之前读了 redis设计与实现 感觉好多细节不太清楚,于是去读了源码。单机部分基本上有个比较清晰的认识了,集群部分秋招后再去看了。
先放主流程图:
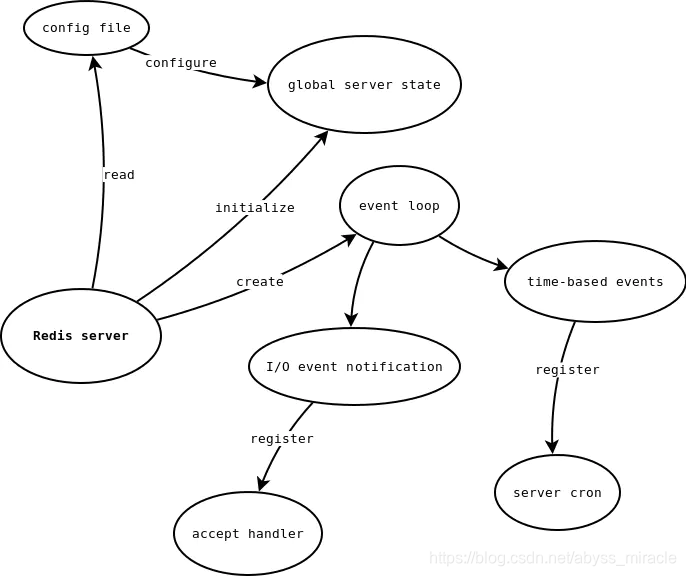
先抓主函数: mian
主要包含两部分核心函数:1.初始化服务器,分配空间 2.开启大循环
int main(int argc, char **argv){
//... 初始化库
initServerConfig();//初始化server结构 设置一堆默认端口号和默认设置
//检查用户是否指定了配置文件或配置选项
if (argc >= 2) {
//第二个参数是-v/--version 则显示版本信息,若是--help显示帮助信息。如果是其他,则标识是配置文件,则解析配置文件并更新server的配置。
//如果超过2个参数,则会判断是否是测试内存的命令,如果是,则测试内存,否则显示帮助信息。
//...
// 载入配置文件, options 是前面分析出的给定选项
loadServerConfig(configfile,options);
}
// 将服务器设置为守护进程
if (server.daemonize) daemonize();
// 创建并初始化服务器数据结构 -- !!!核心函数
initServer();
// 如果服务器是守护进程,那么创建 PID 文件
if (server.daemonize) createPidFile();
//不是集群
if (!server.sentinel_mode) {
// 从 AOF 文件或者 RDB 文件中载入数据
loadDataFromDisk();
// 启动集群?
if (server.cluster_enabled) {
//...
}
}
运行事件处理器,一直到服务器关闭为止
aeSetBeforeSleepProc(server.el,beforeSleep); //~!!! 建立事件循环
aeMain(server.el);
// 服务器关闭,停止事件循环
aeDeleteEventLoop(server.el);
return 0;
}
初始化服务器函数 initServer --main的主要步骤之一
在这个函数里面,主要读取了配置值,做了一些信号处理,创建共享对象,为数据库域申请内存等。
这里面比较重要的是创建了eventLoop,时间循环器,这个结构体(ae.h/aeEventLoop)主要包括了已注册文件事件数组、已就绪文件事件数组、事件事件列表,还有一些描述处理事件的一些信息,如执行时间等。
void initServer() {
// 设置信号处理函数 信号是一种软件层面上对中断的一种模拟,被称为软中断
signal(SIGHUP, SIG_IGN); //用SIG_IGN忽略sighup,sigpipe信号
signal(SIGPIPE, SIG_IGN); //signal功能:设置一个函数来处理信号
setupSignalHandlers();
// 设置 syslog
if (server.syslog_enabled) {
//...
}
// 初始化并创建数据结构
server.current_client = NULL;
server.clients = listCreate();
server.slaves = listCreate(); //里面都是创建的都是双向链表
//...
// 创建共享对象 -- 把一堆常用对象的SDS空间申请出来 保存在sharedObjectsStruct结构体
createSharedObjects();
adjustOpenFilesLimit();
//创建事件循环对象 目前理解:放置事件处理器和文件事件的位置 最后都到redis大循环中处理
server.el = aeCreateEventLoop(server.maxclients+REDIS_EVENTLOOP_FDSET_INCR);
server.db = zmalloc(sizeof(redisDb)*server.dbnum);
// 打开 TCP 监听端口,用于等待客户端的命令请求 Q:为啥这里一个port要bind多个fd
if (server.port != 0 &&
listenToPort(server.port,server.ipfd,&server.ipfd_count) == REDIS_ERR)
exit(1);
// 打开 UNIX 本地端口 --配置文件中可以控制是否开这个端口
//...
// 创建并初始化数据库结构
for (j = 0; j < server.dbnum; j++) {
server.db[j].dict = dictCreate(&dbDictType,NULL);
server.db[j].expires = dictCreate(&keyptrDictType,NULL);
server.db[j].blocking_keys = dictCreate(&keylistDictType,NULL);
//...
}
//订阅发布PUBSUB相关结构
//...
