_InitStructure.NVIC_IRQChannelCmd = ENABLE; //IRQ通道使能
NVIC_Init(&NVIC_InitStructure); //根据指定的参数初始化VIC寄存器、
#endif
}
在这里要强调一下:千万不要串口初始化的时候开启发送中断。
因为STM32串口上电复位的TXE标志位为1。我上一篇博客有说!!!
2.2串口中断服务函数
void USART1_IRQHandler(void) //串口1中断服务程序
{
SEGGER_SYSVIEW_RecordEnterISR();
u8 Res;
extern char *pc_MAIN_myprintf1;
if (USART_GetITStatus(USART1, USART_IT_RXNE) != RESET) //接收中断(接收到的数据必须是0x0d 0x0a结尾)
{
Res = USART_ReceiveData(USART1); //(USART1->DR); //读取接收到的数据
if ((USART_RX_STA & 0x8000) == 0) //接收未完成
{
if (USART_RX_STA & 0x4000) //接收到了0x0d
{
if (Res != 0x0a)
USART_RX_STA = 0; //接收错误,重新开始
else
USART_RX_STA |= 0x8000; //接收完成了
}
else //还没收到0X0D
{
if (Res == 0x0d)
USART_RX_STA |= 0x4000;
else
{
USART_RX_BUF[USART_RX_STA & 0X3FFF] = Res;
USART_RX_STA++;
if (USART_RX_STA > (USART_REC_LEN - 1))
USART_RX_STA = 0; //接收数据错误,重新开始接收
}
}
}
}
if (USART_GetITStatus(USART1, USART_IT_TXE) != RESET) //发送中断
{
if (*pc_MAIN_myprintf1 == pdFALSE)
{
USART_ITConfig(USART1, USART_IT_TXE, DISABLE); //数据发送完成,串口发送中断失能
}
else
{
USART1->DR = (u8)*pc_MAIN_myprintf1++; //数据还没有发送完成
}
}
SEGGER_SYSVIEW_RecordExitISR();
}
我这个代码都是基于正点原子的。
在正点原子原有的基础之上,添加中断相关的代码块即可。
2.3中断printf函数的实现
static void myprintf1(char *str) //但是需要注意,字符串以/0结尾
{
USART_ClearFlag(USART1, USART_FLAG_TC); //防止出现stm32第一个字符丢失的现象
pc_MAIN_myprintf1 = str; //更新printf所指向的字符串
USART_ITConfig(USART1, USART_IT_TXE, ENABLE); //开启发送中断
}
上面这个函数主要是针对字符串以’\0’结尾的。
开启发送中断即可直接进入中断服务函数
2.4效果
Context

睁大你们的双眼看看:0%
几乎没有占用cpu的资源,为什么,你可能很纳闷。看下面。
Timeline

看出什么毛病来了没有。
也就是说,cpu向串口数据寄存器发送数据后并不会等待,而是去执行其它任务,等发送完成了,接着进入中断。
以这种方式:每发送一个字符,就仅仅只需要2个us,而以printf的形式,就需要85个us。
这是节省了多少时间。而且随着字符串的增加,或者是说传输大量数据的时候,那肯定效率大很多。
总结
