一、概要
1. 概念
- 模拟客户端
- 发送网络请求
- 接受请求
- 按规则抓取信息
- 的程序
2. 作用
- 数据采集(评论、信息)
- 软件测试(selenium)
- 抢票投票
- 安全(漏洞扫描软件)
3. 分类
数量:
- 通用爬虫:引擎 (无上限
- 聚焦爬虫:抢票(专门抓某一网站
是否获取数据:
- 功能性爬虫:投票、点赞
- 数据增量爬虫
url是否变化
- url变化,数据变化
- url不变,数据变化
4. 流程
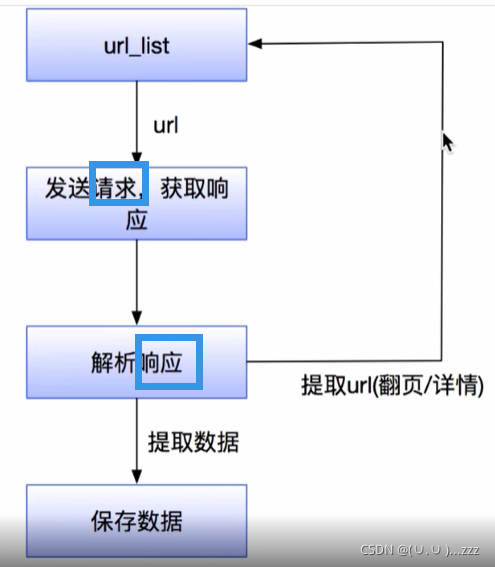
5. http协议复习
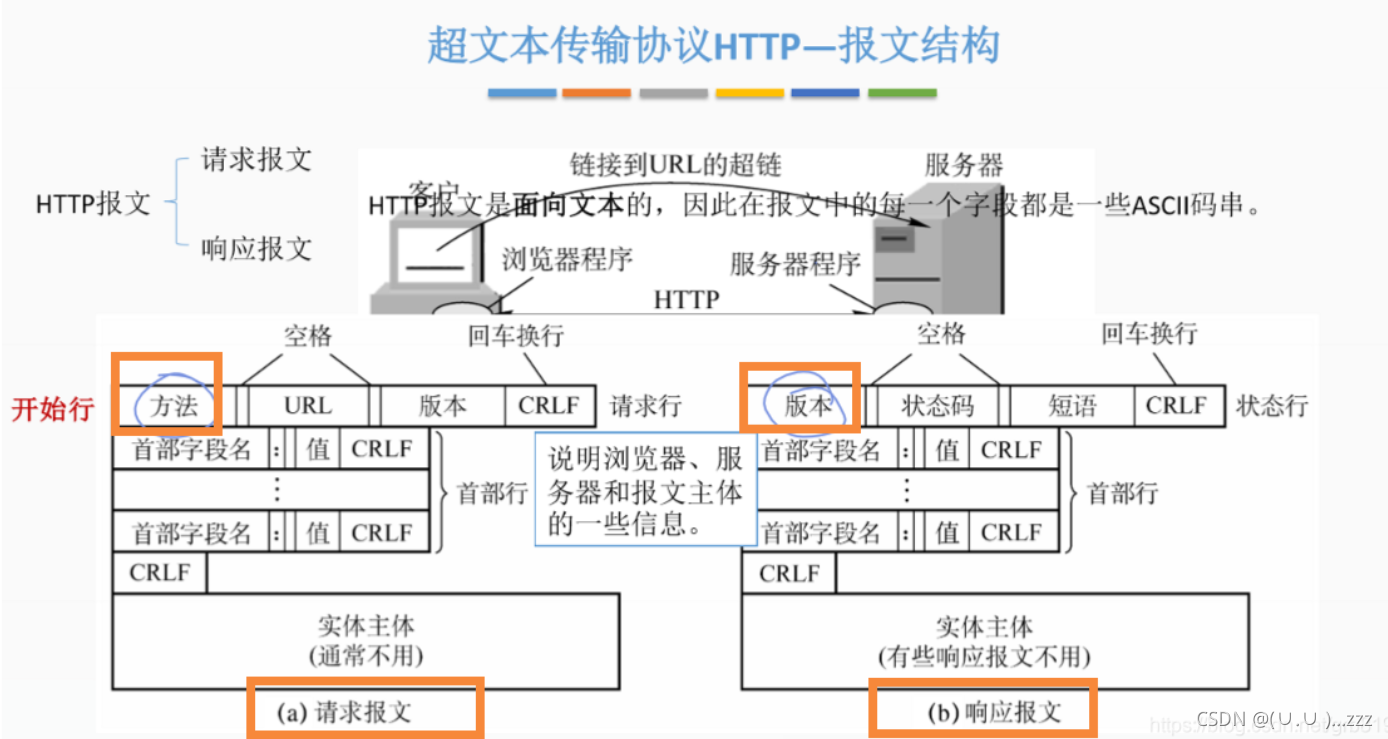