// 创建serverCron()事件事件 和处理方式 处理后台操作的主要方式 这边传了回调函数,还没有真跑 最后外层有个大循环跑
if(aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) {
redisPanic("Can't create the serverCron time event.");
exit(1);
}
// 为 TCP 连接关联连接应答(accept)处理器
// 用于接受并应答客户端的 connect() 调用
for (j = 0; j < server.ipfd_count; j++) {
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR) //fileEvent是除时间外所有操作的抽象
{
redisPanic(
"Unrecoverable error creating server.ipfd file event.");
}
}
//为本地socket关联应答处理器(UnixHandler)
//...
//如果AOF持久化功能打开,打开或创建一个AOF文件
//...
// 如果服务器以 cluster 模式打开,那么初始化 cluster
if (server.cluster_enabled) clusterInit();
// 初始化复制功能有关的脚本缓存
replicationScriptCacheInit();
// 初始化脚本系统
scriptingInit();
// 初始化慢查询功能
slowlogInit();
//close加入BIO的原因
//1.如果fd是特定文件描述符的最后一份拷贝,那么文件描述符相关的资源会被释放。
//2.如果fd是最后一个引用文件描述符的,并且文件描述符之前已经使用unlink进行删除,那么文件会被删除.资源释放和文件删除是非常慢的,会阻塞服务器
//fsync加入BIO的原因
//把内存中修改的文件数据同步到磁盘。调用者将被阻塞至磁盘报告同步完成。
// 初始化BIO后台系统,生成线程
bioInit();
}
服务器socket监听 – bind()和listen()的打包函数:
如果指定了端口,则会启动anetTcpServer并开始监听。监听端口默认为6379,配置文件可以指定绑定的ip和端口。对应文件描述符为ipfd。如果是设置的unixsocket,则启动anetUnixServer,对应文件描述符为sofd。
这里跟我们平时写WEB服务器程序基本一致,只是稍作了封装,流程也是通用的socket(),bind(),listen()。
//这个anetTcpServer是listenToPort的核心函数
//bind和listen的打包函数
int anetTcpServer(char *err, int port, char *bindaddr)
{
int s;
struct sockaddr_in sa;
if ((s = anetCreateSocket(err,AF_INET)) == ANET_ERR)
return ANET_ERR;
memset(&sa,0,sizeof(sa));
sa.sin_family = AF_INET;
sa.sin_port = htons(port);
sa.sin_addr.s_addr = htonl(INADDR_ANY);
if (bindaddr && inet_aton(bindaddr, &sa.sin_addr) == 0) {
anetSetError(err, "invalid bind address");
close(s);
return ANET_ERR;
}
if (anetListen(err,s,(struct sockaddr*)&sa,sizeof(sa)) == ANET_ERR)
return ANET_ERR;
return s;
}
在eventLoop中创建时间事件
即创建时间事件,这个创建过程即封装一些当前时间的信息,并且关键是把回调函数传入目标函数(在这里是把serverCron传入到了aeTimeEvent的proc成员变量上),最后把新事件放入时间事件列表(无序链表)的表头。
long long aeCreateTimeEvent(aeEventLoop *eventLoop, long long milliseconds,
aeTimeProc *proc, void *clientData,
aeEventFinalizerProc *finalizerProc)
{
// 更新时间计数器
long long id = eventLoop->timeEventNextId++;
// 创建时间事件结构
aeTimeEvent *te;
te = zmalloc(sizeof(*te));
if (te == NULL) return AE_ERR;
// 设置 ID
te->id = id;
// 设定处理事件的时间
aeAddMillisecondsToNow(milliseconds,&te->when_sec,&te->when_ms);
// 设置事件处理器
te->timeProc = proc; //这里只是传入函数
te->finalizerProc = finalizerProc;
// 设置私有数据
te->clientData = clientData;
// 将新事件放入表头
te->next = eventLoop->timeEventHead;
eventLoop->timeEventHead = te;
return id;
}
时间中断器serverCron -- 已就绪时间事件的执行函数
在Main函数中,可以发现向aeCreateTimeEvent()中传入了 serverCron函数,这个函数是redis的 时间中断器,即周期性执行,每秒调用server.hz次(也可以用run_with_period(milliseconds)修改)。
serverCron主要做很多需要做异步执行的操作。
缓存当前时间,因为在LRU和VM访问对象时都要记录访问时间,每次调用 time(NULL) 开销太大,而缓存这个时间并不会有很大影响。
