
FcaNet: Frequency Channel Attention Networks
paper:http://arxiv.org/abs/2012.11879
code:https://github.com/dcdcvgroup/FcaNet
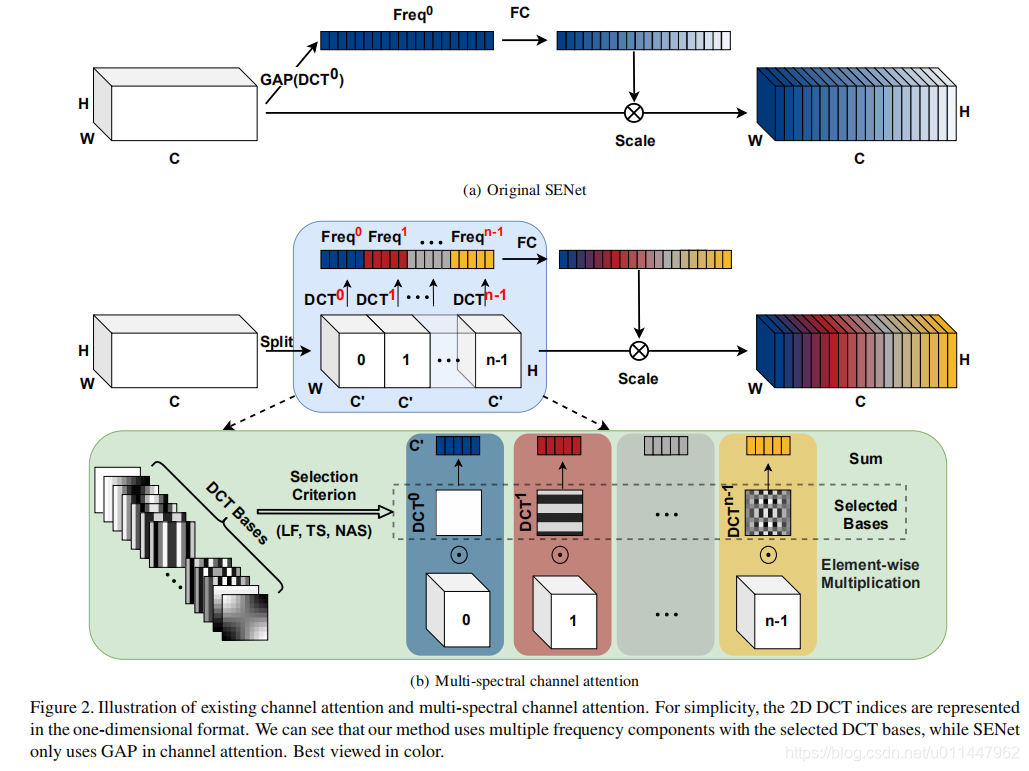
这篇论文,将GAP推广到一种更为一般的2维的离散余弦变换(DCT)形式,通过引入更多的frequency analysis重新考虑通道的注意力。
摘要
注意机制,特别是通道注意,在计算机视觉领域取得了巨大的成功。许多工作集中在如何设计有效的通道注意机制,而忽略了一个基本问题,即通道注意机制使用标量来表示通道,这由于大量信息损失而困难。在这项工作中,从一个不同的观点开始,并将特征通道表示问题视为一个使用频率分析的压缩过程。在频率分析的基础上,用数学方法证明了传统的全局平均池化是频域特征分解的一种特例。在此基础上,自然地推广了频域通道注意机制的压缩问题,并提出了具有多频谱信道注意特性的方法,称为FcaNet。FcaNet很简单,但也很有效。可以在计算中的几行代码实现该方法。此外,与其他通道注意方法相比,该方法在图像分类、目标检测和实例se等方面都取得了最先进的效果。
论文主要思想
作者认为在通道注意力里的GAP抑制了通道之间的多样性,且GAP本质是离散余弦变换(DCT)的最低分频。若从频域角度分析,可以使用更多有用的其它分量,从而形成一个多谱通道注意力(Multi-Spectral Channel Attention)。重要的是文中设计了一种启发式的两步准则来选择多谱注意力模块的频率分量,其主要思想是先得到每个频率分量的重要性再确定不同数目频率分量的效果。具体而言,先分别计算通道注意力中采用各个频率分量的结果,然后,根据结果少选出topk个性能最好的分量。
Keras实现
以下是根据论文和pytorch源码实现的keras版本(支持Tensorflow1.x)。
def fca(inputs, name, ratio=8):
w, h, out_dim = [int(x) for x in inputs.shape[1:]]
temp_dim = max(out_dim // ratio, ratio)
pool = MultiSpectralAttentionLayer(out_dim, h, w)(inputs)
excitation = Dense(temp_dim, activation='relu', use_bias=False, name=name + '_Dense_1')(pool)
excitation = Dense(out_dim, activation='sigmoid', use_bias=False,name=name + '_Dense_2')(excitation)
excitation = Reshape((1, 1, out_dim), name=name + '_Reshape')(excitation)
excitation = Multiply(name=name + '_Multiply')([inputs, excitation])
return excitationimport math
import tensorflow as tf
from keras.layers import Layer
import numpy as np
def get_freq_indices(method):
assert method in ['top1', 'top2', 'top4', 'top8', 'top16', 'top32',
'bot1', 'bot2', 'bot4', 'bot8', 'bot16', 'bot32',
'low1', 'low2', 'low4', 'low8', 'low16', 'low32']
num_freq = int(method[3:])
if 'top' in method:
all_top_indices_x = [0, 0, 6, 0, 0, 1, 1, 4, 5, 1, 3, 0, 0, 0, 3, 2, 4, 6, 3, 5, 5, 2, 6, 5, 5, 3, 3, 4, 2, 2,
6, 1]
all_top_indices_y = [0, 1, 0, 5, 2, 0, 2, 0, 0, 6, 0, 4, 6, 3, 5, 2, 6, 3, 3, 3, 5, 1, 1, 2, 4, 2, 1, 1, 3, 0,
5, 3]
mapper_x = all_top_indices_x[:num_freq]
mapper_y = all_top_indices_y[:num_freq]
elif 'low' in method:
all_low_indices_x = [0, 0, 1, 1, 0, 2, 2, 1, 2, 0, 3, 4, 0, 1, 3, 0, 1, 2, 3, 4, 5, 0, 1, 2, 3, 4, 5, 6, 1, 2,
3, 4]
