实验一: 只是单纯地添加了, e_e公式的部分, 没有dropout, 没有加层. (只跑到epoch30, 在普通笔记本上)
结果:两个模型是可比的
- GCN: loss表现更好
- NGCF: 在度量指标HR, ndcg上表现更好
- (因为是在自己的电脑上跑的, 所以听到NGCF运行的时候声音更大, 风扇和硬盘读写啊, 感觉自己的心在滴血......我还是很爱惜自己的笔记本的)
GCN:

NGCF:

实验二: GCN 对比 GCN+e_e
结果: ...总体来说结果还是可比的
损失函数: 34623:30574
HR: 0.7238:0.7267
NDCG: 0.4694:0.4736
-
GCN:
-
实验设置

- 第0个epoch:

- 第20个epoch:

- 第40个epoch:

- 第60个epoch:
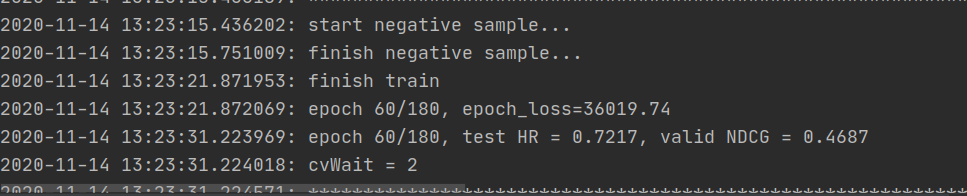
- 第63个epoch提前终止:

34623.57
0.7238
0.4694
-
NGCF: + e_e:
-
开始:

-
第0个epoch:

-
第10个epoch:

-
第20个epoch:

-
第30个epoch:

-
第40个epoch:

-
第50个epoch:

-
终止epoch:

实验三: 加层数: 三层VS一层 (在GCN的基础上加了e_e)
-
实验结果:
-
最明显的一点: 层数增加了, 模型收敛的速度也变慢了:原本是50~60个epoch就可以收敛, 但是现在增加到 91 个epoch才停止

-
就度量结果而言是"不升反降!!!!!!!"
-
损失函数: 19959:30574 (TODO: 是不是epoch不一样, 就不可比)
HR: 0.7174:0.7267
NDCG: 0.4662:0.4736
- 开始:
 第0个epoch:
第0个epoch:
- 第10个epoch:

- 第20个epoch:

- 第30个epoch:

- 第40个epoch:

- 第50个epoch:

- 第60个epoch:

- 第70个epoch:

- 第80个epoch:

- 第90个epoch:

- 结束epoch:

实验四: 加node_dropout: 有VS无
TODO: 理解node_dropout是什么东西??????感觉让原来的矩阵更稀疏了
实验结果: 不升反降
损失函数: 20508.25:19959.09
HR: 0.7047: 0.7174
NDCG: 0.4689 : 0.4662
- 开始:

- 第0个epoch:

- 第10个epoch:

- 第20个epoch:

- 第30个epoch:

- 第40个epoch:

- 第50个epoch:
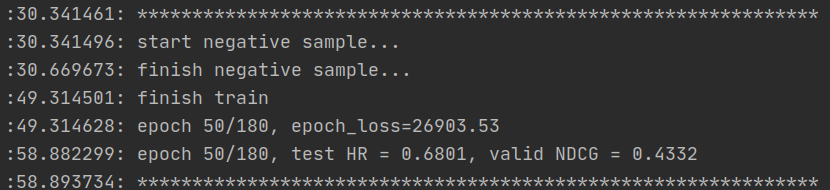
- 第60个epoch:

- 第70个epoch:
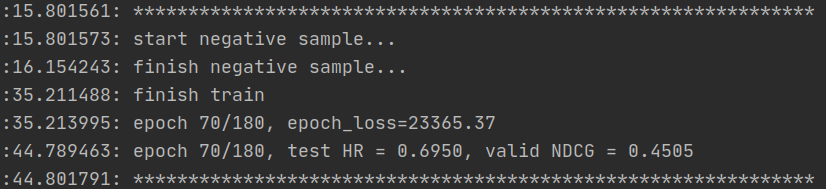
- 第80个epoch:
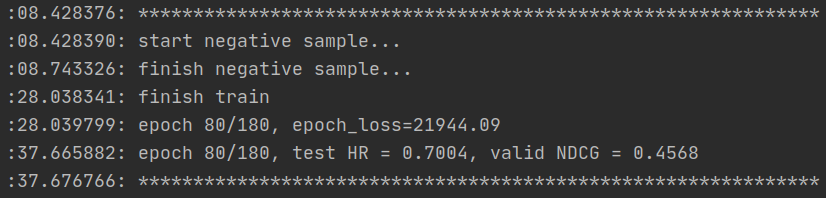
- 第90个epoch:
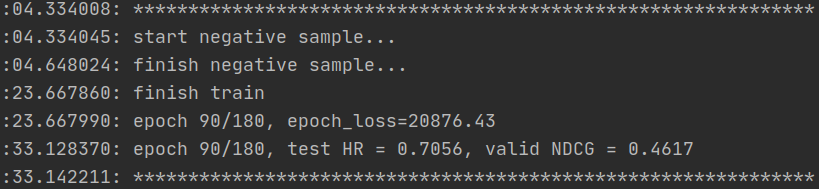
- 最后epoch:

