KNN算法
介绍
KNN算法的全称是K最近邻(K-NearestNeighbor)分类算法,它是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻近值来代表。KNN是一种基于“已存储的实例”(训练集)直接进行分类任务的算法,不同于其他绝大多数分类算法,其他算法往往是首先假定分类的任务是一个未知的数学模型,然后根据训练集调整模型的参数,最后产生的模型用于进行实际的分类任务。
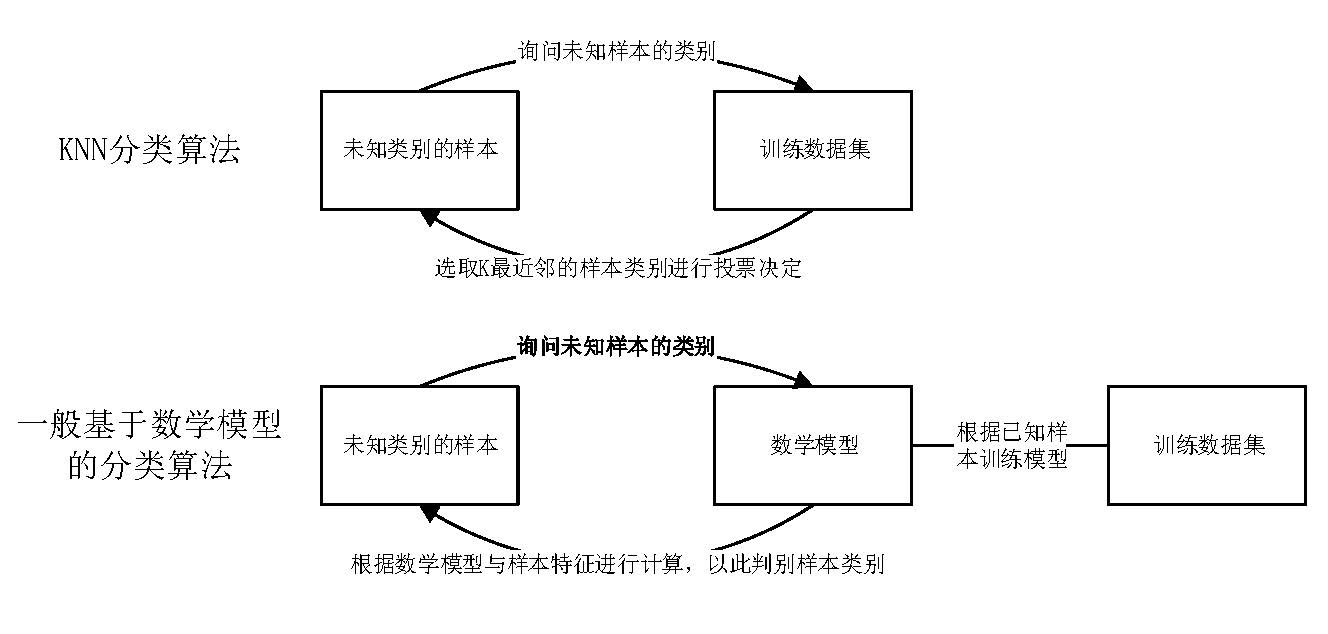
KNN分类算法的思路非常的简单、直观,我们已知一个训练集A,A中的每一个样本,都已知一个分类,现在要判断一个新的样本b的类别,就可以在特征空间中看b与A中每一个样本的距离,从中挑选出距离b最近的K个样本(K最近邻),用这K个样本的类别信息进行投票,以决定b的类别。
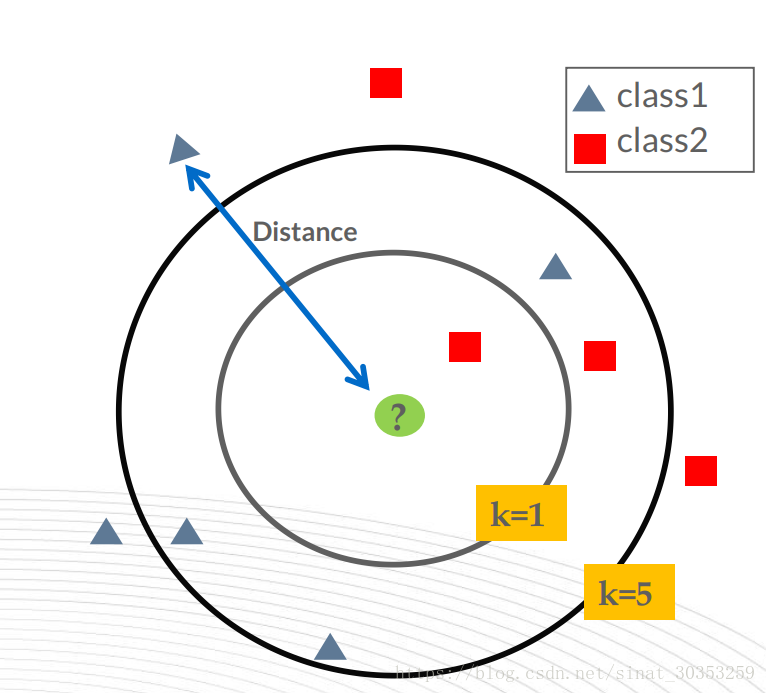
KNN的优点:算法思路简单,易于理解,易于实现,无需估计参数。
KNN的缺点:在很多情况下并不适用,包括样本极端不平衡、样本数目过多、样本数目过少、样本维度非常高等等。
但大多数的缺点都是可以通过一些策略来改进的,KNN是很常用的一种分类方法,其实还可以用于回归。