all_low_indices_y = [0, 1, 0, 1, 2, 0, 1, 2, 2, 3, 0, 0, 4, 3, 1, 5, 4, 3, 2, 1, 0, 6, 5, 4, 3, 2, 1, 0, 6, 5,
4, 3]
mapper_x = all_low_indices_x[:num_freq]
mapper_y = all_low_indices_y[:num_freq]
elif 'bot' in method:
all_bot_indices_x = [6, 1, 3, 3, 2, 4, 1, 2, 4, 4, 5, 1, 4, 6, 2, 5, 6, 1, 6, 2, 2, 4, 3, 3, 5, 5, 6, 2, 5, 5,
3, 6]
all_bot_indices_y = [6, 4, 4, 6, 6, 3, 1, 4, 4, 5, 6, 5, 2, 2, 5, 1, 4, 3, 5, 0, 3, 1, 1, 2, 4, 2, 1, 1, 5, 3,
3, 3]
mapper_x = all_bot_indices_x[:num_freq]
mapper_y = all_bot_indices_y[:num_freq]
else:
raise NotImplementedError
return mapper_x, mapper_y
class MultiSpectralAttentionLayer(Layer):
def __init__(self, channel, dct_h, dct_w, reduction=16, freq_sel_method='top16'):
super(MultiSpectralAttentionLayer, self).__init__()
self.reduction = reduction
self.dct_h = dct_h
self.dct_w = dct_w
mapper_x, mapper_y = get_freq_indices(freq_sel_method)
self.num_split = len(mapper_x)
mapper_x = [temp_x * (dct_h // 7) for temp_x in mapper_x]
mapper_y = [temp_y * (dct_w // 7) for temp_y in mapper_y]
# make the frequencies in different sizes are identical to a 7x7 frequency space
# eg, (2,2) in 14x14 is identical to (1,1) in 7x7
assert len(mapper_x) == len(mapper_y)
assert channel % len(mapper_x) == 0
self.num_freq = len(mapper_x)
# fixed DCT init
self.weight = self.get_dct_filter(dct_h, dct_w, mapper_x, mapper_y, channel).transpose([2, 1, 0])
def call(self, x):
x = x * self.weight
result = tf.reduce_sum(x, axis=[1, 2])
return result
def compute_output_shape(self, input_shape):
return (input_shape[0], input_shape[-1])
def build_filter(self, pos, freq, POS):
result = math.cos(math.pi * freq * (pos + 0.5) / POS) / math.sqrt(POS)
if freq == 0:
return result
else:
return result * math.sqrt(2)
def get_dct_filter(self, tile_size_x, tile_size_y, mapper_x, mapper_y, channel):
dct_filter = np.zeros((channel, tile_size_x, tile_size_y))
c_part = channel // len(mapper_x)
for i, (u_x, v_y) in enumerate(zip(mapper_x, mapper_y)):
for t_x in range(tile_size_x):
for t_y in range(tile_size_y):
dct_filter[i * c_part: (i + 1) * c_part, t_x, t_y] = self.build_filter(t_x, u_x,
tile_size_x) * self.build_filter(
t_y, v_y, tile_size_y)
return dct_filter
声明:本内容来源网络,版权属于原作者,图片来源原论文。如有侵权,联系删除。
创作不易,欢迎大家点赞评论收藏关注!(想看更多最新的注意力机制文献欢迎关注浏览我的博客)