深入理解SPI机制
一、什么是SPI
SPI ,全称为 Service Provider Interface,是一种服务发现机制。它通过在ClassPath路径下的META-INF/services文件夹查找文件,自动加载文件里所定义的类。
这一机制为很多框架扩展提供了可能,比如在Dubbo、JDBC中都使用到了SPI机制。我们先通过一个很简单的例子来看下它是怎么用的。
1、小例子
首先,我们需要定义一个接口,SPIService
package com.viewscenes.netsupervisor.spi;
public interface SPIService {
void execute();
}
然后,定义两个实现类,没别的意思,只输入一句话。
package com.viewscenes.netsupervisor.spi;
public class SpiImpl1 implements SPIService{
public void execute() {
System.out.println("SpiImpl1.execute()");
}
}
----------------------我是乖巧的分割线----------------------
package com.viewscenes.netsupervisor.spi;
public class SpiImpl2 implements SPIService{
public void execute() {
System.out.println("SpiImpl2.execute()");
}
}
最后呢,要在ClassPath路径下配置添加一个文件。文件名字是接口的全限定类名,内容是实现类的全限定类名,多个实现类用换行符分隔。
文件路径如下:
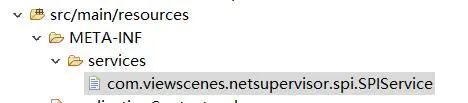
内容就是实现类的全限定类名:
com.viewscenes.netsupervisor.spi.SpiImpl1
com.viewscenes.netsupervisor.spi.SpiImpl2
2、测试
然后我们就可以通过ServiceLoader.load或者Service.providers方法拿到实现类的实例。其中,Service.providers包位于sun.misc.Service,而ServiceLoader.load包位于java.util.ServiceLoader。
public class Test {
public static void main(String[] args) {
Iterator<SPIService> providers = Service.providers(SPIService.class);
ServiceLoader<SPIService> load = ServiceLoader.load(SPIService.class);
while(providers.hasNext()) {
SPIService ser = providers.next();
ser.execute();
}
System.out.println("--------------------------------");
Iterator<SPIService> iterator = load.iterator();
while(iterator.hasNext()) {
SPIService ser = iterator.next();
ser.execute();
}
}
}
两种方式的输出结果是一致的:
SpiImpl1.execute()
SpiImpl2.execute()
--------------------------------
SpiImpl1.execute()
SpiImpl2.execute()
二、源码分析
我们就以ServiceLoader.load为例,通过源码看看它里面到底怎么做的。
1、ServiceLoader
首先,我们先来了解下ServiceLoader,看看它的类结构。
public final class ServiceLoader<S> implements Iterable<S>
//配置文件的路径
private static final String PREFIX = "META-INF/services/";
//加载的服务类或接口
private final Class<S> service;
//已加载的服务类集合
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
//类加载器
private final ClassLoader loader;
//内部类,真正加载服务类
private LazyIterator lookupIterator;
}
2、Load
load方法创建了一些属性,重要的是实例化了内部类,LazyIterator。最后返回ServiceLoader的实例。
public final class ServiceLoader<S> implements Iterable<S>
private ServiceLoader(Class<S> svc, ClassLoader cl) {
//要加载的接口
service = Objects.requireNonNull(svc, "Service interface cannot be null");
//类加载器
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
//访问控制器
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
//先清空
providers.clear();
//实例化内部类
LazyIterator lookupIterator = new LazyIterator(service, loader);
}
}
3、查找实现类
查找实现类和创建实现类的过程,都在LazyIterator完成。当我们调用iterator.hasNext和iterator.next方法的时候,实际上调用的都是LazyIterator的相应方法。
public Iterator<S> iterator() {
return new Iterator<S>() {
public boolean hasNext() {
return lookupIterator.hasNext();
}
public S next() {
return lookupIterator.next();
}
.......