20508.25
0.7047
0.4689
实验五: 加message_dropout 有VS无
实验结果: 还是可比的 (个人任务可能是因为任务不同, 再看损失函数和CF任务的关系)
损失函数: 22586.43 : 20508.25
HR: 0.7090 : 0.7047
ndcg: 0.4634 : 0.4689
- 开始:

- 第0个epoch:

- 第10个epoch:

- 第20个epoch:

- 第30个epoch:

- 第40个epoch:

- 第50个epoch:

- 第60个epoch:

- 第70个epoch:

- 第80个epoch:

- 第90个epoch:

- 第100个epoch:

- 第110个epoch:

- 最后epoch:

22586.43
0.7090
0.4634
实验六: embedding_size的影响
embedding_size==16:
实验结果:
最后一个训练loss: 15595.49
HR: 0.7241
ndcg: 0.4724
- 开始epoch:

- 第0个epoch:

- 第10个epoch:

- 第20个epoch:

- 第30个epoch:

15595.49
0.7241
0.4724
embedding_size==32:
- 开始epoch:

- 第0个epoch:

- 第10个epoch:

- 结束epoch:

10429.84
0.7343
0.4844
embedding_size==64:
实验结果:
6805.64
0.7378
0.4873
- 开始epoch:

- 第0个epoch:

- 第10个epoch:

- 结束epoch:

6805.64
0.7378
0.4873
embedding_size==96:
实验结果: 总体来说和64个epoch是可比的
loss: 5442.47
HR: 0.7362
ndcg: 0.4880
- 开始epoch:

- 第0个epoch:

- 第10个epoch:

- 最后epoch:

5442.47
0.7362
0.4880
embedding_size==132:
实验结果:
明显感觉到训练一个epoch的时间变长了
- 开始epoch:

- 第0个epoch:

- 最后epoch:

实验七: GCN去掉参数, 去掉损失函数, 改LightGCN
实验结果: 比embedding-size之前的魔改要好, 但是比原本的GCN要差
最后一个train loss: 22453.94
HR: 0.7177
NDCG: 0.4722
- 画图:

- 开始epoch:

- 第0个epoch:

- 第10个epoch:

- 第20个epoch:
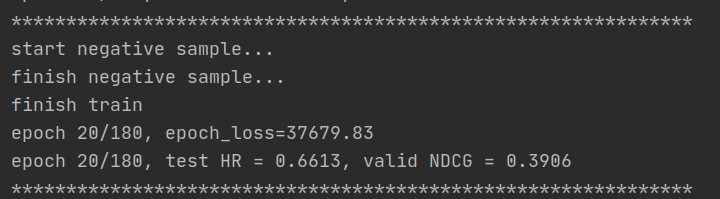
- 第30个epoch:

- 第40个epoch:

- 第50个epoch:
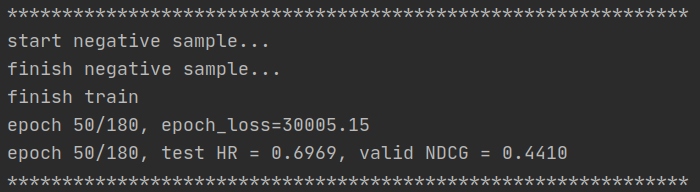
- 第60个epoch:
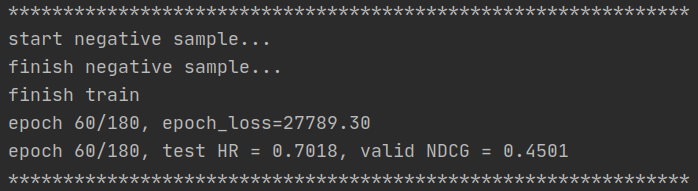
- 第70个epoch:

- 第80个epoch:

- 第90个epoch:

- 第100个epoch:

- 最后epoch:

22453.94
0.7177
0.4722
实验八: 上一个LightGCN的基础上: embedding_size:64
实验结果:取得了目前为止所有模型最好的效果
- 开始epoch:

- 第0个epoch:

- 第10个epoch:

- 最后epoch:

7214.93
0.7359
0.5002
增补实验:将最初的GCN模型: 1.设置为3层, 2.将embedding_size由4改为64
实验结果: 和最好的LightGCN HR可比, ndcg差了
- 最后epoch:

7643.53
0.7355
0.4905
增补实验:将最初的GCN模型: 1.还原为1层(初始设置), 2.将embedding_size由4改为64
实验结果: 和上面的结果对比, 层数层加结果会明显变好

9436.05
0.7297
0.4758
(以下为最初始的GCN没有任何改动: 层数为一, embedding_size为4)
实验结果: 目前看embedding_size的大小设置 对结果的影响还是比较大, 一个可能的原因是两次的embedding_size的大小相差太大了
34623.57
0.7238
0.4694