-
超文本传输协议:明文传输—— 默认端口80
-
https:http+SSL安全套接字层——默认端口443
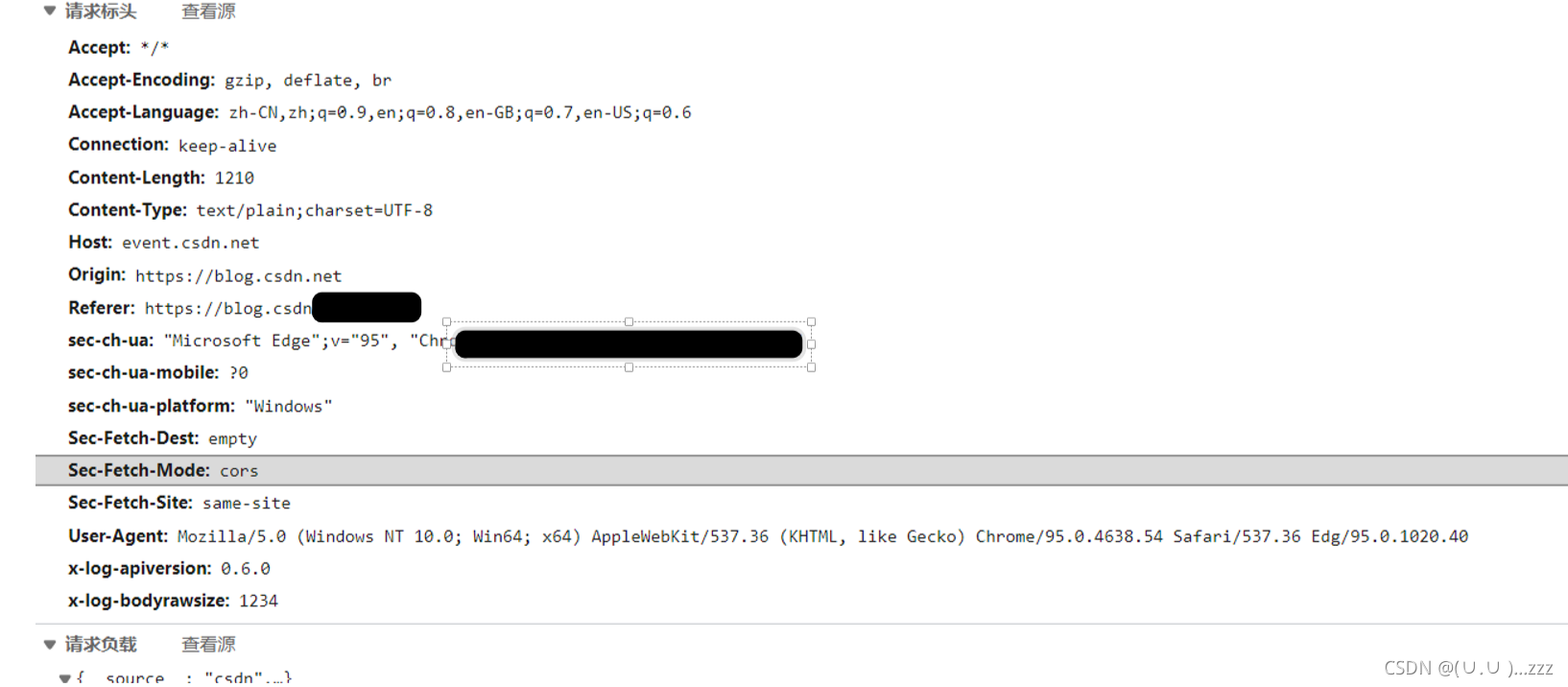
6. 关注请求头、请求体
做伪装,必须用到响应头
Request Headers:
Content-Type
Host 主机端口号
Connection 连接类型
User-agent 浏览器名称
Referer 页面跳转
Cookie
Authorization
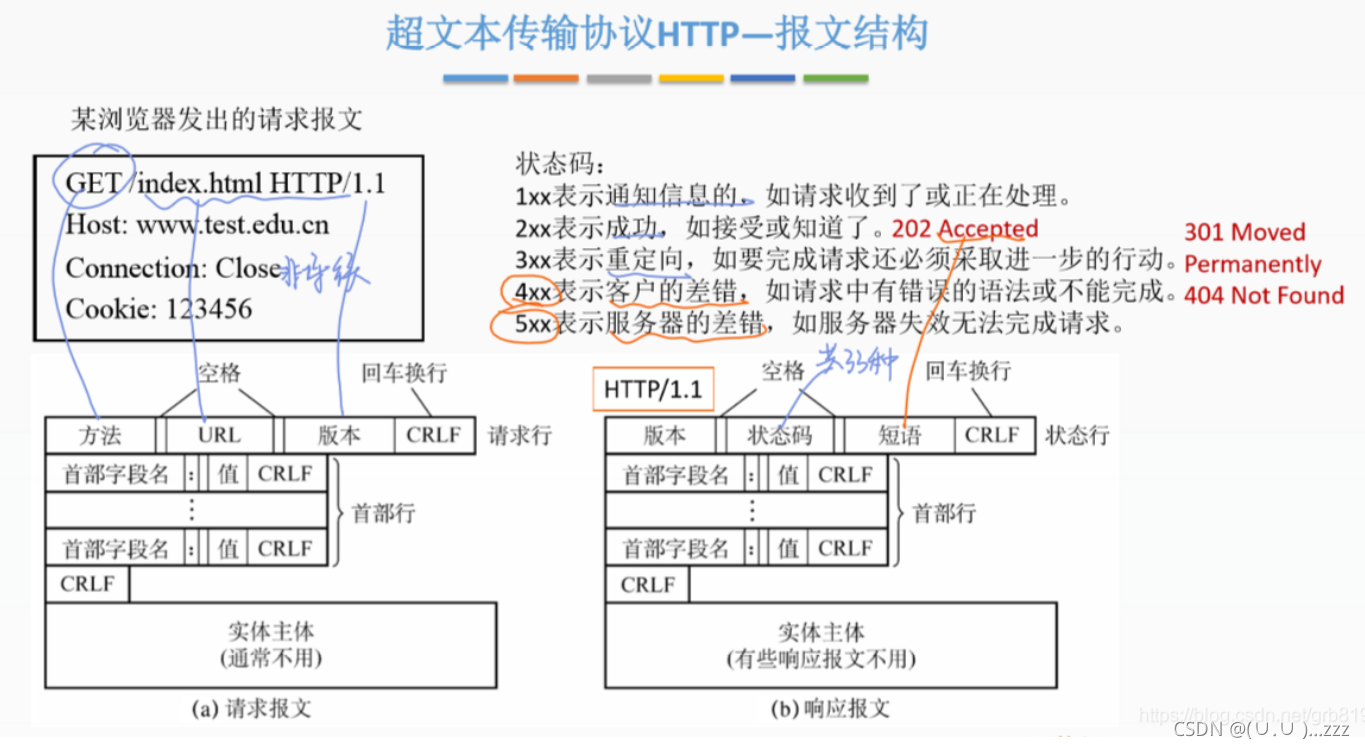
7. 状态响应码