更新LRUClock值,这个用于LRU策略。redisServer 有一个全局的 lruclock,该时钟每100ms更新一次。虽然lru用了22位,但是因为它最大为REDIS_LRU_CLOCK_MAX((1<<21)-1),其实是只用到21位,精度为10秒,所以它每242天会重新开始计时(跟redis源码注释中说的略有不同,注释说22位的话wrap时间为1.5年左右,但其实最大是用了21位)。而每个redisObject也有一个自己的 lruclock,这样在使用内存超过maxmemory之后就可以根据全局时钟和每个redisObject的时钟进行比较,确定是否淘汰。这里有个问题是,因为LRUClock每隔242天会重置,所以可能会导致一些很久没有访问的键它的lru更大,不过这个没有太大问题,一个键这么久没有访问,说明不太活跃。
如果达到了条件,执行BGSAVE(根据save配置来决定)和AOF文件重写。BGSAVE和AOF重写都是在子进程中执行的,这样不会影响redis主进程继续处理请求,见rdbSaveBackground()。注意,aof文件定期刷磁盘主要在beforeSleep中通过后台IO线程执行,serverCron只是在对aof刷磁盘操作推迟时做些处理。
打印统计信息。如key的数目,设置了过期时间的key的数目,连接的client数目,slave数目以及内存使用情况等,统计信息每50个循环(50*100ms=5秒)打印一次。
还有resize 哈希表,关闭超时客户端连接,后台的AOF重写,BGSAVE(如多少秒内有多少个键发生了变化执行的保存操作)。
计算LRU信息并删除一部分过期的键,如果开启了vm的话还要swap一些键值到磁盘上。
如果是slave,还需要从master同步数据。
注册文件事件
–(把一些监听端口标记为感兴趣):
接着是把文件事件加入eventLoop中。
首先,aeCreateFileEvent是用来创建文件事件的抽象,指定回到函数。
下面这里的ipfd_count默认是2,这是因为6379一共两个fd一个Ipv6一个ipv4。
//节选自initServer
//注意看内部的回调函数是acceptTcpHandler,监听fd有事件(即有新链接出现),调用acppect的封装函数,返回一个
for (j = 0; j < server.ipfd_count; j++) {
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR)
{
redisPanic(
"Unrecoverable error creating server.ipfd file event.");
}
}
aeCreateFileEvent()主要是设置aeFileEvent结构体的值,包括指定该文件事件是读还是写,根据读写事件指定对应的处理函数 rfileProc和 wfileProc。这里对tcp服务器指定的函数是 acceptTcpHandler()–创建一个TCP连接处理器。
最终都是通过 aeApiAddEvent() 函数使用 epoll_ctl() 将 tcp socket的fd注册到epoll中,客户端连接的命令处理都是在 acceptTcpHandler()中完成,这个函数后面分析。
这个aeAPiAddEvent有不同的实现方式,这里以epoll为例。

/*
* 事件状态
*/
typedef struct aeApiState {
// epoll_event 实例描述符
int epfd;
// 事件槽
struct epoll_event *events;
} aeApiState;
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
aeApiState *state = eventLoop->apidata;
struct epoll_event ee;
/* If the fd was already monitored for some event, we need a MOD
* operation. Otherwise we need an ADD operation. */
//如果 fd 没有关联任何事件,那么这是一个 ADD 操作。
//如果已经关联了某个/某些事件,那么这是一个 MOD 操作。
int op = eventLoop->events[fd].mask == AE_NONE ?
EPOLL_CTL_ADD : EPOLL_CTL_MOD;
ee.events = 0;
mask |= eventLoop->events[fd].mask; /* Merge old events */ //!!!!!!!!
if (mask & AE_READABLE) ee.events |= EPOLLIN;
if (mask & AE_WRITABLE) ee.events |= EPOLLOUT;
ee.data.u64 = 0; /* avoid valgrind warning */
ee.data.fd = fd;
if (epoll_ctl(state->epfd,op,fd,&ee) == -1) return -1; //!!!!!!!!
return 0;
}
beforeSleep
redis注册beforeSleep()函数到事件循环中,这个函数在每次进入事件循环时首先调用它,它主要做两件事:
对开启vm的情况下,将那些请求已经交换到磁盘的key的客户端解除阻塞并处理这些客户端请求。
调用 flushAppendOnlyFile() 将AOF文件刷到磁盘,最终调用的是 aof_fsync() 或者 aof_background_fsync()。
// 每次处理事件之前执行 设置一些事件处理前执行的函数
void beforeSleep(struct aeEventLoop *eventLoop) {
REDIS_NOTUSED(eventLoop);
/* Run a fast expire cycle (the called function will return
* ASAP if a fast cycle is not needed). */
// 执行一次快速的主动过期检查
if (server.active_expire_enabled && server.masterhost == NULL)
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_FAST);
/* Send all the slaves an ACK request if at least one client blocked
* during the previous event loop iteration. */
if (server.get_ack_from_slaves) {
//...