这种串口加中断的方式确实是比单纯printf确实是节省时间,但是呢,如果遇到高频率,高吞吐量的数据的时候,这个也不行,因为那样会造成大量的高频率的中断,对任务的运行没有好处。到了那个时候,cpu load那就大起来了。你看到的是0%的cpu load。那是因为:
每过1s中发送一帧数据
那么第三种方式就来了。
3.printf+DMA+中断
这种方式是我目前见过最牛逼的,它的性能将近是第一种方式的140多倍,甚至可能更多。
3.1DMA初始化
static void BSP_DMA(DMA_Stream_TypeDef *DMA_Streamx, u32 chx, u32 par, u32 mar, u16 ndtr)
{
DMA_InitTypeDef DMA_InitStructure;
NVIC_InitTypeDef NVIC_InitStructure;
if ((u32)DMA_Streamx > (u32)DMA2) //得到当前stream是属于DMA2还是DMA1
{
RCC_AHB1PeriphClockCmd(RCC_AHB1Periph_DMA2, ENABLE); //DMA2时钟使能
}
else
{
RCC_AHB1PeriphClockCmd(RCC_AHB1Periph_DMA1, ENABLE); //DMA1时钟使能
}
DMA_DeInit(DMA_Streamx);
while (DMA_GetCmdStatus(DMA_Streamx) != DISABLE)
{
} //等待DMA可配置
/* 配置 DMA Stream */
DMA_InitStructure.DMA_Channel = chx; //通道选择
DMA_InitStructure.DMA_PeripheralBaseAddr = par; //DMA外设地址
DMA_InitStructure.DMA_Memory0BaseAddr = mar; //DMA 存储器0地址
DMA_InitStructure.DMA_DIR = DMA_DIR_MemoryToPeripheral; //存储器到外设模式
DMA_InitStructure.DMA_BufferSize = ndtr; //数据传输量
DMA_InitStructure.DMA_PeripheralInc = DMA_PeripheralInc_Disable; //外设非增量模式
DMA_InitStructure.DMA_MemoryInc = DMA_MemoryInc_Enable; //存储器增量模式
DMA_InitStructure.DMA_PeripheralDataSize = DMA_PeripheralDataSize_Byte; //外设数据长度:8位
DMA_InitStructure.DMA_MemoryDataSize = DMA_MemoryDataSize_Byte; //存储器数据长度:8位
DMA_InitStructure.DMA_Mode = DMA_Mode_Normal; // 使用普通模式
DMA_InitStructure.DMA_Priority = DMA_Priority_Medium; //中等优先级
DMA_InitStructure.DMA_FIFOMode = DMA_FIFOMode_Disable;
DMA_InitStructure.DMA_FIFOThreshold = DMA_FIFOThreshold_Full;
DMA_InitStructure.DMA_MemoryBurst = DMA_MemoryBurst_Single; //存储器突发单次传输
DMA_InitStructure.DMA_PeripheralBurst = DMA_PeripheralBurst_Single; //外设突发单次传输
DMA_Init(DMA_Streamx, &DMA_InitStructure); //初始化DMA Stream