};
}
所以,我们重点关注lookupIterator.hasNext()方法,它最终会调用到hasNextService。
private class LazyIterator implements Iterator<S>{
Class<S> service;
ClassLoader loader;
Enumeration<URL> configs = null;
Iterator<String> pending = null;
String nextName = null;
private boolean hasNextService() {
//第二次调用的时候,已经解析完成了,直接返回
if (nextName != null) {
return true;
}
if (configs == null) {
//META-INF/services/ 加上接口的全限定类名,就是文件服务类的文件
//META-INF/services/com.viewscenes.netsupervisor.spi.SPIService
String fullName = PREFIX + service.getName();
//将文件路径转成URL对象
configs = loader.getResources(fullName);
}
while ((pending == null) || !pending.hasNext()) {
//解析URL文件对象,读取内容,最后返回
pending = parse(service, configs.nextElement());
}
//拿到第一个实现类的类名
nextName = pending.next();
return true;
}
}
4、创建实例
当然,调用next方法的时候,实际调用到的是,lookupIterator.nextService。它通过反射的方式,创建实现类的实例并返回。
private class LazyIterator implements Iterator<S>{
private S nextService() {
//全限定类名
String cn = nextName;
nextName = null;
//创建类的Class对象
Class<?> c = Class.forName(cn, false, loader);
//通过newInstance实例化
S p = service.cast(c.newInstance());
//放入集合,返回实例
providers.put(cn, p);
return p;
}
}
看到这儿,我想已经很清楚了。获取到类的实例,我们自然就可以对它为所欲为了!
三、JDBC中的应用
1、加载
把目光回到DriverManager类,它在静态代码块里面做了一件比较重要的事。很明显,它已经通过SPI机制, 把数据库驱动连接初始化了。
public class DriverManager {
static {
loadInitialDrivers();
println("JDBC DriverManager initialized");
}
}
具体过程还得看loadInitialDrivers,它在里面查找的是Driver接口的服务类,所以它的文件路径就是:META-INF/services/java.sql.Driver。
public class DriverManager {
private static void loadInitialDrivers() {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
//很明显,它要加载Driver接口的服务类,Driver接口的包为:java.sql.Driver
//所以它要找的就是META-INF/services/java.sql.Driver文件
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
try{
//查到之后创建对象
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
}
}
那么,这个文件哪里有呢?我们来看MySQL的jar包,就是这个文件,文件内容为:com.mysql.cj.jdbc.Driver。
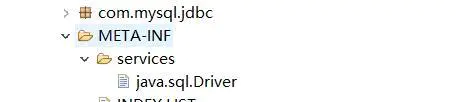
2、创建实例
上一步已经找到了MySQL中的com.mysql.cj.jdbc.Driver全限定类名,当调用next方法时,就会创建这个类的实例。它就完成了一件事,向DriverManager注册自身的实例。
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
static {
try {
//注册
//调用DriverManager类的注册方法
//往registeredDrivers集合中加入实例
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
public Driver() throws SQLException {
// Required for Class.forName().newInstance()
}
}
3、创建Connection
在DriverManager.getConnection()方法就是创建连接的地方,它通过循环已注册的数据库驱动程序,调用其connect方法,获取连接并返回。
private static Connection getConnection(
String url, java.util.Properties info, Class<?> caller) throws SQLException {
//registeredDrivers中就包含com.mysql.cj.jdbc.Driver实例
for(DriverInfo aDriver : registeredDrivers) {
if(isDriverAllowed(aDriver.driver, callerCL)) {
try {
//调用connect方法创建连接
Connection con = aDriver.driver.connect(url, info);
if (con != null) {
return (con);
}
}catch (SQLException ex) {
if (reason == null) {
reason = ex;
}
}
} else {
println(" skipping: " + aDriver.getClass().getName());
}
}
}
4、再扩展
既然我们知道JDBC是这样创建数据库连接的,我们能不能再扩展一下呢?如果我们自己也创建一个java.sql.Driver文件,自定义实现类MyDriver,那么,在获取连接的前后就可以动态修改一些信息。