}
/* Unblock all the clients blocked for synchronous replication
* in WAIT. */
if (listLength(server.clients_waiting_acks))
processClientsWaitingReplicas();
/* Try to process pending commands for clients that were just unblocked. */
if (listLength(server.unblocked_clients))
processUnblockedClients();
/* Write the AOF buffer on disk */
// 将 AOF 缓冲区的内容写入到 AOF 文件
flushAppendOnlyFile(0);
/* Call the Redis Cluster before sleep function. */
// 在进入下个事件循环前,执行一些集群收尾工作
if (server.cluster_enabled) clusterBeforeSleep();
}
大循环 -- 运行期间永不停止
然后是aeMain(server.el)进入事件大循环
//事件处理器的主循环
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
// 如果有需要在事件处理前执行的函数,那么运行它
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
// 开始处理事件
aeProcessEvents(eventLoop, AE_ALL_EVENTS);
}
}
ProcessEvents -- 开始处理事件
聚焦到aeProcessEvents(),这里先通过计算最近到达的时间事件和现在时间的差值(time事件还有多久来),来设置文件事件的阻塞事件(file事件这次等多久),来控制优先处理文件再处理时间。
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);

这个函数用于等待事件的发生.第二个参数是用户自己开辟的一块事件数组,用于存储就绪的事件,第三个参数为这个数组的最大值,就是第二个参数事件数组的最大值,用户想监听fd的个数,第四个参数为超时时间(0表示立即返回,-1表示永久阻塞,直到有就绪事件)
文件事件的获取是通过 aeApiPoll()函数,将触发的事件插入到 server.el.fired 数组中,最底层是用epoll_wait()来获取的。
当用户调用 epoll_wait() 函数时,只会返回有事件发生的文件描述符的个数,将所有就绪的事件从内核事件表(由epfd参数指定)中拷贝到它的第二个参数events指向的数组中。
epoll_wait在调用时,在给定的timeout时间内,当在监控的所有句柄中有事件发生时,就返回用户态的进程。
(图中这个绿色的链表区域相当于缓存区,epoll_wait到时了,就拷贝过去)
开始处理所有事件
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
int processed = 0, numevents;
/* Nothing to do? return ASAP */
if (!(flags & AE_TIME_EVENTS) && !(flags & AE_FILE_EVENTS)) return 0;
/* Note that we want call select() even if there are no
* file events to process as long as we want to process time
* events, in order to sleep until the next time event is ready
* to fire. */
if (eventLoop->maxfd != -1 ||
((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
int j;
aeTimeEvent *shortest = NULL;
struct timeval tv, *tvp;
// 获取最近的时间事件
if (flags & AE_TIME_EVENTS && !(flags & AE_DONT_WAIT))
shortest = aeSearchNearestTimer(eventLoop);
if (shortest) {
// 如果时间事件存在的话
// 那么根据最近可执行时间事件和现在时间的时间差来决定文件事件的阻塞时间--阻塞time是说等多久处理文件事件先,过了就处理时间事件
long now_sec, now_ms;
/* Calculate the time missing for the nearest
* timer to fire. */
// 计算距今最近的时间事件还要多久才能达到
// 并将该时间距保存在 tv 结构中
aeGetTime(&now_sec, &now_ms);
tvp = &tv;
tvp->tv_sec = shortest->when_sec - now_sec;
if (shortest->when_ms < now_ms) {
tvp->tv_usec = ((shortest->when_ms+1000) - now_ms)*1000;
tvp->tv_sec --;
} else {
tvp->tv_usec = (shortest->when_ms - now_ms)*1000;
}
// 时间差小于 0 ,说明事件已经可以执行了,将秒和毫秒设为 0 (不阻塞)
if (tvp->tv_sec < 0) tvp->tv_sec = 0;
if (tvp->tv_usec < 0) tvp->tv_usec = 0;
} else {
// 执行到这一步,说明没有时间事件
// 那么根据 AE_DONT_WAIT 是否设置来决定是否阻塞,以及阻塞的时间长度
/* If we have to check for events but need to return
* ASAP because of AE_DONT_WAIT we need to set the timeout
* to zero */
if (flags & AE_DONT_WAIT) {
// 设置文件事件不阻塞
tv.tv_sec = tv.tv_usec = 0;
tvp = &tv;
} else {
/* Otherwise we can block */
// 文件事件可以阻塞直到有事件到达为止
tvp = NULL; /* wait forever */
}
}
// 处理文件事件,阻塞时间由 tvp 决定
numevents = aeApiPoll(eventLoop, tvp);
for (j = 0; j < numevents; j++) {
// 从已就绪数组中获取事件
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
int mask = eventLoop->fired[j].mask;
int fd = eventLoop->fired[j].fd;
int rfired = 0;
/* note the fe->mask & mask & ... code: maybe an already processed
* event removed an element that fired and we still didn't
* processed, so we check if the event is still valid. */
// 读事件
if (fe->mask & mask & AE_READABLE) {
// rfired 确保读/写事件只能执行其中一个
rfired = 1;
fe->rfileProc(eventLoop,fd,fe->clientData,mask); //读事件处理函数
}
// 写事件
if (fe->mask & mask & AE_WRITABLE) {
if (!rfired || fe->wfileProc != fe->rfileProc)
fe->wfileProc(eventLoop,fd,fe->clientData,mask); //写事件处理函数
}
processed++;
}
}
/* Check time events */
// 执行时间事件
if (flags & AE_TIME_EVENTS)
processed += processTimeEvents(eventLoop);
return processed; /* return the number of processed file/time events */
}
时间事件执行函数processTimeEvents
遍历链表,通过执行事件和现在时间的对比,找出并执行那些已经到达的事件。执行完之后看是需要保留这个事件节点(但修改when_sec改变下一次到来的时间)来达到循环执行目的,还是需要直接删除这个节点(链表方便删除)。
static int processTimeEvents(aeEventLoop *eventLoop) {
int processed = 0;
aeTimeEvent *te;
long long maxId;
time_t now = time(NULL);
// 通过重置事件的运行时间,
// 防止因时间穿插(skew)而造成的事件处理混乱
if (now < eventLoop->lastTime) {
te = eventLoop->timeEventHead;
while(te) {
te->when_sec = 0;
te = te->next;
}
}
// 更新最后一次处理时间事件的时间
eventLoop->lastTime = now;
// 遍历链表
// 执行那些已经到达的事件
te = eventLoop->timeEventHead;
maxId = eventLoop->timeEventNextId-1;
while(te) {
long now_sec, now_ms;
long long id;
// 跳过无效事件
if (te->id > maxId) {
te = te->next;
continue;
}
// 获取当前时间
aeGetTime(&now_sec, &now_ms);
// 如果当前时间等于或等于事件的执行时间,那么说明事件已到达,执行这个事件
if (now_sec > te->when_sec ||
(now_sec == te->when_sec && now_ms >= te->when_ms))
{
int retval;
id = te->id;
// 执行事件处理器,并获取返回值 !!!