算法流程
KNN伪代码:
输入:
- 数据矩阵X,维度为[m,n],其中,m为数据中的样本数据,n为样本的特征数目;
- 标签向量y,长度为m,代表数据X中每个样本的标签;
- 不知道类别(标签)的样本s,长度为n,假设我们想通过KNN算法预测样本s的标签;
输出:s的标签;
流程:
- 计算s与X中每一个样本的距离,记为向量distance,其长度为m;
- 选择distance最小的若干个邻居,记为neighbors,其长度为K(考虑最近邻的数目,KNN的超参数之一);
- 让neighbors代表的样本根据自己在y中的值进行投票,票数最多的类别即为KNN算法预测的s的标签。
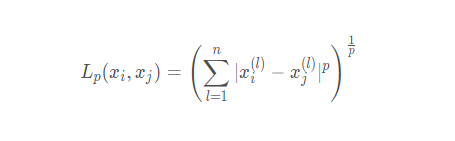
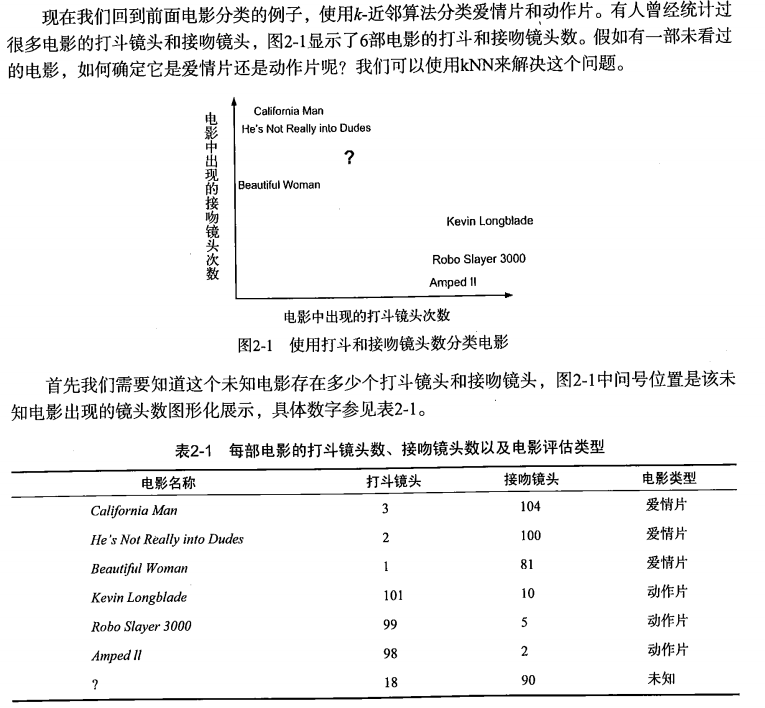
算法应用实例讲解
参考该目录下的knn-example.ipynb。
以sklearn.neighbors.KNeighborsClassifier为例,KNN分类器的参数主要有以下几个:
- n_neighbors:邻居的数量;
- weights:邻居权重的计算方式;
- p:距离计算的参数;
- metric:距离计算的方式;