还是先在项目ClassPath下创建文件,文件内容为自定义驱动类
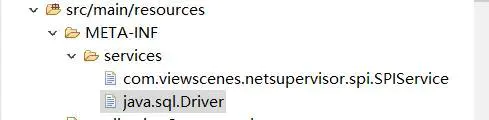
我们的MyDriver实现类,继承自MySQL中的NonRegisteringDriver,还要实现java.sql.Driver接口。这样,在调用connect方法的时候,就会调用到此类,但实际创建的过程还靠MySQL完成。
package com.viewscenes.netsupervisor.spi
public class MyDriver extends NonRegisteringDriver implements Driver{
static {
try {
java.sql.DriverManager.registerDriver(new MyDriver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
public MyDriver()throws SQLException {}
public Connection connect(String url, Properties info) throws SQLException {
System.out.println("准备创建数据库连接.url:"+url);
System.out.println("JDBC配置信息:"+info);
info.setProperty("user", "root");
Connection connection = super.connect(url, info);
System.out.println("数据库连接创建完成!"+connection.toString());
return connection;
}
}
--------------------输出结果---------------------
准备创建数据库连接.url:jdbc:mysql:///consult?serverTimezone=UTC
JDBC配置信息:{user=root, password=root}
数据库连接创建完成!com.mysql.cj.jdbc.ConnectionImpl@7cf10a6f
问题:
(1)如何保证Drivermanager使用的是自定义的MyDirver而不是mysql的Driver呢? getConnection的时候都可以获取connection
Connection con = aDriver.driver.connect(url, info);
if (con != null) {
// Success!
println("getConnection returning " + aDriver.driver.getClass().getName());
return (con);
}
别人的回答:
应该和类加载顺序有关吧。应用项目中的类加载顺序优先级高于jar包中的类,所以MyDriver会优先于com.mysql.cj.jdbc.Driver调用DriverManager的registerDriver()方法,而DriverManager的registeredDrivers是一个CopyOnWriteArrayList实例,所以getConnection方法内部的for循环,第一个可用的driver应该是项目中自定义的MyDriver
jdbc的 spi 服务机制
SPI 在jdbc driver的运用
这几天在看java 类加载机制,看到 spi 服务机制破坏了双亲委派模型,特地研究了下典型的 spi 服务 jdbc 驱动
首先运行一下代码,查看 mysql jdbc 驱动的类加载(maven 项目已经引进 jdbc 驱动依赖,版本为5.1.41)
public static void main(String[] args)
{
Enumeration<Driver> drivers = DriverManager.getDrivers();
Driver driver;
while (drivers.hasMoreElements())
{
driver = drivers.nextElement();
System.out.println(driver.getClass() + "------" + driver.getClass().getClassLoader());
}
System.out.println(DriverManager.class.getClassLoader());
}
输出结果如下:
class com.mysql.jdbc.Driver------sun.misc.Launcher$AppClassLoader@2a139a55
class com.mysql.fabric.jdbc.FabricMySQLDriver------sun.misc.Launcher$AppClassLoader@2a139a55
null
可以看到代码中并没有调用 Class.forName(“”)的代码,但DriverManager中已经加载了两个 jdbc 驱动,而却这两个驱动都是使用的应用类加载器(AppClassLoader)加载的,而DriverManager本身的类加载器确是 null 即BootstrapClassLoader,按照双亲委派模型的规则,委派链如下:
SystemApp class loader -> Extension class loader -> Bootstrap class loader
,父加载器BootstrapClassLoader是无法找到AppClassLoader加载的类的,此时使用了线程上下文加载器,Thread.currentThread().setContextClassLoader()可以将委派链左边的类加载器,设置为线程上下文加载器,此时右边的加载器就可以使用线程上下文加载器委托子加载器加载类
注意并不是所有版本的 jdbc 驱动都实现了 spi 服务,应该是5.1.6及之后的版本才实现了这种服务,之前的版本还是需要手动调用 Class.forName 方法来加载驱动,还有好像 ojdbc 的驱动均没有实现 spi 服务
自己尝试实现一个简单的 jdbc 驱动(仅仅实现了类加载的部分)
搞清楚了 spi 服务于 DriverManager 加载的过程,我们可以自己尝试实现一个简单的 jdbc 驱动(仅仅实现了类加载的部分)
使用 maven 工程,新建类com.lcy.mysql.Driver
public class Driver implements java.sql.Driver
{
static
{
try
{