retval = te->timeProc(eventLoop, id, te->clientData);
processed++;
// 记录是否有需要循环执行这个事件时间
if (retval != AE_NOMORE) {
// 是的, retval 毫秒之后继续执行这个时间事件
aeAddMillisecondsToNow(retval,&te->when_sec,&te->when_ms);
} else {
// 不,将这个事件删除
aeDeleteTimeEvent(eventLoop, id);
}
// 因为执行事件之后,事件列表可能已经被改变了
// 因此需要将 te 指针挪动回表头,继续开始执行事件
te = eventLoop->timeEventHead;
} else {
te = te->next;
}
}
return processed;
}
注意就绪数组fired的角标只是槽位序号,没啥实际意义,内部存的结构体包括fd和mask(事件类型掩码)。
小节一下:
aeProcessEvents是一个主要函数,redis的外层大循环的主要核心函数就是这个,这个函数功能是处理所有事件
它通过获取当前时间和即将到来的时间事件的时间做对比,判断时间事件是不是已经到了,根据时间差值来设置阻塞时间,即让时间事件的处理先等着等待文件事件队列。
int aeProcessEvents(aeEventLoop *eventLoop, int flags){
//1.获取最近的时间事件 并计算时间事件的到来时间,用这个到来时间设置阻塞时间tvp->tv_sec
//...
//2.处理文件事件,阻塞时间由tvp决定 aeApiPoll获取全部的发送事件的fd,放入eventLoop的fired数组中
numevents = aeApiPoll(eventLoop, tvp);
//3.一个个遍历这个fired中数组的fd,根据他的mask(事件类型)来做读/写处理
for(j = 0; j < numevents; j++)
{
if(mask标记显示是可读时间)
{
rfired = 1;
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
}
// 写事件
if (mask标记显示是可读时间)
{
if (!rfired || fe->wfileProc != fe->rfileProc)
fe->wfileProc(eventLoop,fd,fe->clientData,mask);
}
}
//4.开始管时间事件
if(有时间事件)
processed += processTimeEvents(eventLoop);
return processed; //处理过的事件的数目
}
建立TCP连接的过程中发生了什么?
acceptCommonHandler() 是建立连接的主要函数,他在acceptTcpHandler()被调用,在开局的init_server中就被绑定到端口的监听socket上了。
一旦这个被监听的fd有事件发送,则说明有新的客户端在连接我们的服务器,则TcpHandler就会创建一个Tcp连接。这个创建主要干了两件事:
1. accept()连接客户端,返回一个新的socket
2.为客户端创建客户端状态
CreateClient是acceptCommonHandler的核心函数,CreateClient是除了做了一些数据结构的初始化外,最主要的就是使用aeCreateFileEvent()把传输文件的fd注册到了epoll监听范围内。并且指定了客户端传输socket的fd可读时运行的函数 – readQueryFromClient()。
小节一下:有一个监听fd,传入eventLoop被标记成一个文件事件的可连接类型。可连接类型用连接处理器来处理,连接处理器创建了一个TCP连接,并且返回一个用于传输的fd。用于传输的fd被加入eventLoop被标记为可读/可写事件,被指定用可读/可写请求处理器来指定。
void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {
redisClient *c = (redisClient*) privdata;
// 设置服务器的当前客户端
server.current_client = c;
//一堆更新C的状态,如峰值之类的
//...
// 读入内容到查询缓存 从客户端传输数据的fd中读取,全部存放到Client结构体的querybuf缓冲区(Client结构体挂载在Server下)
nread = read(fd, c->querybuf+qblen, readlen);
if(nread == -1){
//读取出错了报错
}
if(nread){
// 根据内容,更新查询缓冲区(SDS) free 和 len 属性
// 并将 '\0' 正确地放到内容的最后
sdsIncrLen(c->querybuf,nread);
// 记录服务器和客户端最后一次互动的时间
c->lastinteraction = server.unixtime;
// 如果客户端是 master 的话,更新它的复制偏移量
if (c->flags & REDIS_MASTER) c->reploff += nread;
}
if (sdslen(c->querybuf) > server.client_max_querybuf_len) {
// 查询缓冲区长度超出服务器最大缓冲区长度
// 清空缓冲区并释放客户端
}
// 从查询缓存读取并解析客户端的原始命令字符串并将命令参数设置到 redisClient->argv 数组中,命令参数是 redisObject 类型的结构体
// 函数会执行到缓存中的所有内容都被处理完为止
processInputBuffer(c); //核心函数!!!!!!!!!!!!!!!