NVIC_InitStructure.NVIC_IRQChannelCmd = ENABLE; // 使能
NVIC_InitStructure.NVIC_IRQChannelPreemptionPriority = 14; // 抢占优先级
NVIC_InitStructure.NVIC_IRQChannelSubPriority = 0; // 子优先级
NVIC_InitStructure.NVIC_IRQChannel = DMA2_Stream7_IRQn;
NVIC_Init(&NVIC_InitStructure); // 嵌套向量中断控制器初始化
DMA_ITConfig(DMA2_Stream7, DMA_IT_TC, ENABLE);
}
3.2 中断服务函数的编写
void DMA2_Stream7_IRQHandler(void) // 串口1 DMA发送中断处理函数
{
SEGGER_SYSVIEW_RecordEnterISR();
if (DMA_GetITStatus(DMA2_Stream7, DMA_IT_TCIF7) != RESET)
{
DMA_ClearFlag(DMA2_Stream7, DMA_FLAG_TCIF7);
DMA_Cmd(DMA2_Stream7, DISABLE); // 关闭DMA
DMA_SetCurrDataCounter(DMA2_Stream7, 0); //传输数据量为0
xSemaphoreGiveFromISR(private_MAIN_semaphore, NULL);
}
SEGGER_SYSVIEW_RecordExitISR();
}
3.DMA+中断的实现
static void myprintf1(char *str) //但是需要注意,字符串以/0结尾
{
USART_ClearFlag(USART1, USART_FLAG_TC); //防止出现stm32第一个字符丢失的现象
pc_MAIN_myprintf1 = str; //更新printf所指向的字符串
DMA_Cmd(DMA2_Stream7, DISABLE); //关闭DMA传输
while (DMA_GetCmdStatus(DMA2_Stream7) != DISABLE)
{
} //确保DMA可以被设置
BSP_SDMA(DMA2_Stream7, DMA_Channel_4, (u32)&USART1->DR, (u32)pc_MAIN_myprintf1, strlen(pc_MAIN_myprintf1)); //配置简化版的DMA
//DMA2_Stream7->M0AR =(U32)str;
DMA_Cmd(DMA2_Stream7, ENABLE); //开启DMA传输
}
3.4效果
Context

cpu load 为%0.49
什么,负载率这么高。
那是因为上面两种情况是每1s发送,而这个是全速运行。对,全速运行。
这是我测试后的数据:
10s的时间里:
printf+DMA+中断 发送了85618个字符
printf 发送了8272个字符
发送数据量时它的10倍
cpu load:
printf+DMA+中断 %0.49
printf %6.7
cpu负载时间时它的1/14。
相当于printf+DMA+中断是printf性能的140倍。并且随着数据量的增大会显得更加明显。
Timeline
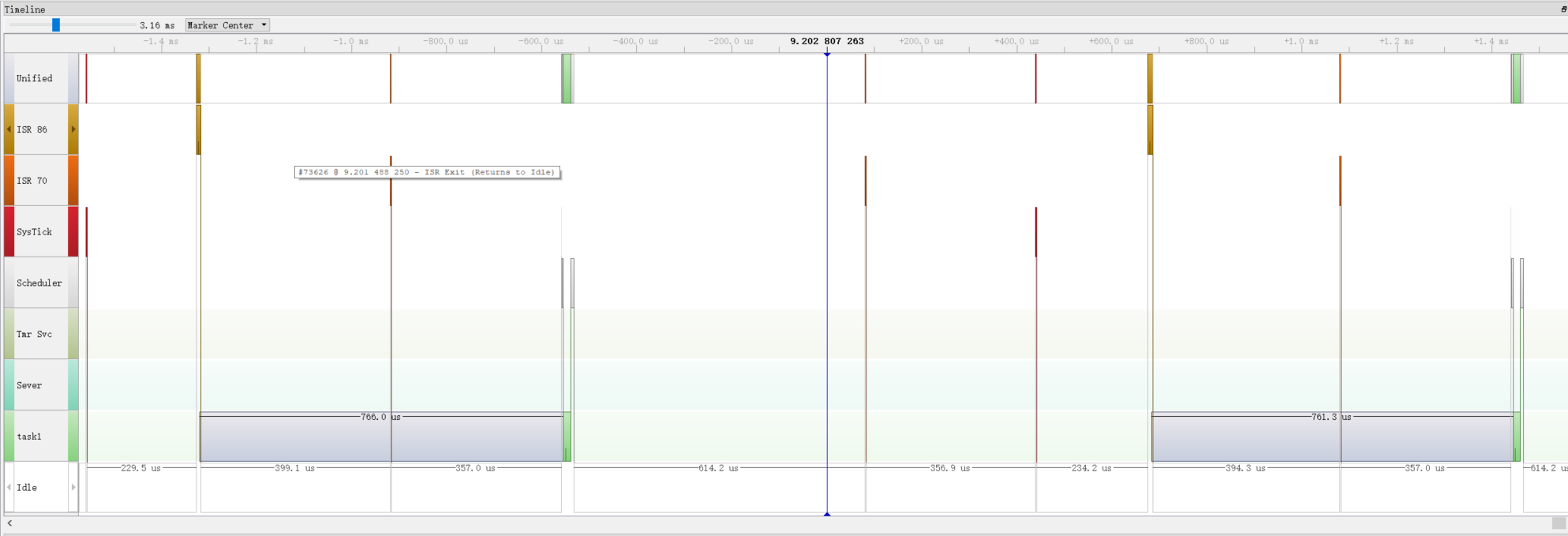
你看看这时间在差不多2ms的时间里发送了一帧数据,然后单纯的prinf发一个字符串要占用1.5个ms。
我只能说:牛逼。
总结
在嵌入式系统开发的过程中,我们经常使用的printf是不是和你想象的有点不一样。
如果需要对系统性能上提升,需要合理的使用DMA。它可是一个宝藏,不然STM32也不会给每个DMA stream分配一个单独的中断号。
可见DMA在嵌入式开发过程中的重要性!!!