我们在学习web知识的时候就已经学过了状态码的相关知识,我们知道这是服务器给我的相关反馈,我们在学习的时候就被教育说应该将真实情况反馈给客户端,但是在爬虫中,可能该站点的开发人员或者运维人员为了阻止数据被爬虫轻易获取,可能在状态码上做手脚,也就是说返回的状态码并不一定就是真实情况,比如:服务器已经识别出你是爬虫,但是为了让你疏忽大意,所以照样返回状态码200,但是响应体重并没有数据。
所有的状态码都不可信,一切以是否从抓包得到的响应中获取到数据为准,渲染后element的结果也不可信
8. 浏览器运行 和 爬虫
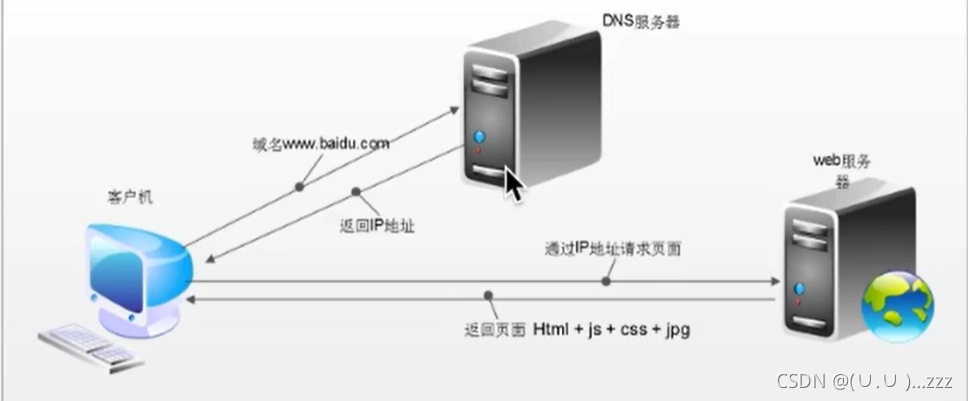
- 爬虫 : 只会请求url地址
- 浏览器:发送请求+进行渲染