}
redis服务器解析客户端输入的命令
通过上面代码,我们可以知道readQueryFromClient()读取客户端请求,主要做了一些这样的事情:
1)服务器的对应client结构体字段的数值更新
2)从客户端的具体传输数据fd读取命令到服务器的对应client结构体的缓冲区中
3)开始处理命令 – processInputBuffer()
所以我们聚焦到 processInputBuffer()如何执行命令:
void processInputBuffer(redisClient *c) {
//这个大循环用来尽可能读出缓冲区中内容,如果读不完,会有内容滞留在缓冲区,等待下一次循环来读取
while(sdslen(c->querybuf)){
//上来做了一堆状态检查,排除了一些客户端暂停、阻塞等状态
//判断命令类型
if (!c->reqtype) {
if (c->querybuf[0] == '*') {
// 多条查询
c->reqtype = REDIS_REQ_MULTIBULK;
} else {
// 内联查询
c->reqtype = REDIS_REQ_INLINE;
}
// 将缓冲区中的内容转换成命令,以及命令参数
if (c->reqtype == REDIS_REQ_INLINE) {
if (processInlineBuffer(c) != REDIS_OK) break;
} else if (c->reqtype == REDIS_REQ_MULTIBULK) {
if (processMultibulkBuffer(c) != REDIS_OK) break; //把缓冲区内容转化成可被redis快速识别的命令
//主要存放在Client结构体下argv(参数个数)和argc(具体命令字段)链表中
} else {
redisPanic("Unknown request type");
}
/* Multibulk processing could see a <= 0 length. */
if (c->argc == 0) {
resetClient(c);
} else {
/* Only reset the client when the command was executed. */
// 执行命令,并重置客户端
if (processCommand(c) == REDIS_OK) //!!!!!!!!!!!!!执行命令 核心函数
resetClient(c);
}
}
}
执行命令
命令类型有两种,我们通过 redis-cli 发送的命令类型为 REDIS_REQ_MULTIBULK,这种命令以*开头,符合 redis protocol,调用processMultibulkBuffer()函数处理。另外一种命令是 REDIS_REQ_INLINE,这种命令是你通过其他工具连接的时候发的,比如通过 telnet localhost 6379,这种命令是直接的原生字符串,没有使用 redis协议封装客户端命令。
processMultibulkBuffer()主要就是个字符串操作函数,这边略写。
样例: *3\r\n$3\r\nSET\r\n$3\r\nMSG\r\n$5\r\nHELLO\r\n
- 将被转换为:
- argv[0] = SET
- argv[1] = MSG
- argv[2] = HELLO
我们看到在processInputBuffer()的最后,会调用processCommand()实际性的处理命令。
processCommand是一个外层接口函数,里面主要负责检查命令合法性。真正的执行核心函数是call()。
int processCommand(redisClient *c){
//特别处理quit命令
//查找命令,并进行命令合法性检查,以及命令参数个数检查
c->cmd = c->lastcmd = lookupCommand(c->argv[0]->ptr);
//检查认证信息,如果redis配置了密码而客户端请求没有通过认证就发命令,返回错误
//如果开启了集群模式,在这里转向(处理键入的kv不是本节点处理的slot,转向)
// 如果设置了最大内存,那么检查内存是否超过限制,并做相应的操作
// 如果内存已超过限制,那么尝试通过删除过期键来释放内存
// 如果即将要执行的命令可能占用大量内存(REDIS_CMD_DENYOOM)
// 并且前面的内存释放失败的话
// 那么向客户端返回内存错误
// 如果这个服务器是一个只读 slave 的话,那么拒绝执行写命令
// 在订阅于发布模式的上下文中,只能执行订阅和退订相关的命令
================以上都是各种检查======================
if (c->flags & REDIS_MULTI &&
c->cmd->proc != execCommand && c->cmd->proc != discardCommand &&
c->cmd->proc != multiCommand && c->cmd->proc != watchCommand)
{
// 在事务上下文中
// 除 EXEC 、 DISCARD 、 MULTI 和 WATCH 命令之外
// 其他所有命令都会被入队到事务队列中
queueMultiCommand(c);
addReply(c,shared.queued);
} else {
// 执行命令
call(c,REDIS_CALL_FULL); // !!!!!真正执行的核心函数!!!!!
c->woff = server.master_repl_offset;
// 处理那些解除了阻塞的键
if (listLength(server.ready_keys))
handleClientsBlockedOnLists();
}
}
call()是实际执行命令的函数,它的大致实现如下:
void call(redisClient *c,int flags){
//记录命令开始时间,记录开始执行前的flag
//如果可以的话,将命令发送到MONITOR
//call the command
//操作一波dirty和一些时间
// 执行实现函数
c->cmd->proc(c);
//如有需要,将命令放到slowlog里面
if (flags & REDIS_CALL_SLOWLOG && c->cmd->proc != execCommand)
slowlogPushEntryIfNeeded(c->argv,c->argc,duration);
//更新命令统计信息
//将命令复制到AOF和slave节点
if (flags & REDIS_CALL_PROPAGATE){
//...
if (dirty)
flags |= (REDIS_PROPAGATE_REPL | REDIS_PROPAGATE_AOF);
if (flags != REDIS_PROPAGATE_NONE)
propagate(c->cmd,c->db->id,c->argv,c->argc,flags); //同步传送命令到AOF/slave中
}
//...