DriverManager.registerDriver(new com.lcy.mysql.Driver());
}
catch (SQLException e)
{
throw new RuntimeException("register driver fail");
}
}
@Override
public Connection connect(String url, Properties info)
throws SQLException
{
// TODO Auto-generated method stub
return null;
}
@Override
public boolean acceptsURL(String url)
throws SQLException
{
// TODO Auto-generated method stub
return false;
}
@Override
public DriverPropertyInfo[] getPropertyInfo(String url, Properties info)
throws SQLException
{
// TODO Auto-generated method stub
return null;
}
@Override
public int getMajorVersion()
{
// TODO Auto-generated method stub
return 0;
}
@Override
public int getMinorVersion()
{
// TODO Auto-generated method stub
return 0;
}
@Override
public boolean jdbcCompliant()
{
// TODO Auto-generated method stub
return false;
}
@Override
public Logger getParentLogger()
throws SQLFeatureNotSupportedException
{
// TODO Auto-generated method stub
return null;
}
}
仅仅写了一个初始化方法,其他方法均使用默认空实现,在 src/mian/resources 目录下新建文件 /META-INF/services/java.sql.Driver 填入内容com.lcy.mysql.Driver 打包发布
在之前的文章开始的测试工程中引入工程依赖(如果是同一工程,直接运行即可),运行可以看到结果如下:
class com.lcy.mysql.Driver------sun.misc.Launcher$AppClassLoader@2a139a55
class com.mysql.jdbc.Driver------sun.misc.Launcher$AppClassLoader@2a139a55
class com.mysql.fabric.jdbc.FabricMySQLDriver------sun.misc.Launcher$AppClassLoader@2a139a55
null
可以看到,已经加载了我们自定义的com.lcy.mysql.Driver(虽然这个加载器没有实现任何功能,但测试 spi 机制的目的已经实现)
JDBC如何区分多个驱动?
一个项目里边很可能会即连接MySQL,又连接Oracle,这样在一个工程里边就存在了多个驱动类,那么这些驱动类又是怎么区分的呢?
关键点就在于getConnection的步骤,DriverManager.getConnection中会遍历所有已经加载的驱动实例去创建连接,当一个驱动创建连接成功时就会返回这个连接,同时不再调用其他的驱动实例。DriverManager关键代码如下:
private static Connection getConnection(
//.....
for(DriverInfo aDriver : registeredDrivers) {
if(isDriverAllowed(aDriver.driver, callerCL)) {
try {
println(" trying " + aDriver.driver.getClass().getName());
Connection con = aDriver.driver.connect(url, info);
if (con != null) {
// Success!
println("getConnection returning " + aDriver.driver.getClass().getName());
return (con);
}
} catch (SQLException ex) {
if (reason == null) {
reason = ex;
}
}
} else {
println(" skipping: " + aDriver.getClass().getName());
}
}
//......
是不是每个驱动实例都真真实实的要尝试建立连接呢?不是的!
每个驱动实例在getConnetion的第一步就是按照url判断是不是符合自己的处理规则,是的话才会和db建立连接。比如,MySQL驱动类中的关键代码:
public boolean acceptsURL(String url) throws SQLException {
return (parseURL(url, null) != null);
}
public Properties parseURL(String url, Properties defaults)
throws java.sql.SQLException {
Properties urlProps = (defaults != null) ? new Properties(defaults)
: new Properties();
if (url == null) {
return null;
}
if (!StringUtils.startsWithIgnoreCase(url, URL_PREFIX)
&& !StringUtils.startsWithIgnoreCase(url, MXJ_URL_PREFIX)
&& !StringUtils.startsWithIgnoreCase(url,
LOADBALANCE_URL_PREFIX)
&& !StringUtils.startsWithIgnoreCase(url,
REPLICATION_URL_PREFIX)) { //$NON-NLS-1$
return null;
}
//......
参考文章:
1、https://www.jianshu.com/p/3a3edbcd8f24
2、https://www.jianshu.com/p/f6653220a3e7