return server.stat_numcommands++; //已经执行的指令数量
}
回复命令
执行之后,响应数据通过 addReply() 中会调用 prepareClientToWrite()把回复发送给客户端,这个addReply主要功能是:
1.把客户端的写处理器注册到事件循环
2.做一些优化之后把数据写到c->buf缓冲区
void addReply(redisClient *c, robj *obj) {
// 为客户端安装写处理器到事件循环
if (prepareClientToWrite(c) != REDIS_OK)
return;
/*这里做了优化如果对象的编码为 RAW(SDS的一种,大于39字节的字符串) ,并且静态缓冲区中有空间
那么就可以在不弄乱内存页的情况下,将对象发送给客户端。*/
// 尝试复制内容到c->buf中,可以避免内存分配
if (_addReplyToBuffer(c,obj->ptr,sdslen(obj->ptr)) != REDIS_OK){
// 如果 c->buf 中的空间不够,就复制到 c->reply 链表中
// 可能会引起内存分配
_addReplyObjectToList(c,obj);
} else if (obj->encoding == REDIS_ENCODING_INT) {
//一堆字符串操作,主要是把不同位数的整数转成字符串
}
// 保存到缓存中 c->buf缓存区或c->reply链表
if (_addReplyToBuffer(c,obj->ptr,sdslen(obj->ptr)) != REDIS_OK) //用buf放不下
_addReplyObjectToList(c,obj); //用链表存储
decrRefCount(obj);
}
上面的19和20行中的两个函数,负责把回复写到缓存区中
_addReplyToBuffer()和_addReplyObjectToList()写入到响应缓存redisClient->buf和redisClient->reply中。这里的buf和reply两个地方都是用于写响应缓存的,如果响应的总的数据长度(响应数据长度+数据本身)小于 REDIS_REPLY_CHUNK_BYTES(7500)字节,则用buf数组缓存数据,否则用reply链表来存储数据。
prepareClientToWrite()就是将客户端连接的fd加入到事件循环中,事件类型为AE_WRITABLE(EPOLLOUT)。这个函数在每次向客户端发送数据时都会被调用,当客户端可以接收新数据时(通常情况下都是这样),函数返回 REDIS_OK ,
并将写处理器(write handler)安装到事件循环中,这样当套接字可写时,新数据就会被写入。对于那些不应该接收新数据的客户端,比如伪客户端、 master 以及 未 ONLINE 的 slave ,或者写处理器安装失败时,函数返回 REDIS_ERR 。通常在每个回复被创建时调用,如果函数返回 REDIS_ERR ,那么没有数据会被追加到输出缓冲区。
int prepareClientToWrite(redisClient *c) {
// LUA 脚本环境所使用的伪客户端总是可写的
if (c->flags & REDIS_LUA_CLIENT) return REDIS_OK;
// 客户端是主服务器并且不接受查询,
// 那么它是不可写的,出错
if ((c->flags & REDIS_MASTER) &&
!(c->flags & REDIS_MASTER_FORCE_REPLY)) return REDIS_ERR;
// 无连接的伪客户端总是不可写的
if (c->fd <= 0) return REDIS_ERR; /* Fake client */
// 一般情况,为客户端套接字安装写处理器到事件循环
if (c->bufpos == 0 && listLength(c->reply) == 0 &&
(c->replstate == REDIS_REPL_NONE ||
c->replstate == REDIS_REPL_ONLINE) &&
aeCreateFileEvent(server.el, c->fd, AE_WRITABLE,sendReplyToClient, c) == AE_ERR) //注册写事件
return REDIS_ERR;
return REDIS_OK;
}
这里可写事件绑定的是sendReplyToClient()处理器,主要功能是从响应缓存读取数据并发送响应数据给客户端,然后移除写事件。命令执行完成后,redis会重置redisClient对象并接收后续命令。
void sendReplyToClient(aeEventLoop *el, int fd, void *privdata, int mask) {
redisClient *c = privdata;
int nwritten = 0, totwritten = 0, objlen;
size_t objmem;
robj *o;
REDIS_NOTUSED(el);
REDIS_NOTUSED(mask);
// 一直循环,直到回复缓冲区为空
// 或者指定条件满足为止
while(c->bufpos > 0 || listLength(c->reply)) {
//处理c->buf缓冲区 bufpos是记录了偏移量大小
if (c->bufpos > 0) {
// c->bufpos > 0
// 写入内容到套接字
// c->sentlen 是用来处理 short write 的
// 当出现 short write ,导致写入未能一次完成时,
// c->buf+c->sentlen 就会偏移到正确(未写入)内容的位置上。
nwritten = write(fd,c->buf+c->sentlen,c->bufpos-c->sentlen);
// 出错则跳出
if (nwritten <= 0) break;
// 成功写入则更新写入计数器变量
c->sentlen += nwritten;
totwritten += nwritten;
/* If the buffer was sent, set bufpos to zero to continue with
* the remainder of the reply. */
// 如果缓冲区中的内容已经全部写入完毕
// 那么清空客户端的两个计数器变量
if (c->sentlen == c->bufpos) {
c->bufpos = 0;
c->sentlen = 0;
}
}
//处理链表
else {
// listLength(c->reply) != 0
// 取出位于链表最前面的对象
o = listNodeValue(listFirst(c->reply));
objlen = sdslen(o->ptr);
objmem = getStringObjectSdsUsedMemory(o);
// 略过空对象
if (objlen == 0) {
listDelNode(c->reply,listFirst(c->reply));
c->reply_bytes -= objmem;
continue;
}
// 写入内容到套接字
// c->sentlen 是用来处理 short write 的
// 当出现 short write ,导致写入未能一次完成时,
// c->buf+c->sentlen 就会偏移到正确(未写入)内容的位置上。
nwritten = write(fd, ((char*)o->ptr)+c->sentlen,objlen-c->sentlen);
// 写入出错则跳出
if (nwritten <= 0) break;
// 成功写入则更新写入计数器变量
c->sentlen += nwritten;
totwritten += nwritten;
/* If we fully sent the object on head go to the next one */
// 如果缓冲区内容全部写入完毕,那么删除已写入完毕的节点
if (c->sentlen == objlen) {
listDelNode(c->reply,listFirst(c->reply));
c->sentlen = 0;
c->reply_bytes -= objmem;
}
}
/* 为了避免一个非常大的回复独占服务器,当写入的总数量大于 REDIS_MAX_WRITE_PER_EVENT ,
* 临时中断写入,将处理时间让给其他客户端,剩余的内容等下次写入就绪再继续写入。不过,如果服务器的内存占用已经超过了限制,
* 那么为了将回复缓冲区中的内容尽快写入给客户端,然后释放回复缓冲区的空间来回收内存,
* 这时即使写入量超过了 REDIS_MAX_WRITE_PER_EVENT ,程序也继续进行写入*/
if (totwritten > REDIS_MAX_WRITE_PER_EVENT &&
(server.maxmemory == 0 ||
zmalloc_used_memory() < server.maxmemory)) break;
}
// 写入出错检查
if (nwritten == -1) {
if (errno == EAGAIN) {
nwritten = 0;
} else {
redisLog(REDIS_VERBOSE,
"Error writing to client: %s", strerror(errno));
freeClient(c);
return;
}
}
if (totwritten > 0) {
//对于代表master的客户端,我们不将发送数据计算为交互
//因为我们总是发送REPLCONF ACK命令,这需要一些时间来填充套接字输出缓冲区。我们只依赖收到的数据/ping信号进行超时检测
if (!(c->flags & REDIS_MASTER)) c->lastinteraction = server.unixtime;
}
//全部读完了缓冲区的数据
if (c->bufpos == 0 && listLength(c->reply) == 0) {
c->sentlen = 0;
// 删除 write handler
aeDeleteFileEvent(server.el,c->fd,AE_WRITABLE); //将fd从Mask指定的监听队列中移除出去
/* Close connection after entire reply has been sent. */
// 如果指定了写入之后关闭客户端 FLAG ,那么关闭客户端
if (c->flags & REDIS_CLOSE_AFTER_REPLY) freeClient(c);
}
}
call函数中,还有对同步写入aof或者slave中的判断函数。如需要对aof进行写入,则调用feedAppendOnlyFile()
void feedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) {
sds buf = sdsempty();
robj *tmpargv[3];
// 使用 SELECT 命令,显式设置数据库,确保之后的命令被设置到正确的数据库
if (dictid != server.aof_selected_db) {
char seldb[64];
//还原文件格式
snprintf(seldb,sizeof(seldb),"%d",dictid);
buf = sdscatprintf(buf,"*2\r\n$6\r\nSELECT\r\n$%lu\r\n%s\r\n",
(unsigned long)strlen(seldb),seldb);
server.aof_selected_db = dictid;
}
// EXPIRE 、 PEXPIRE 和 EXPIREAT 命令
if (cmd->proc == expireCommand || cmd->proc == pexpireCommand ||
cmd->proc == expireatCommand) {
//...
} else if (cmd->proc == setexCommand || cmd->proc == psetexCommand) {
// 其他命令
} else {
buf = catAppendOnlyGenericCommand(buf,argc,argv); //根据传入的命令和命令参数,将它们还原成协议格式。
}
//将命令追加到 AOF 缓存中,在重新进入事件循环之前,这些命令会被冲洗到磁盘上,并向客户端返回一个回复。
if (server.aof_state == REDIS_AOF_ON)
server.aof_buf = sdscatlen(server.aof_buf,buf,sdslen(buf)); //!!!!!!!写入到aof缓冲区
//如果 BGREWRITEAOF 正在进行,那么我们还需要将命令追加到重写缓存中,从而记录当前正在重写的 AOF 文件和数据库当前状态的差异。
if (server.aof_child_pid != -1)
aofRewriteBufferAppend((unsigned char*)buf,sdslen(buf));
// 释放
sdsfree(buf);
}
如果有slave连接到该服务器,则通过 replicationFeedSlaves() 将命令发给slave服务器(slave同步时master会先通过BGSAVE保存一份rdb并发送给slave,后续的命令同步则由replicationFeedSlaves()来完成)。
如果有客户端通过 monitor 命令连接到该服务器,则还要通过 replicationFeedMonitors() 发送命令字符串过去,并带上命令时间戳。